Proser2
PROSER2, also known as proline and serine rich 2, is a protein that in humans is encoded by the PROSER2 gene. PROSER2, or c10orf47 (Chromosome 10 open reading frame 47), is found in band 14 of the short arm of chromosome 10 (10p14) and contains a highly conserved SARG domain.[1][2] It is a fast evolving gene with two paralogs, c1orf116 and specifically androgen-regulated gene protein isoform 1.[1][3][4] The PROSER2 protein has a currently uncharacterized function however, in humans, it may play a role in cell cycle regulation, reproductive functioning, and is a potential biomarker of cancer.[5][6][7][8][9][10]
Gene
This gene is 48,880 bases in length and is 3,360 base pairs in length after transcription to mRNA.[11][12] PROSER2 has 5 splice variants, 3 of which are alternatively spliced and 2 of which are unspliced forms.[13] It contains an upstream in-frame stop codon and a 2,000 bp promoter.[11][14]
PROSER2 Transcript
| Splice Variant[14] | Name[16] | Sequence Length (bp)[14] | Protein Length (aa)[14] | Mass (DA)[16] | Type[14] | Features |
|---|---|---|---|---|---|---|
| 1 - Primary Transcript | PROSER2; c10orf47 | 3360[11] | 435 | 45,802 | Protein coding
(full length) |
5 exons; 4 coding exons[14] Predicted: 1 dimethylated arginine; 1 omega-N-methylarginine[16]
37 Phosphorylation sites;[17] 2 SUMO Interaction Motifs;[18] 2 S-Palmitoylation sites;[19] 2 GalNac O-glycosylation sites[20] Isoelectric point: 6.81 Charge: 3.0[14] |
| 2 | 1646 | 341 | Protein coding | 5 exons; 4 coding exons[14] | ||
| 3 | c10orf47 isoform CRA_b | 1232 | 239 | 24,793 | Protein coding | 1 exon; 1 coding exon
Isoelectric point: 12.21 Charge: 19.0[14] |
| 4 | 476 | 85 | 9,554 | Protein coding | 3 exons; 2 coding exons
3' truncated in transcript;[14] 85th aa is non-terminal residue[16] Isoelectric point: 4.25 Charge: -8.0[14] | |
| 5 | 728 | No protein | Processed transcript | 4 exons; 0 coding exons[14] |
Homology and Evolution
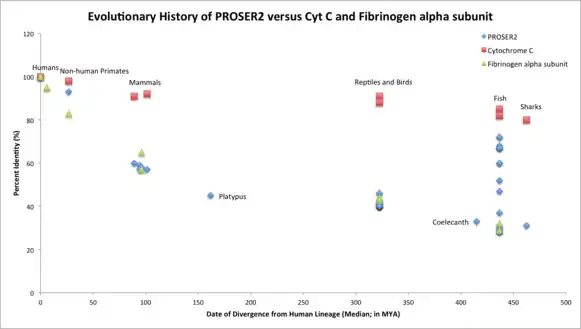
Orthologous Space
The orthologous space for PROSER2 is fairly large, as 143 organisms are reported to have orthologs with the human PROSER2.[12] The most distant ortholog of the human PROSER2 is the elephant shark, Callorhinchus milii. The most distant relatives of humans with PROSER2 are fish and sharks (cartilaginous fishes). For this same reason, it can be inferred that PROSER2 originated in vertebrates.[3]
Paralogous Space
The human PROSER2 gene has two paralogs: c1orf116 and specifically androgen-regulated gene protein isoform 1.[3]
Conserved Regions
Multiple sequence alignments demonstrated that the 3’ end of the proline-serine rich 2 protein is highly conserved in both distant and close homologs. These widely conserved amino acids found in all primates, mammals, reptiles, birds, amphibians, fish, and sharks for which sequences are available include: R421, G406, V409, A424, L425, L428, G429, and L430. It can be noted that these highly conserved amino acids comprise much of the 3’ end of the specifically androgen-regulated gene protein (SARG) domain. The 5’ end of the proline-serine rich 2 protein is highly conserved in close relatives of humans including all primates, mammals, reptiles, and birds for which sequences are available. PROSER2 has an even balance of basic and acidic residues which are conserved throughout all homologs.[23][24]
Evolutionary Pattern
