James–Stein estimator
The James–Stein estimator is a biased estimator of the mean, , of (possibly) correlated Gaussian distributed random vectors with unknown means .



It arose sequentially in two main published papers, the earlier version of the estimator was developed by Charles Stein in 1956,[1] which reached a relatively shocking conclusion that while the then usual estimate of the mean, or the sample mean written by Stein and James as , is admissible when , however it is inadmissible when and proposed a possible improvement to the estimator that shrinks the sample means towards a more central mean vector (which can be chosen a priori or commonly the "average of averages" of the sample means given all samples share the same size), is commonly referred to as Stein's example or paradox. This earlier result was improved later by Willard James and Charles Stein in 1961 through simplifying the original process.[2]





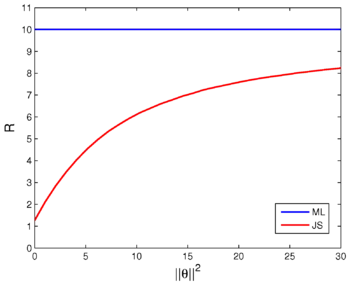
It can be shown that the James–Stein estimator dominates the "ordinary" least squares approach, meaning the James-Stein estimator has a lower or equal mean squared error than the "ordinary" least square estimator.
Setting
Let where the vector is the unknown mean of , which is -variate normally distributed and with known covariance matrix .




We are interested in obtaining an estimate, , of , based on a single observation, , of .


In real-world application, this is a common situation in which a set of parameters is sampled, and the samples are corrupted by independent Gaussian noise. Since this noise has mean of zero, it may be reasonable to use the samples themselves as an estimate of the parameters. This approach is the least squares estimator, which is .

Stein demonstrated that in terms of mean squared error , the least squares estimator, , is sub-optimal to a shrinkage based estimators, such as the James–Stein estimator, .[1] The paradoxical result, that there is a (possibly) better and never any worse estimate of in mean squared error as compared to the sample mean, became known as Stein's phenomenon.



The James–Stein estimator
If is known, the James–Stein estimator is given by


James and Stein showed that the above estimator dominates for any , meaning that the James–Stein estimator always achieves lower mean squared error (MSE) than the maximum likelihood estimator.[2][3] By definition, this makes the least squares estimator inadmissible when .
Notice that if then this estimator simply takes the natural estimator and shrinks it towards the origin 0. In fact this is not the only direction of shrinkage that works. Let ν be an arbitrary fixed vector of length . Then there exists an estimator of the James-Stein type that shrinks toward ν, namely



The James–Stein estimator dominates the usual estimator for any ν. A natural question to ask is whether the improvement over the usual estimator is independent of the choice of ν. The answer is no. The improvement is small if is large. Thus to get a very great improvement some knowledge of the location of θ is necessary. Of course this is the quantity we are trying to estimate so we don't have this knowledge a priori. But we may have some guess as to what the mean vector is. This can be considered a disadvantage of the estimator: the choice is not objective as it may depend on the beliefs of the researcher.

Interpretation
Seeing the James–Stein estimator as an empirical Bayes method gives some intuition to this result: One assumes that θ itself is a random variable with prior distribution , where A is estimated from the data itself. Estimating A only gives an advantage compared to the maximum-likelihood estimator when the dimension is large enough; hence it does not work for . The James–Stein estimator is a member of a class of Bayesian estimators that dominate the maximum-likelihood estimator.[4]

