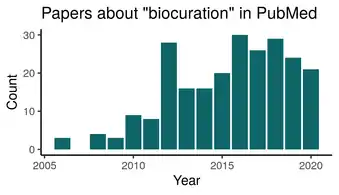
Biocuration
Biocuration is the field of life sciences research dedicated to translating and integrating biomedical knowledge from scientific articles to interoperable databases.[1][2] The biocuration of biomedical knowledge is made possible by the cooperative work of biocurators, software developers and bioinformaticians.[1]
Biocuration as a profession
A biocurator is a professional scientist who curates, collects, annotates, and validates information that is disseminated by biological and model organism databases.[3][4] It is a new profession, with the first mention in the scientific literature dating of 2006.[5][6] The role of a biocurator encompasses quality control of primary biological research data intended for publication, extracting and organizing data from original scientific literature, and describing the data with standard annotation protocols and vocabularies that enable powerful queries and biological database interoperability. Biocurators communicate with researchers to ensure the accuracy of curated information and to foster data exchanges with research laboratories.[6]
Biocurators are present in diverse research environments, but may not self-identify as biocurators. Projects such as ELIXIR (the European life-sciences Infrastructure for biological Information) and GOBLET Global Organization for Bioinformatics Learning, Education and Training)[7]promote training and support biocuration as a career path. [8]
In 2011, biocuration was already recognized as a profession, but there were no formal degree courses to prepare curators for biological data in a targeted fashion.[9] With the growth of the field, the University of Cambrigdge and the EMBL-EBI started to jointly offer a Postgraduate Certificate in Biocuration,[10] considered as a step towards recognising biocuration as a discipline on its own.[11]
Curation and annotation
Biocuration is the integration of biological information into on-line databases in a semantically standardized way, using appropriate unique traceable identifiers, and providing necessary metadata including source and provenance.
Ontologies, controlled vocabularies and standard names
Biocurators commonly employ and take part in the creation and development of shared biomedical ontologies: structured, controlled vocabularies that encompass many biological and medical knowledge domains, such as the Open Biomedical Ontologies. These domains include genomics and proteomics, anatomy, animal and plant development, biochemistry, metabolic pathways, taxonomic classification, and mutant phenotypes. Given the variety of existing ontologies, there are guidelines that orient researchers on how to choose a suitable one.[12]
The Unified Medical Language System is one such systems that integrates and distributes millions of terms used in the life sciences domain.[13]
Biocurators enforce the consistent use of gene nomenclature guidelines and participate in the genetic nomenclature committees of various model organisms, often in collaboration with the HUGO Gene Nomenclature Committee (HGNC). They also enforce other nomenclature guidelines like those provided by the Nomenclature Committee of the International Union of Biochemistry and Molecular Biology (IUBMB), one example of which is the Enzyme Commission EC number.
More generally, the use of persistent identifiers is praised by the community, so to improve clarity and facilitate knowledge [14]
Entity annotation
In genome annotation for example, the identifiers defined by the ontologists and consortia are used to describe parts of the genome. For example, the gene ontology (GO) curates terms for biological processes, which are used to describe what we know about specific genes.
Text annotation
Besides annotating biological sequences, biocurators also annotate texts, linking words to unique identifiers. This aids in disambiguation, clarifying the meaning intended, and making the texts processable by computers. One application of text annotation is to specify the exact gene a scientist is referring to.[15]
Publicly available text annotations make it possible to biologists to take further advantage of biomedical text. The Europe PMC has an Application Programming Interface which centralizes text annotations from a variety of sources and make them available in a Graphic User Interface called SciLite.[16] The PubTator Central also provides annotations, but is fully based on computerized text-mining and does not provide a user interface.[17]
There are also programs that allow users to manually annotate the biomedical texts they are interested, such as the ezTag system.[18]
International Society for Biocuration (ISB)
The International Society for Biocuration (ISB) is a non-profit organisation "promotes the field of biocuration and provides a forum for information exchange through meetings and workshops." It has grown from the International Biocuration Conferences and founded in early 2009.[4]
The ISB offers the Biocuration Career Award to biocurators in the community: the Biocurator Career Award (given annually) and the ISB Award for Exceptional Contributions to Biocuration (given biannually).