PROSER2 is a fast evolving gene, similar to Fibrinogen alpha subunit (FGA). It aligns almost perfectly with Fibrinogen’s evolutionary history and is much farther away from the evolutionary timeline of Cytochrome C (CYCS) which is evolving more slowly than PROSER2 or FGA. Gene duplication of PROSER2 occurred approximately in fish which diverged from humans 436.8 MYA.[4]
Proline and Serine Rich 2 Protein
In Homo sapiens, PROSER2 encodes the proline and serine-rich protein 2 which is 435 amino acids in length and has a molecular weight of 45,802 Da.[1] This protein has a fairly neutral basal isoelectric point of 6.81.[25] The proline and serine rich 2 protein contains a conserved SARG (specifically androgen-regulated gene protein) domain that spans 388 amino acids within PROSER2. The SARG domain belongs to the pfam15385 family of genes. Its true function has yet to be elucidated, but it is a suspected androgen receptor because it is up-regulated in the presence of androgens, but not glucocorticoids.[2] The SARG domain is highly expressed in the prostate where PROSER2 has also been reported.[5]
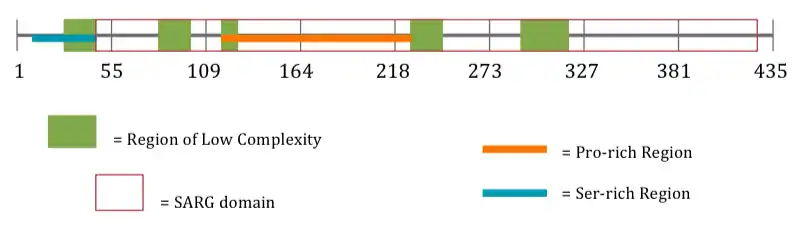
Protein Internal Structure
| Features | Location |
|---|---|
| Ser-rich Region[16] | aa 8-43[16] |
| Region of Low Complexity[14] | aa 27-43[14] |
| Region of Low Complexity[14] | aa 87-105[14] |
| Region of Low Complexity[14] | aa 113-126[14] |
| Region of Low Complexity[14] | aa 143-171[14] |
| Pro-rich Region[16] | aa 147-254[16] |
| Region of Low Complexity[14] | aa 228-246[14] |
| Region of Low Complexity[14] | aa 291-310[14] |
| SARG Domain
(Specifically androgen-regulated gene protein)[2] |
aa 44-433[2] |
Post-Translational Modifications
PROSER2 contains 35 predicted Serine phosphorylation sites, as well as 2 predicted Threonine phosphorylation sites on conserved residues.[17] It is also predicted to contain 2 SUMO Interaction Motifs, 2 S-Palmitoylation sites, as well as 2 GalNac O-glycosylation sites all located on or near highly conserved amino acids.[18][19][20] These modifications may change the folding and function of the protein which is predicted to be localized to the nucleus.[28]
Predicted Secondary Structure
PROSER2’s structure is currently uncharacterized. However, it is likely to contain 4 alpha helices and 5 domains of beta sheets which are conserved across all mammalian homologs.[29] Based on its structural features and post-translational modifications, it is predicted to be a soluble protein secreted from the nucleus via a non-classical secretion pathway.[28][30][31]
Function
The function of proline and serine rich 2 protein is currently unknown. However, it is listed in several U.S. patents as a potential biomarker of cancer.[5][6][7][8][9][10]
Interacting Proteins
Previous experimentation has found that PROSER2 interacts with several other proteins including: STK24, ESR2, POT1, ACTB, and EPS8.[15][32] These interacting proteins are involved in control of apoptosis, reproductive cell differentiation, telomere maintenance, cell integrity, and cell cycle progression, respectively. These interactions identify PROSER2 as a gene heavily involved in the regulation of cell differentiation and apoptosis.[15]
Expression
