Approximate entropy
In statistics, an approximate entropy (ApEn) is a technique used to quantify the amount of regularity and the unpredictability of fluctuations over time-series data.[1]
For example, there are two series of data:
- series 1: (10,20,10,20,10,20,10,20,10,20,10,20...), which alternates 10 and 20.
- series 2: (10,10,20,10,20,20,20,10,10,20,10,20,20...), which has either a value of 10 or 20, chosen randomly, each with probability 1/2.
Moment statistics, such as mean and variance, will not distinguish between these two series. Nor will rank order statistics distinguish between these series. Yet series 1 is "perfectly regular"; knowing one term has the value of 20 enables one to predict with certainty that the next term will have the value of 10. Series 2 is randomly valued; knowing one term has the value of 20 gives no insight into what value the next term will have.
Regularity was originally measured by exact regularity statistics, which has mainly centered on various entropy measures.[1] However, accurate entropy calculation requires vast amounts of data, and the results will be greatly influenced by system noise,[2] therefore it is not practical to apply these methods to experimental data. ApEn was developed by Steve M. Pincus to handle these limitations by modifying an exact regularity statistic, Kolmogorov–Sinai entropy. ApEn was initially developed to analyze medical data, such as heart rate,[1] and later spread its applications in finance,[3] physiology,[4] human factors engineering,[5] and climate sciences.[6]
The algorithm
A comprehensive step-by-step tutorial with an explanation of the theoretical foundations of Approximate Entropy is available at:[7]
- Step 1
- Form a time series of data . These are N raw data values from measurement equally spaced in time.
- Step 2
- Fix m, an integer, and r, a positive real number. The value of m represents the length of compared run of data, and r specifies a filtering level.
- Step 3
- Form a sequence of vectors ,, in , real -dimensional space defined by .
- Step 4
- Use the sequence , to construct, for each I,
- in which is defined as
- The are the m scalar components of . d represents the distance between the vectors and , given by the maximum difference in their respective scalar components. Note that takes on all values, so the match provided when will be counted (the subsequence is matched against itself).
- Step 5
- Define
- ,
- Step 6
- Define approximate entropy as
- where is the natural logarithm, for m and r fixed as in Step 2.
- Parameter selection
- typically choose or , and r depends greatly on the application.






















An implementation on Physionet,[8] which is based on Pincus [2] use whereas the original article uses in Step 4. While a concern for artificially constructed examples, it is usually not a concern in practice.


The interpretation
The presence of repetitive patterns of fluctuation in a time series renders it more predictable than a time series in which such patterns are absent. ApEn reflects the likelihood that similar patterns of observations will not be followed by additional similar observations.[9] A time series containing many repetitive patterns has a relatively small ApEn; a less predictable process has a higher ApEn.
One example
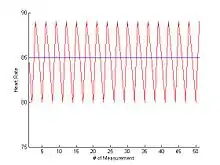
Suppose , and the sequence consists of 51 samples of heart rate equally spaced in time:


(i.e., the sequence is periodic with a period of 3). Let's choose and (the values of and can be varied without affecting the result).



Form a sequence of vectors:
- …




Distance is calculated as follows:

Note , so


Similarly,


Therefore, such that include , and the total number is 17.







Please note in Step 4, for , . So the such that include , and the total number is 16.




Then we repeat the above steps for m=3. First form a sequence of vectors:
- …




By calculating distances between vector , we find the vectors satisfying the filtering level have the following characteristic:


