Confirmatory composite analysis
In statistics, confirmatory composite analysis (CCA) is a sub-type of structural equation modeling (SEM).[1][2][3] Although, historically, CCA emerged from a re-orientation and re-start of partial least squares path modeling (PLS-PM),[4][5][6][7] it has become an independent approach and the two should not be confused. In many ways it is similar to, but also quite distinct from confirmatory factor analysis (CFA). It shares with CFA the process of model specification, model identification, model estimation, and model assessment. However, in contrast to CFA which always assumes the existence of latent variables, in CCA all variables can be observable, with their interrelationships expressed in terms of composites, i.e., linear compounds of subsets of the variables. The composites are treated as the fundamental objects and path diagrams can be used to illustrate their relationships. This makes CCA particularly useful for disciplines examining theoretical concepts that are designed to attain certain goals, so-called artifacts,[8] and their interplay with theoretical concepts of behavioral sciences.[9]
Development
The initial idea of CCA was sketched by Theo K. Dijkstra and Jörg Henseler in 2014.[4] The scholarly publishing process took its time until the first full description of CCA was published by Florian Schuberth, Jörg Henseler and Theo K. Dijkstra in 2018.[2] As common for statistical developments, interim developments of CCA were shared with the scientific community in written form.[10][9] Moreover, CCA was presented at several conferences including the 5th Modern Modeling Methods Conference, the 2nd International Symposium on Partial Least Squares Path Modeling, the 5th CIM Community Workshop, and the Meeting of the SEM Working Group in 2018.
Statistical model
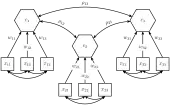
A composite is typically a linear combination of observable random variables.[11] However, also so-called second-order composites as linear combinations of latent variables and composites, respectively, are conceivable.[9][12][3][13]
For a random column vector of observable variables that is partitioned into sub-vectors , composites can be defined as weighted linear combinations. So the i-th composite equals:



- ,

where the weights of each composite are appropriately normalized (see Confirmatory composite analysis#Model identification). In the following, it is assumed that the weights are scaled in such a way that each composite has a variance of one, i.e., . Moreover, without loss of generality, it is assumed that the observable random variables are standardized having a mean of zero and a unit variance. Generally, the variance-covariance matrices of the sub-vectors are not constrained beyond being positive definite. Similar to the latent variables of a factor model, the composites explain the covariances between the sub-vectors leading to the following inter-block covariance matrix:


- ,

where is the correlation between the composites and . The composite model imposes rank one constraints on the inter-block covariance matrices , i.e., . Generally, the variance-covariance matrix of is positive definite iff the correlation matrix of the composites and the variance-covarianc matrices 's are both positive definite.[7]






In addition, the composites can be related via a structural model which constrains the correlation matrix indirectly via a set of simultaneous equations:[7]

- ,

where the vector is partitioned in an exogenous and an endogenous part, and the matrices and contain the so-called path (and feedback) coefficients. Moreover, the vector contains the structural error terms having a zero mean and being uncorrelated with . As the model needs not to be recursive, the matrix is not necessarily triangular and the elements of may be correlated.





Model identification
To ensure identification of the composite model, each composite must be correlated with at least one variable not forming the composite. Additionally to this non-isolation condition, each composite needs to be normalized, e.g., by fixing one weight per composite, the length of each weight vector, or the composite’s variance to a certain value.[2] If the composites are embedded in a structural model, also the structural model needs to be identified.[7] Finally, since the weight signs are still undetermined, it is recommended to select a dominant indicator per block of indicators that dictates the orientation of the composite.[3]
The degrees of freedom of the basic composite model, i.e., with no constraints imposed on the composites' correlation matrix , are calculated as follows:[2]
| df | = | number of non-redundant off-diagonal elements of the indicator covariance matrix |
| - | number of free correlations among the composites | |
| - | number of free covariances between the composites and indicators not forming a composite | |
| - | number of covariances among the indicators not forming a composite | |
| - | number of free non-redundant off-diagonal elements of each intra-block covariance matrix | |
| - | number of weights | |
| + | number of blocks |
Model estimation
To estimate a composite model, various methods that create composites can be used[6] such as generalized canonical correlation, principal component analysis, and linear discriminant analysis. Moreover composite-based methods for SEM can be employed to estimate weights and the correlations among the composites such as partial least squares path modeling, and generalized structured component analysis.[14]
Evaluating model fit
In CCA, the model fit, i.e., the discrepancy between the estimated model-implied variance-covariance matrix and its sample counterpart , can be assessed in two non-exclusive ways. On the one hand, measures of fit can be employed; on the other hand, a test for overall model fit can be used. While the former relies on heuristic rules, the latter is based on statistical inferences.


Fit measures for composite models comprises statistics such as the standardized root mean square residual (SRMR),[15][4] and the root mean squared error of outer residuals (RMS)[16] In contrast to fit measures for common factor models, fit measures for composite models are relatively unexplored and reliable thresholds still need to be determined. To assess the overall model fit by means of statistical testing, the bootstrap test for overall model fit,[17] also known as Bollen-Stine bootstrap test,[18] can be used to investigate whether a composite model fits to the data.[4][2]