Biocuration in Wikimedia
Wikipedia
There is some overlap between the work of biocurators and Wikipedia, with boundaries between scientific databases and Wikipedia becoming increasingly blurred.[19][20][21] Databases like Rfam[22][23] and the Protein Data Bank[24] for example make heavy use of Wikipedia and its editors to curate information.[25][26] However, most databases offer highly structured data that is searchable in complex combinations, which is usually not possible on Wikipedia, although Wikidata aims at solving this problem to some extent.
The Gene Wiki project used Wikipedia for collaborative curation of thousands of genes and gene products, such as titin and insulin.[27] Several projects also employ Wikipedia as a platform for curation of medical information. [28]
Wikidata
The Wikimedia knowledge base Wikidata is increasingly being used by the biocuration community as an integrative repository across life sciences.[29] For example, it has been used by the Gene Wiki project to curate information about genes. [30] Some projects use curation via Wikidata as a way to improve life-sciences information on Wikipedia, for example. [31]
Community curation
Traditionally, biocuration has been done by dedicated experts, which integrate data into databases. Community curation has emerged as a promising approach to improve the dissemination of knowledge from published data and provide a cost-effective way to improve the scalability of biocuration.
Biological databases
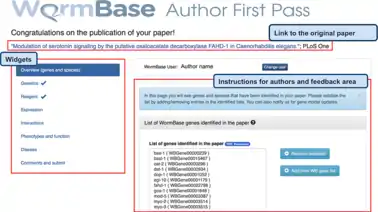
Several biological databases include author contributions in their functional curation strategy to some extent, which may range from associating gene identifiers with publications or free-text, to more structured and detailed annotation of sequences and functional data, outputting curation to the same standards as professional biocurators. Most community curation at Model Organism Databases involves annotation by original authors of published research (first-pass annotation) to effectively obtain accurate identifiers for objects to be curated, or identify data-types for detailed curation. For example:
- WormBase successfully solicits first-pass annotation from users and has integrated author curation with the micropublication process.[33] WormBase also integrates text-mining to its platform, providing suggestions to community curators.[32]
- FlyBase sends email requests to authors of new publications,[34] inviting them to list the genes and data types described via an online tool and has also mobilized the community to write gene summary paragraphs.[35]
Other databases, such as PomBase, rely on publication authors to submit highly detailed, ontology-based annotations for their publications, and meta-data associated with genome-wide data-sets using controlled vocabularies. A web-based tool Canto;[36] was developed to facilitate community submissions. Since Canto is freely available, generic and highly configurable, it has been adopted by other projects.[37] Curation is subjected to review by professional curators resulting in high quality in-depth curation of all molecular data-types.[38]
The widely used UniProt knowledgebase has also a community curation mechanism that allows researchers to add information about proteins.[39]
Wiki-style resources
Bio-wikis rely on their communities to provide content. AuthorReward,[40] for example, is an extension to MediaWiki that quantifies researchers' contributions to biowikis. RiceWiki was an example of a wiki-based database for community curation of rice genes equipped with AuthorReward.[41][42]
One notable example is WikiProteins/WikiProfessional, a project to semantically organize biological data led by Barend Mons.[43][44] The 2007 project had direct contributions of Jimmy Wales, Wikipedia co-founder, and took Wikidata as an inspiration.[43] Another one is WikiPathways, which crowdsources information about biological pathways.[45]
Gamified resources
An approach to involve the crowd in biocuration is via gamified platforms that use game design principles to boost engagement. A few examples are:
Computational text mining for curation
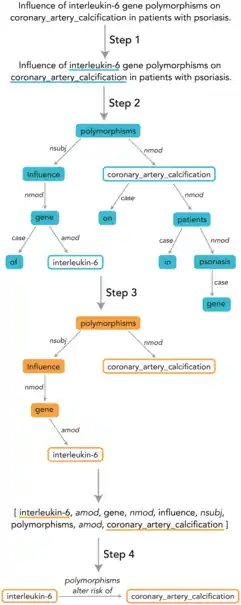
Natural-language processing and text mining technologies can help biocurators to extract of information for manual curation.[52] Text mining can scale curation efforts, supporting the identification of gene names, for example, as well as for partially inferring ontologies.[53] The conversion of unstructured assertions to structured information makes use of techniques like named entity recognition and parsing of dependencies.[54] Text-mining of biomedical concepts faces challenges regarding variations in reporting, and the community is working to increase the machine-readability of articles.[55]
During the COVID-19 pandemic, biomedical text mining was heavily used to cope with the large amount of published scientific research about the topic (over 50.000 articles). [56]
The popular NLP python package SpaCy has a modification for biomedical texts, SciSpaCy, which is maintained by the Allen Institute for AI.[57]
Among the challenges for text-mining applied to biocuration is the difficulty of accessing full texts of biomedical articles due to pay wall, linking the challenges of biocuration to those of the open-access movement.[58]
A complementary approach to biocuration via text mining involves applying optical character recognition to biomedical figures, coupled to automatic annotation algorithms. This has been used to extract gene information from pathway figures, for example.[59]
Biocreative challenges
The interface between text-mining and biocuration has been propelled up by the BioCreAtIvE (Critical Assessment of Information Extraction systems in Biology) challenges, a series of text-mining competitions that occurred for the first time in 2004.[60]
References
- "What is biocuration? | International Society for Biocuration". www.biocuration.org. Retrieved 2020-09-06.
