Shared register
In distributed computing, shared-memory systems and message-passing systems are two means of interprocess communication which have been heavily studied. In shared-memory systems, processes communicate by accessing shared data structures. A shared (read/write) register, sometimes just called a register, is a fundamental type of shared data structure which stores a value and has two operations: read, which returns the value stored in the register, and write, which updates the value stored. Other types of shared data structures include read–modify–write, test-and-set, compare-and-swap etc. The memory location which is concurrently accessed is sometimes called a register.
Classification
Registers can be classified according to the consistency condition they satisfy when accessed concurrently, the domain of possible values that can be stored, and how many processes can access with the read or write operation, which leads to in total 24 register types.[1]
| Consistency condition | Domain | Write | Read |
|---|---|---|---|
| safe regular atomic | binary integer | single-writer multi-writer | single-reader multi-reader |
When read and write happen concurrently, the value returned by read may not be uniquely determined. Lamport defined three types of registers: safe registers, regular registers and atomic registers.[1] A read operation of a safe register can return any value if it is concurrent with a Write operation, and returns the value written by the most recent write operation if the read operation does not overlap with any write. A regular register differs from a safe register in that the read operation can return the value written by either the most recent completed Write operation or a Write operation it overlaps with. An atomic register satisfies the stronger condition of being linearizable.
Registers can be characterized by how many processes can access with a read or write operation. A single-writer (SW) register can only be written by one process and a multiple-writer (MW) register can be written by multiple processes. Similarly single-reader (SR) register can only be read by one process and multiple-reader (MR) register can be read by multiple processes. For a SWSR register, it is not necessary that the writer process and the reader process are the same.
Constructions
The figure below illustrates the constructions stage by stage from the implementation of SWSR register in an asynchronous message-passing system to the implementation of MWMR register using a SW Snapshot object. This kind of construction is sometimes called simulation or emulation.[2] In each stage (except Stage 3), the object type on the right can be implemented by the simpler object type on the left. The constructions of each stage (except Stage 3) are briefly presented below. There is an article which discusses the details of constructing snapshot objects.

An implementation is linearizable if, for every execution there is a linearization ordering that satisfies the following two properties:
- if operations were done sequentially in order of their linearization, they would return the same result as in the concurrent execution.
- If operation op1 ends before operation op2 begins, then op1 comes before op2 in linearization.
Implementing an atomic SWSR register in a message passing system
A SWSR atomic (linearizable) register can be implemented in an asynchronous message-passing system, even if processes may crash. There is no time limit for processes to deliver messages to receivers or to execute local instructions. In other words, processes can not distinguish between processes which respond slowly or simply crash.
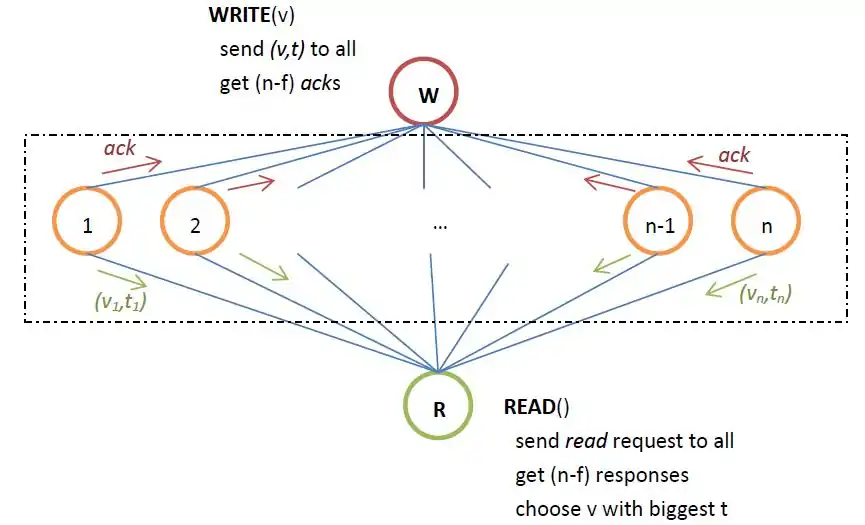
The implementation given by Attiya, Bar-Noy and Dolev[3] requires n>2f, where n is the total number of processes in the system and f is the maximum number of processes that can crash during execution. The algorithm is as follows:
| Writer | Reader |
|---|---|
WRITE(v)
t++
send (v,t) to all processes
wait until getting (n-f) acknowledgements
|
READ()
send read request to all processes
wait until getting (n-f) responses of them
choose v with the biggest t
|
The linearization order of operations is: linearize writes in the order as they occur and insert the read after the write whose value it returns. We can check that the implementation is linearizable. We can check property 2 especially when op1 is write and op2 is read, and 'read is immediately after write. We can show by contradiction. Assume the read does not see the write, and then according to the implementation, we must have two disjoint sets of size (n-f) among the n processes. So 2*(n-f)≤ n leading to n≤2f, which contradicts the fact that n>2f. So the read must read at least one value written by that write.