Alternative views on CCA
Besides the originally proposed CCA, the evaluation steps known from partial least squares structural equation modeling[19] (PLS-SEM) are dubbed CCA.[20][21] It is emphasized that PLS-SEM's evaluation steps, in the following called PLS-CCA, differ from CCA in many regards:.[22] (i) While PLS-CCA aims at conforming reflective and formative measurement models, CCA aims at assessing composite models; (ii) PLS-CCA omits overall model fit assessment, which is a crucial step in CCA as well as SEM; (iii) PLS-CCA is strongly linked to PLS-PM, while for CCA PLS-PM can be employed as one estimator, but this is in no way mandatory. Hence, researchers who employ need to be aware to which technique they are referring to.
References
- Henseler, Jörg; Schuberth, Florian (2020). "Using confirmatory composite analysis to assess emergent variables in business research". Journal of Business Research. 120: 147–156. doi:10.1016/j.jbusres.2020.07.026.
- Schuberth, Florian; Henseler, Jörg; Dijkstra, Theo K. (2018). "Confirmatory Composite Analysis". Frontiers in Psychology. 9: 2541. doi:10.3389/fpsyg.2018.02541. PMC 6300521. PMID 30618962.
- Henseler, Jörg; Hubona, Geoffrey; Ray, Pauline Ash (2016). "Using PLS path modeling in new technology research: updated guidelines". Industrial Management & Data Systems. 116 (1): 2–20. doi:10.1108/IMDS-09-2015-0382.
- Henseler, Jörg; Dijkstra, Theo K.; Sarstedt, Marko; Ringle, Christian M.; Diamantopoulos, Adamantios; Straub, Detmar W.; Ketchen, David J.; Hair, Joseph F.; Hult, G. Tomas M.; Calantone, Roger J. (2014). "Common Beliefs and Reality About PLS". Organizational Research Methods. 17 (2): 182–209. doi:10.1177/1094428114526928.
- Dijkstra, Theo K. (2010). "Latent Variables and Indices: Herman Wold's Basic Design and Partial Least Squares". In Esposito Vinzi, Vincenzo; Chin, Wynne W.; Henseler, Jörg; Wang, Huiwen (eds.). Handbook of Partial Least Squares. Berlin, Heidelberg: Springer Handbooks of Computational Statistics. pp. 23–46. CiteSeerX 10.1.1.579.8461. doi:10.1007/978-3-540-32827-8_2. ISBN 978-3-540-32825-4.
- Dijkstra, Theo K.; Henseler, Jörg (2011). "Linear indices in nonlinear structural equation models: best fitting proper indices and other composites". Quality & Quantity. 45 (6): 1505–1518. doi:10.1007/s11135-010-9359-z.
- Dijkstra, Theo K. (2017). "A Perfect Match Between a Model and a Mode". In Latan, Hengky; Noonan, Richard (eds.). Partial Least Squares Path Modeling: Basic Concepts, Methodological Issues and Applications. Cham: Springer International Publishing. pp. 55–80. doi:10.1007/978-3-319-64069-3_4. ISBN 978-3-319-64068-6.
- Simon, Herbert A. (1969). The sciences of the artificial (3rd ed.). Cambridge, MA: MIT Press.
- Henseler, Jörg (2017). "Bridging Design and Behavioral Research With Variance-Based Structural Equation Modeling" (PDF). Journal of Advertising. 46 (1): 178–192. doi:10.1080/00913367.2017.1281780.
- Henseler, Jörg (2015). Is the whole more than the sum of its parts? On the interplay of marketing and design research. Enschede: University of Twente.
- Bollen, Kenneth A.; Bauldry, Shawn (2011). "Three Cs in measurement models: Causal indicators, composite indicators, and covariates". Psychological Methods. 16 (3): 265–284. doi:10.1037/a0024448. PMC 3889475. PMID 21767021.
- van Riel, Allard C. R.; Henseler, Jörg; Kemény, Ildikó; Sasovova, Zuzana (2017). "Estimating hierarchical constructs using consistent partial least squares: The case of second-order composites of common factors". Industrial Management & Data Systems. 117 (3): 459–477. doi:10.1108/IMDS-07-2016-0286.
- Schuberth, Florian; Rademaker, Manuel E; Henseler, Jörg. "Estimating and assessing second-order constructs using PLS-PM: the case of composites of composites". Industrial Management & Data Systems. doi:10.1108/IMDS-12-2019-0642. hdl:10362/104253.
- Hwang, Heungsun; Takane, Yoshio (March 2004). "Generalized structured component analysis". Psychometrika. 69 (1): 81–99. doi:10.1007/BF02295841.
- Hu, Li-tze; Bentler, Peter M. (1998). "Fit indices in covariance structure modeling: Sensitivity to underparameterized model misspecification". Psychological Methods. 3 (4): 424–453. doi:10.1037/1082-989X.3.4.424.
- Lohmöller, Jan-Bernd (1989). Latent Variable Path Modeling with Partial Least Squares. Physica-Verlag Heidelberg. ISBN 9783642525148.
- Beran, Rudolf; Srivastava, Muni S. (1985). "Bootstrap Tests and Confidence Regions for Functions of a Covariance Matrix". The Annals of Statistics. 13 (1): 95–115. doi:10.1214/aos/1176346579.
- Bollen, Kenneth A.; Stine, Robert A. (1992). "Bootstrapping Goodness-of-Fit Measures in Structural Equation Models". Sociological Methods & Research. 21 (2): 205–229. doi:10.1177/0049124192021002004.
- Hair, Joe F.; Hult, G Tomas M.; Ringle, Christian M.; Sarstedt, Marko (2014). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM). Thousand Oaks: Sage.
- Hair, Joseph F.; Anderson, Drexel; Babin, Barry; Black, William (2018). Multivariate data analysis (8 ed.). Cengage Learning EMEA. ISBN 978-1473756540.
- Hair, Joe F.; Howard, Matt C.; Nitzl, Christian (March 2020). "Assessing measurement model quality in PLS-SEM using confirmatory composite analysis". Journal of Business Research. 109: 101–110. doi:10.1016/j.jbusres.2019.11.069.
- Schuberth, Florian (in print). "Confirmatory composite analysis using partial least squares: Setting the record straight". Review of Managerial Science. doi:10.1007/s11846-020-00405-0. Check date values in:
|date=(help)