A consequence of the above discussion is the following counterintuitive result: When three or more unrelated parameters are measured, their total MSE can be reduced by using a combined estimator such as the James–Stein estimator; whereas when each parameter is estimated separately, the least squares (LS) estimator is admissible. A quirky example would be estimating the speed of light, tea consumption in Taiwan, and hog weight in Montana, all together. The James–Stein estimator always improves upon the total MSE, i.e., the sum of the expected errors of each component. Therefore, the total MSE in measuring light speed, tea consumption, and hog weight would improve by using the James–Stein estimator. However, any particular component (such as the speed of light) would improve for some parameter values, and deteriorate for others. Thus, although the James–Stein estimator dominates the LS estimator when three or more parameters are estimated, any single component does not dominate the respective component of the LS estimator.
The conclusion from this hypothetical example is that measurements should be combined if one is interested in minimizing their total MSE. For example, in a telecommunication setting, it is reasonable to combine channel tap measurements in a channel estimation scenario, as the goal is to minimize the total channel estimation error. Conversely, there could be objections to combining channel estimates of different users, since no user would want their channel estimate to deteriorate in order to improve the average network performance.
The James–Stein estimator has also found use in fundamental quantum theory, where the estimator has been used to improve the theoretical bounds of the entropic uncertainty principle (a recent development of the Heisenberg uncertainty principle) for more than three measurements.[5]
Improvements
The basic James–Stein estimator has the peculiar property that for small values of the multiplier on is actually negative. This can be easily remedied by replacing this multiplier by zero when it is negative. The resulting estimator is called the positive-part James–Stein estimator and is given by



This estimator has a smaller risk than the basic James–Stein estimator. It follows that the basic James–Stein estimator is itself inadmissible.[6]
It turns out, however, that the positive-part estimator is also inadmissible.[3] This follows from a general result which requires admissible estimators to be smooth.
Extensions
The James–Stein estimator may seem at first sight to be a result of some peculiarity of the problem setting. In fact, the estimator exemplifies a very wide-ranging effect; namely, the fact that the "ordinary" or least squares estimator is often inadmissible for simultaneous estimation of several parameters. This effect has been called Stein's phenomenon, and has been demonstrated for several different problem settings, some of which are briefly outlined below.
- James and Stein demonstrated that the estimator presented above can still be used when the variance is unknown, by replacing it with the standard estimator of the variance, . The dominance result still holds under the same condition, namely, .[2]
- The results in this article are for the case when only a single observation vector y is available. For the more general case when vectors are available, the results are similar:



- where is the -length average of the observations.


- The work of James and Stein has been extended to the case of a general measurement covariance matrix, i.e., where measurements may be statistically dependent and may have differing variances.[7] A similar dominating estimator can be constructed, with a suitably generalized dominance condition. This can be used to construct a linear regression technique which outperforms the standard application of the LS estimator.[7]
- Stein's result has been extended to a wide class of distributions and loss functions. However, this theory provides only an existence result, in that explicit dominating estimators were not actually exhibited.[8] It is quite difficult to obtain explicit estimators improving upon the usual estimator without specific restrictions on the underlying distributions.[3]
References
- Stein, C. (1956), "Inadmissibility of the usual estimator for the mean of a multivariate distribution", Proc. Third Berkeley Symp. Math. Statist. Prob., 1, pp. 197–206, MR 0084922, Zbl 0073.35602
- James, W.; Stein, C. (1961), "Estimation with quadratic loss", Proc. Fourth Berkeley Symp. Math. Statist. Prob., 1, pp. 361–379, MR 0133191
- Lehmann, E. L.; Casella, G. (1998), Theory of Point Estimation (2nd ed.), New York: Springer
- Efron, B.; Morris, C. (1973). "Stein's Estimation Rule and Its Competitors—An Empirical Bayes Approach". Journal of the American Statistical Association. American Statistical Association. 68 (341): 117–130. doi:10.2307/2284155. JSTOR 2284155.
- Stander, M. (2017), Using Stein's estimator to correct the bound on the entropic uncertainty principle for more than two measurements, arXiv:1702.02440, Bibcode:2017arXiv170202440S
- Anderson, T. W. (1984), An Introduction to Multivariate Statistical Analysis (2nd ed.), New York: John Wiley & Sons
- Bock, M. E. (1975), "Minimax estimators of the mean of a multivariate normal distribution", Annals of Statistics, 3 (1): 209–218, doi:10.1214/aos/1176343009, MR 0381064, Zbl 0314.62005
- Brown, L. D. (1966), "On the admissibility of invariant estimators of one or more location parameters", Annals of Mathematical Statistics, 37 (5): 1087–1136, doi:10.1214/aoms/1177699259, MR 0216647, Zbl 0156.39401
Further reading
- Judge, George G.; Bock, M. E. (1978). The Statistical Implications of Pre-Test and Stein-Rule Estimators in Econometrics. New York: North Holland. pp. 229–257. ISBN 0-7204-0729-X.