Implementing a SWMR register from SWSR registers
A SWMR register can be written by only one process but can be read by multiple processes.
Readers Writers | ⋯ | |||
|---|---|---|---|---|
| A[1,1] | A[1,2] | ⋯ | A[1,n] | |
| A[2,1] | A[2,2] | ⋯ | A[2,n] | |
| ⋮ | ⋯ | ⋯ | ⋯ | ⋯ |
| A[n,1] | A[n,2] | ⋯ | A[n,n] | |
| w | A[n+1,1] | A[n+1,2] | ⋯ | A[n+1,n] |



Let n be the number of processes which can read the SWMR register. Let Ri, 0<i≤n, refer to the readers of the SWMR register. Let w be the single writer of the SWMR. The figure on the right shows a construction of a SWMR register using an array of n(n+1) SWSR registers. We denote the array by A. Each SWSR register A[i,j] is writable by Ri when 0<i≤n and is writable by w when i=n+1. Each SWSR register A[i,j] is readable by Rj. The implementations of read and write are shown below.
| Writer |
w: WRITE(v) |
for j = i..n
t++
write (v,t) in A[n+1,j]
end for
|
|---|---|---|
| Readers |
Ri: READ() |
for k = 1..(n+1)
(V[k],T[k]) <- read A[k,i]
end for
take k such that for all l, T[k] >= T[l]
r <- V[k]
t <- T[k]
for j=1..n
write (r,t) in A[i,j]
end for
return r
|
The t-value of an operation is the value of t it writes and the operations are linearized by t-values. If write and read have the same t-value, order write before read. If several reads have the same t-values, order them by the start time.
Implementing a MWMR register from a SW Snapshot object
We can use the a SW Snapshot object of size n to construct a MWMR register.
| Writer | Readers |
|---|---|
| Pi: WRITE(v) | Pi: READ() |
((v1,t1), …, (vn,tn)) <- V.SCAN()
let t = max(t1,…,tn)+1
V.UPDATE(i,(v,t))
|
V.SCAN
return value with largest timestamp, in the result of the scan
(break ties by using rightmost pair of largest timestamp) |
The linearization order is as follows. Order write operations by t-values. If several writes have the same t-value, order the operation with small process ID in front. Insert reads right after write whose value they return, breaking ties by process ID and if still tied, break tie by start time.
References
- Kshemkalyani, Ajay D.; Singhal, Mukesh (2008). Distributed computing : principles, algorithms, and systems. Cambridge: Cambridge University Press. pp. 435–437. ISBN 9780521876346.
- Attiya, Hagit; Welch, Jennifer (Mar 25, 2004). Distributed computing: fundamentals, simulations, and advanced topics. John Wiley & Sons, Inc. ISBN 978-0-471-45324-6.
- Attiya, Hagit; Bar-Noy, Amotz; Dolev, Danny (1990). "Sharing Memory Robustly in Message-passing Systems". Proceedings of the Ninth Annual ACM Symposium on Principles of Distributed Computing. PODC '90: 363–375. doi:10.1145/93385.93441. ISBN 089791404X.