- Howe D, Costanzo M, Fey P, Gojobori T, Hannick L, Hide W, et al. (September 2008). "Big data: The future of biocuration". Nature. 455 (7209): 47–50. Bibcode:2008Natur.455...47H. doi:10.1038/455047a. PMC 2819144. PMID 18769432.
- Burge S, Attwood TK, Bateman A, Berardini TZ, Cherry M, O'Donovan C, et al. (2012-03-20). "Biocurators and biocuration: surveying the 21st century challenges". Database. 2012: bar059. doi:10.1093/database/bar059. PMC 3308150. PMID 22434828.
- Bateman A (April 2010). "Curators of the world unite: the International Society of Biocuration". Bioinformatics. 26 (8): 991. doi:10.1093/bioinformatics/btq101. PMID 20305270.
- Bourne PE, McEntyre J (October 2006). "Biocurators: contributors to the world of science". PLOS Computational Biology. 2 (10): e142. Bibcode:2006PLSCB...2..142B. doi:10.1371/journal.pcbi.0020142. PMC 1626157. PMID 17411327.
- Salimi N, Vita R (October 2006). "The biocurator: connecting and enhancing scientific data". PLOS Computational Biology. 2 (10): e125. Bibcode:2006PLSCB...2..125S. doi:10.1371/journal.pcbi.0020125. PMC 1626147. PMID 17069454.
- "GOBLET | The Global Organisation for Bioinformatics Learning, Education & Training". Retrieved 2020-12-19.
- Alexandra Holinski; Melissa Burke; Sarah L Morgan; Peter McQuilton; Patricia M. Palagi (4 September 2020). "Biocuration - mapping resources and needs". F1000Research. 9. doi:10.12688/F1000RESEARCH.25413.1. ISSN 2046-1402. PMID 33145007. Wikidata Q101217428.
- Sanderson, Katharine (February 2011). "Bioinformatics: Curation generation". Nature. 470 (7333): 295–296. doi:10.1038/nj7333-295a. ISSN 1476-4687. PMID 21348148.
- Anonymous (2019-10-30). "Postgraduate Certificate in Biocuration". www.ice.cam.ac.uk. Retrieved 2020-10-06.
- Tang YA, Pichler K, Füllgrabe A, Lomax J, Malone J, Munoz-Torres MC, et al. (May 2019). "Ten quick tips for biocuration". PLOS Computational Biology. 15 (5): e1006906. Bibcode:2019PLSCB..15E6906T. doi:10.1371/journal.pcbi.1006906. PMC 6497217. PMID 31048830.
- Malone J, Stevens R, Jupp S, Hancocks T, Parkinson H, Brooksbank C (February 2016). "Ten Simple Rules for Selecting a Bio-ontology". PLOS Computational Biology. 12 (2): e1004743. Bibcode:2016PLSCB..12E4743M. doi:10.1371/journal.pcbi.1004743. PMC 4750991. PMID 26867217.
- Bodenreider O (January 2004). "The Unified Medical Language System (UMLS): integrating biomedical terminology". Nucleic Acids Research. 32 (Database issue): D267-70. doi:10.1093/nar/gkh061. PMC 308795. PMID 14681409.
- McMurry JA, Juty N, Blomberg N, Burdett T, Conlin T, Conte N, et al. (June 2017). "Identifiers for the 21st century: How to design, provision, and reuse persistent identifiers to maximize utility and impact of life science data". PLOS Biology. 15 (6): e2001414. doi:10.1371/journal.pbio.2001414. PMC 5490878. PMID 28662064.