PROSER2 is extremely tissue specific in its expression, which is often low. In humans, PROSER2 is most highly expressed in the bone marrow, fetal brain, fetal kidney, liver, fetal liver, lung, fetal lung, lymph node, prostate, stomach, thymus, and trachea (GEO Profile ID: 69555271). It has also been found to be highly expressed in the colon, testes, parotid gland, and uterus (GEO Profile ID: 10034772) . The high expression in the testicular and prostate tissue is as expected given the existence of the SARG domain in the gene and its association with androgens. PROSER2 is least expressed in the heart, spinal cord, and several areas of the adult brain (GEO Profile ID: 69555271). PROSER2 has higher expression in ETP-ALL (early T-cell precursor acute lymphoblastic leukemia) patients compared to controls (GEO Profile ID: 92018456) and is highly expressed in primary tumors of the prostate compared to benign and malignant samples (GEO Profile ID: 14264706). PROSER2 is underexpressed in males with AIS (Androgen Insensitivity Syndrome), which follows with the evidence previously described regarding the SARG domain. Treatment with dihydrotestosterone has been found to cause genital fibroblasts to increase expression of PROSER2, further supporting that it is an androgen-responsive gene (GEO Profile ID: 20808032).[33]
Transcription Factor Interactions
PROSER2 interacts most strongly with the following transcription factors: Vertebrate TATA binding protein factor, ZF5 POZ domain zinc finger, CTCF and BORIS gene family transcriptional regulators, E2F-myc activator/cell cycle regulator, MYT1 C2HC zinc finger protein, SOX/SRY– sex/testis determining and related HMG box factors, CCAAT binding factors, HOX-PBX complexes, and C2HC zinc finger transcription factors 13.[34] The SRY gene is the primary factor in determining testicular formation during development, so it is logical that PROSER2's association with androgens would be controlled by transcription factors in the SOX/SRY-sex/testis determining and related HMG box factors family.[34] The E2F-myc activator/cell cycle regulator is also important because Myc has been implicated in cancer pathways, so this relationship with its transcription factor provides supplementary evidence of PROSER2's role as a potential biomarker of cancer.[5][6][7][8][9][10]
Clinical Significance
Although PROSER2’s function in humans has not been elucidated, its SARG domain, interacting proteins/transcription factors, and expression patterns indicate that PROSER2 is involved in cell cycle control and apoptosis, and is androgen-responsive in nature. PROSER2 may be a biomarker of epithelial cell, breast, prostate, ovarian, lung, brain, and blood cancers as demonstrated in several US Patents.[5][6][7][8][9][10]
References
- NCBI (National Center for Biotechnology Information) Protein
- Marchler-Bauer A et al. (2015), "CDD: NCBI's conserved domain database.", Nucleic Acids Res. 43(Database issue):D222-6.
- NCBI BLAST (National Center for Biotechnology Information Basic Local Alignment Search Tool ) [http://blast.ncbi.nlm.nih.gov/Blast.cgi]
- Time Tree [http://www.timetree.org/]
- Pawlowski,T.,Yeatts, K., and Akhavan, R. (2012). Circulating biomarkers for cancer.
- Birrer, M.J., Bonome, T.A., Sood, A., and LU, C. (2013). Pro-angiogenic genes in ovarian tumor endothelial cell isolates.
- Nguyen,L.S., Kim, H.-G., Rosenfeld, J.A., Shen, Y., Gusella, J.F., Lacassie, Y., Layman, L.C., Shaffer, L.G., and Gécz, J. (2013). Contribution of copy number variants involving nonsense-mediated mRNA decay pathway genes to neuro-developmental disorders. Hum. Mol. Genet. 22, 1816–1825.
- Schettini, J., Hornung, T., Holterman, D., and Spetzler, D. (2014). Biomarker compositions and methods.
- Seto, M., Tagawa, H., Yoshida, Y., and Kira, S. (2008). Methods for Diagnosis and Prognosis of Malignant Lymphoma.
- Zarbl, H., and Graham, J. (2014). Novel Method of Cancer Diagnosis and Prognosis and Prediction of Response to Therapy.