Therefore,





Finally,

The value is very small, so it implies the sequence is regular and predictable, which is consistent with the observation.
Python implementation
import numpy as np
def ApEn(U, m, r) -> float:
"""Approximate_entropy."""
def _maxdist(x_i, x_j):
return max([abs(ua - va) for ua, va in zip(x_i, x_j)])
def _phi(m):
x = [[U[j] for j in range(i, i + m - 1 + 1)] for i in range(N - m + 1)]
C = [
len([1 for x_j in x if _maxdist(x_i, x_j) <= r]) / (N - m + 1.0)
for x_i in x
]
return (N - m + 1.0) ** (-1) * sum(np.log(C))
N = len(U)
return abs(_phi(m + 1) - _phi(m))
# Usage example
U = np.array([85, 80, 89] * 17)
print(ApEn(U, 2, 3))
1.0996541105257052e-05
randU = np.random.choice([85, 80, 89], size=17 * 3)
print(ApEn(randU, 2, 3))
0.8626664154888908
Advantages
The advantages of ApEn include:[2]
- Lower computational demand. ApEn can be designed to work for small data samples (n < 50 points) and can be applied in real time.
- Less effect from noise. If data are noisy, the ApEn measure can be compared to the noise level in the data to determine what quality of true information may be present in the data.
Applications
ApEn has been applied to classify EEG in psychiatric diseases, such as schizophrenia,[10] epilepsy,[11] and addiction.[12]
Limitations
The ApEn algorithm counts each sequence as matching itself to avoid the occurrence of ln(0) in the calculations. This step might cause bias of ApEn and this bias causes ApEn to have two poor properties in practice:[13]
- ApEn is heavily dependent on the record length and is uniformly lower than expected for short records.
- It lacks relative consistency. That is, if ApEn of one data set is higher than that of another, it should, but does not, remain higher for all conditions tested.
References
- Pincus, S. M.; Gladstone, I. M.; Ehrenkranz, R. A. (1991). "A regularity statistic for medical data analysis". Journal of Clinical Monitoring and Computing. 7 (4): 335–345. doi:10.1007/BF01619355. PMID 1744678.
- Pincus, S. M. (1991). "Approximate entropy as a measure of system complexity". Proceedings of the National Academy of Sciences. 88 (6): 2297–2301. doi:10.1073/pnas.88.6.2297. PMC 51218. PMID 11607165.
- Pincus, S.M.; Kalman, E.K. (2004). "Irregularity, volatility, risk, and financial market time series". Proceedings of the National Academy of Sciences. 101 (38): 13709–13714. doi:10.1073/pnas.0405168101. PMC 518821. PMID 15358860.
- Pincus, S.M.; Goldberger, A.L. (1994). "Physiological time-series analysis: what does regularity quantify?". The American Journal of Physiology. 266 (4): 1643–1656. doi:10.1152/ajpheart.1994.266.4.H1643. PMID 8184944. S2CID 362684.
- McKinley, R.A.; McIntire, L.K.; Schmidt, R; Repperger, D.W.; Caldwell, J.A. (2011). "Evaluation of Eye Metrics as a Detector of Fatigue". Human Factors. 53 (4): 403–414. doi:10.1177/0018720811411297. PMID 21901937.
- Delgado-Bonal, Alfonso; Marshak, Alexander; Yang, Yuekui; Holdaway, Daniel (2020-01-22). "Analyzing changes in the complexity of climate in the last four decades using MERRA-2 radiation data". Scientific Reports. 10 (1): 922. doi:10.1038/s41598-020-57917-8. ISSN 2045-2322.
- Delgado-Bonal, Alfonso; Marshak, Alexander (June 2019). "Approximate Entropy and Sample Entropy: A Comprehensive Tutorial". Entropy. 21 (6): 541. doi:10.3390/e21060541.
- Ho, K. K.; Moody, G. B.; Peng, C.K.; Mietus, J. E.; Larson, M. G.; levy, D; Goldberger, A. L. (1997). "Predicting survival in heart failure case and control subjects by use of fully automated methods for deriving nonlinear and conventional indices of heart rate dynamics". Circulation. 96 (3): 842–848. doi:10.1161/01.cir.96.3.842. PMID 9264491.
- Sabeti, Malihe (2009). "Entropy and complexity measures for EEG signal classification of schizophrenic and control participants". Artificial Intelligence in Medicine. 47 (3): 263–274. doi:10.1016/j.artmed.2009.03.003. PMID 19403281.
- Yuan, Qi (2011). "Epileptic EEG classification based on extreme learning machine and nonlinear features". Epilepsy Research. 96 (1–2): 29–38. doi:10.1016/j.eplepsyres.2011.04.013. PMID 21616643.
- Yun, Kyongsik (2012). "Decreased cortical complexity in methamphetamine abusers". Psychiatry Research: Neuroimaging. 201 (3): 226–32. doi:10.1016/j.pscychresns.2011.07.009. PMID 22445216.
- Richman, J.S.; Moorman, J.R. (2000). "Physiological time-series analysis using approximate entropy and sample entropy". American Journal of Physiology. Heart and Circulatory Physiology. 278 (6): 2039–2049. doi:10.1152/ajpheart.2000.278.6.H2039. PMID 10843903.