- Mons B (June 2005). "Which gene did you mean?". BMC Bioinformatics. 6 (1): 142. doi:10.1186/1471-2105-6-142. PMC 1173089. PMID 15941477.
- Venkatesan A, Kim JH, Talo F, Ide-Smith M, Gobeill J, Carter J, et al. (2016-12-12). "SciLite: a platform for displaying text-mined annotations as a means to link research articles with biological data". Wellcome Open Research. 1: 25. doi:10.12688/wellcomeopenres.10210.1. PMC 5527546. PMID 28948232.
- Wei CH, Allot A, Leaman R, Lu Z (July 2019). "PubTator central: automated concept annotation for biomedical full text articles". Nucleic Acids Research. 47 (W1): W587–W593. doi:10.1093/nar/gkz389. PMC 6602571. PMID 31114887.
- Kwon D, Kim S, Wei CH, Leaman R, Lu Z (July 2018). "ezTag: tagging biomedical concepts via interactive learning". Nucleic Acids Research. 46 (W1): W523–W529. doi:10.1093/nar/gky428. PMC 6030907. PMID 29788413.
- Wodak SJ, Mietchen D, Collings AM, Russell RB, Bourne PE (2012). "Topic pages: PLOS Computational Biology meets Wikipedia". PLOS Computational Biology. 8 (3): e1002446. Bibcode:2012PLSCB...8E2446W. doi:10.1371/journal.pcbi.1002446. PMC 3315447. PMID 22479174.
- Finn RD, Gardner PP, Bateman A (January 2012). "Making your database available through Wikipedia: the pros and cons". Nucleic Acids Research. 40 (Database issue): D9-12. doi:10.1093/nar/gkr1195. PMC 3245093. PMID 22144683.
- Page RD (March 2011). "Linking NCBI to Wikipedia: a wiki-based approach". PLOS Currents. 3: RRN1228. doi:10.1371/currents.RRN1228. PMC 3080707. PMID 21516242.
- Gardner PP, Daub J, Tate J, Moore BL, Osuch IH, Griffiths-Jones S, et al. (January 2011). "Rfam: Wikipedia, clans and the "decimal" release". Nucleic Acids Research. 39 (Database issue): D141-5. doi:10.1093/nar/gkq1129. PMC 3013711. PMID 21062808.
- Daub J, Gardner PP, Tate J, Ramsköld D, Manske M, Scott WG, et al. (December 2008). "The RNA WikiProject: community annotation of RNA families". RNA. 14 (12): 2462–4. doi:10.1261/rna.1200508. PMC 2590952. PMID 18945806.
- Burkhardt K, Schneider B, Ory J (October 2006). "A biocurator perspective: annotation at the Research Collaboratory for Structural Bioinformatics Protein Data Bank". PLOS Computational Biology. 2 (10): e99. Bibcode:2006PLSCB...2...99B. doi:10.1371/journal.pcbi.0020099. PMC 1626146. PMID 17069453.
- Logan DW, Sandal M, Gardner PP, Manske M, Bateman A (September 2010). "Ten simple rules for editing Wikipedia". PLOS Computational Biology. 6 (9): e1000941. Bibcode:2010PLSCB...6E0941L. doi:10.1371/journal.pcbi.1000941. PMC 2947980. PMID 20941386.

- Butler D (2008). "Publish in Wikipedia or perish: Journal to require authors to post in the free online encyclopaedia". Nature. doi:10.1038/news.2008.1312.
- Huss JW, Lindenbaum P, Martone M, Roberts D, Pizarro A, Valafar F, et al. (January 2010). "The Gene Wiki: community intelligence applied to human gene annotation". Nucleic Acids Research. 38 (Database issue): D633-9. doi:10.1093/nar/gkp760. PMC 2808918. PMID 19755503.
- Denise A. Smith (18 February 2020). Stefano Triberti (ed.). "Situating Wikipedia as a health information resource in various contexts: A scoping review". PLOS ONE. 15 (2): e0228786. doi:10.1371/JOURNAL.PONE.0228786. ISSN 1932-6203. PMC 7028268. PMID 32069322. Wikidata Q85632863.