- NCBI (National Center for Biotechnology Information) Nucleotide
- NCBI (National Center for Biotechnology Information) Gene
- NCBI (NationalCenter for Biotechnology Information) AceView [https://www.ncbi.nlm.nih.gov/IEB/Research/Acembly/]
- Ensembl
- GeneCards [http://www.genecards.org/]
- UniProt [http://www.uniprot.org/uniprot/]
- NetPhos. ExPASy BioInformatics Resource Portal [http://expasy.org/]
- GPS-SUMO. ExPASy BioInformatics Resource Portal [http://expasy.org/]
- GPS-Lipid. ExPASy BioInformatics Resource Portal [http://expasy.org/]
- YinOYang. ExPASy BioInformatics Resource Portal [http://expasy.org/]
- NCBI BLAST (National Center for Biotechnology Information Basic Local Alignment Search Tool ) [http://blast.ncbi.nlm.nih.gov/Blast.cgi]
- Time Tree [http://www.timetree.org/]
- SDSC (San Diego Supercomputer Center) Biology Workbench. BOXSHADE [http://workbench.sdsc.edu/]
- SDSC (San Diego Supercomputer Center) Biology Workbench. ClustalW Multiple Sequence Alignment [http://workbench.sdsc.edu/]
- Isoelectric Point Determination. Biology WorkBench [http://workbench.sdsc.edu]
- Ensembl
- UniProt [http://www.uniprot.org/uniprot/]
- Predict Protein. [https://www.predictprotein.org/]
- PELE. SDSC Biology Workbench [http://workbench.sdsc.edu/]
- SOSUI. ExPASy BioInformatics Resource Portal [http://expasy.org/]
- Secretome. ExPASy BioInformatics Resource Portal [http://expasy.org/]
- STRING 10: Known and Predicted Protein-Protein Interactions. [http://string-db.org/]
- Barrett T, Wilhite SE, Ledoux P, Evangelista C, Kim IF, Tomashevsky M, et al. (2013). "(Jan 2013). "NCBI GEO: archive for functional genomics data sets--update"". Nucleic Acids Research. 41 (Database issue): D991–5. doi:10.1093/nar/gks1193. PMC 3531084. PMID 23193258.
- Genomatix. ElDorado.[https://www.genomatix.de/cgi-bin//eldorado/eldorado.pl]
- dbSNP NCBI (National Center for Biotechnology Information Basic Local Alignment Search Tool) [https://www.ncbi.nlm.nih.gov/projects/SNP]
Further reading
- Gregory, CW, Hamil, KG, Kim, D, Hall, SH, Pretlow, TG, Mohler, JL, French, FS (Dec 1998). "Androgen Receptor Expression in Androgen-independent Prostate Cancer Is Associated with Increased Expression of Androgen-regulated Genes". Cancer Research. 58 (24): 5718–24. PMID 9865729.
- Nguyen, LS, Kim, HG, Rosenfeld, JA, Shen, Y, Gusella, JF, Lacassie, Y, Layman, LC, Shaffer, LG, Gécz, J (May 2013). "Contribution of copy number variants involving nonsense-mediated mRNA decay pathway genes to neuro-developmental disorders". Human Molecular Genetics. 22 (9): 1816–25. doi:10.1093/hmg/ddt035. PMID 23376982.
- Nickel, W (Apr 2003). "The mystery of nonclassical protein secretion. A current view on cargo proteins and potential export routes". European Journal of Biochemistry. 270 (10): 2109–19. doi:10.1046/j.1432-1033.2003.03577.x. PMID 12752430.
- Steketee K, Ziel-van der Made AC, van der Korput HA, Houtsmuller AB, Trapman J (Oct 2004). "A bioinformatics-based functional analysis shows that the specifically androgen-regulated gene SARG contains an active direct repeat androgen response element in the first intron". Journal of Molecular Endocrinology. 33 (2): 477–91. doi:10.1677/jme.1.01478. PMID 15525603.
- Williamson, MP (Jan 1994). "The structure and function of proline-rich regions in proteins". Biochemical Journal. 297 (2): 249–60. doi:10.1042/bj2970249. PMC 1137821. PMID 8297327.