- Waagmeester A, Stupp G, Burgstaller-Muehlbacher S, Good BM, Griffith M, Griffith OL, et al. (March 2020). Rodgers P, Mungall C (eds.). "Wikidata as a knowledge graph for the life sciences". eLife. 9: e52614. doi:10.7554/eLife.52614. PMC 7077981. PMID 32180547. S2CID 212739087.
- Burgstaller-Muehlbacher S, Waagmeester A, Mitraka E, Turner J, Putman T, Leong J, et al. (2016). "Wikidata as a semantic framework for the Gene Wiki initiative". Database. 2016: baw015. doi:10.1093/database/baw015. PMC 4795929. PMID 26989148.
- Alexander Pfundner; Tobias Schönberg; John Horn; Richard D Boyce; Matthias Samwald (5 May 2015). "Utilizing the Wikidata system to improve the quality of medical content in Wikipedia in diverse languages: a pilot study". Journal of Medical Internet Research. 17 (5): e110. doi:10.2196/JMIR.4163. ISSN 1438-8871. PMC 4468594. PMID 25944105. Wikidata Q21503276.
- Arnaboldi V, Raciti D, Van Auken K, Chan JN, Müller HM, Sternberg PW (January 2020). "Text mining meets community curation: a newly designed curation platform to improve author experience and participation at WormBase". Database. 2020. doi:10.1093/database/baaa006. PMC 7078066. PMID 32185395. S2CID 212750405.
- Lee RY, Howe KL, Harris TW, Arnaboldi V, Cain S, Chan J, et al. (January 2018). "WormBase 2017: molting into a new stage". Nucleic Acids Research. 46 (D1): D869–D874. doi:10.1093/nar/gkx998. PMC 5753391. PMID 29069413.
- Bunt SM, Grumbling GB, Field HI, Marygold SJ, Brown NH, Millburn GH (2012). "Directly e-mailing authors of newly published papers encourages community curation". Database. 2012: bas024. doi:10.1093/database/bas024. PMC 3342516. PMID 22554788.
- Antonazzo G, Urbano JM, Marygold SJ, Millburn GH, Brown NH (January 2020). "Building a pipeline to solicit expert knowledge from the community to aid gene summary curation". Database. 2020. doi:10.1093/database/baz152. PMC 6971343. PMID 31960022.
- Rutherford KM, Harris MA, Lock A, Oliver SG, Wood V (June 2014). "Canto: an online tool for community literature curation". Bioinformatics. 30 (12): 1791–2. doi:10.1093/bioinformatics/btu103. PMC 4058955. PMID 24574118.
- "pombase/canto". PomBase. 25 September 2020.
- Lock A, Harris MA, Rutherford K, Hayles J, Wood V (January 2020). "Community curation in PomBase: enabling fission yeast experts to provide detailed, standardized, sharable annotation from research publications". Database. 2020. doi:10.1093/database/baaa028. PMC 7192550. PMID 32353878.
- "UniProt: the universal protein knowledgebase". Nucleic Acids Research. 45 (D1): D158–D169. 2016-11-29. doi:10.1093/nar/gkw1099. ISSN 0305-1048.
- Dai L, Tian M, Wu J, Xiao J, Wang X, Townsend JP, Zhang Z (July 2013). "AuthorReward: increasing community curation in biological knowledge wikis through automated authorship quantification". Bioinformatics. 29 (14): 1837–9. doi:10.1093/bioinformatics/btt284. PMC 3702255. PMID 23732274.
- Zhang Z, Sang J, Ma L, Wu G, Wu H, Huang D, et al. (January 2014). "RiceWiki: a wiki-based database for community curation of rice genes". Nucleic Acids Research. 42 (Database issue): D1222-8. doi:10.1093/nar/gkt926. PMC 3964990. PMID 24136999.
- "Os01g0883800 - RiceWiki". 2017-10-20. Archived from the original on 2017-10-20. Retrieved 2020-09-06.
- Mons B, Ashburner M, Chichester C, van Mulligen E, Weeber M, den Dunnen J, et al. (2008-05-28). "Calling on a million minds for community annotation in WikiProteins". Genome Biology. 9 (5): R89. doi:10.1186/gb-2008-9-5-r89. PMC 2441475. PMID 18507872.
- Giles J (February 2007). "Key biology databases go wiki". Nature. 445 (7129): 691. Bibcode:2007Natur.445..691G. doi:10.1038/445691a. PMID 17301755. S2CID 4410783.
- "WikiPathways - WikiPathways". www.wikipathways.org. Retrieved 2020-10-14.
- Tsueng G, Nanis SM, Fouquier J, Good BM, Su AI (2016-12-31). "Citizen Science for Mining the Biomedical Literature". Citizen Science. 1 (2): 14. doi:10.5334/cstp.56. PMC 6226017. PMID 30416754.
- Tsueng G, Nanis M, Fouquier JT, Mayers M, Good BM, Su AI (February 2020). "Applying citizen science to gene, drug and disease relationship extraction from biomedical abstracts". Bioinformatics. 36 (4): 1226–1233. doi:10.1093/bioinformatics/btz678. PMID 31504205.
- "Play Mark2Cure, help identify key terms in biomedical research abstracts". Citizen Science Games. Retrieved 2020-09-06.
- "Cochrane Crowd". crowd.cochrane.org. Retrieved 2020-09-25.
- Gartlehner G, Affengruber L, Titscher V, Noel-Storr A, Dooley G, Ballarini N, König F (May 2020). "Single-reviewer abstract screening missed 13 percent of relevant studies: a crowd-based, randomized controlled trial". Journal of Clinical Epidemiology. 121: 20–28. doi:10.1016/j.jclinepi.2020.01.005. PMID 31972274.
- Percha, Bethany; Altman, Russ B. (2018-08-01). "A global network of biomedical relationships derived from text". Bioinformatics. 34 (15): 2614–2624. doi:10.1093/bioinformatics/bty114. ISSN 1367-4803.
- Hirschman L, Burns GA, Krallinger M, Arighi C, Cohen KB, Valencia A, et al. (2012). "Text mining for the biocuration workflow". Database. 2012: bas020. doi:10.1093/database/bas020. PMC 3328793. PMID 22513129.
- Winnenburg, R.; Wachter, T.; Plake, C.; Doms, A.; Schroeder, M. (2008-07-11). "Facts from text: can text mining help to scale-up high-quality manual curation of gene products with ontologies?". Briefings in Bioinformatics. 9 (6): 466–478. doi:10.1093/bib/bbn043. ISSN 1467-5463. PMID 19060303.
- Percha, Bethany; Altman, Russ (2018-02-27). "A global network of biomedical relationships derived from text". Bioinformatics. 34 (15): 2614–2624. doi:10.1093/BIOINFORMATICS/BTY114.
- Robert Leaman; Chih-Hsuan Wei; Alexis Allot; Zhiyong (1 June 2020). "Ten tips for a text-mining-ready article: How to improve automated discoverability and interpretability". PLOS Biology. 18 (6): e3000716. doi:10.1371/JOURNAL.PBIO.3000716. ISSN 1544-9173. PMID 32479517. Wikidata Q96032351 .
- Wang, Lucy Lu; Lo, Kyle (2020-12-07). "Text mining approaches for dealing with the rapidly expanding literature on COVID-19". Briefings in Bioinformatics. doi:10.1093/BIB/BBAA296.
- Neumann M, King D, Beltagy I, Ammar W (2019). "ScispaCy: Fast and Robust Models for Biomedical Natural Language Processing". Proceedings of the 18th BioNLP Workshop and Shared Task. Florence, Italy: Association for Computational Linguistics: 319–327. arXiv:1902.07669. doi:10.18653/v1/W19-5034. S2CID 67788603.
- Altman RB, Bergman CM, Blake J, Blaschke C, Cohen A, Gannon F, et al. (2008). "Text mining for biology--the way forward: opinions from leading scientists". Genome Biology. 9 Suppl 2 (Suppl 2): S7. doi:10.1186/gb-2008-9-s2-s7. PMC 2559991. PMID 18834498.
- Hanspers, Kristina; Riutta, Anders; Summer-Kutmon, Martina; Pico, Alexander R. (2020-11-09). "Pathway information extracted from 25 years of pathway figures". Genome Biology. 21 (1): 273. doi:10.1186/S13059-020-02181-2. PMC 7649569. PMID 33168034.
- Hirschman L, Yeh A, Blaschke C, Valencia A (2005). "Overview of BioCreAtIvE: critical assessment of information extraction for biology". BMC Bioinformatics. 6 Suppl 1 (Suppl 1): S1. doi:10.1186/1471-2105-6-s1-s1. PMC 1869002. PMID 15960821. S2CID 5119495.