Visual Word
Visual words, as used in image retrieval systems,[1] refer to small parts of an image which carry some kind of information related to the features (such as the color, shape or texture), or changes occurring in the pixels such as the filtering, low-level feature descriptors (SIFT, SURF, ...etc.).
History
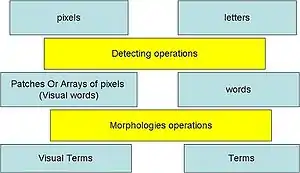
The approaches of text retrieval system (or information retrieval IR system [1]), which developed over 40 years, are based on keywords or Term. The advantage of these approaches is particularly due to the fact that they are effective and fast. Text-search engines are able quickly to find documents from hundreds or millions (by using vector space model [2]). In the same time of that, text retrieval systems have a huge success, the standard image retrieval systems (like simple search by colors, shapes...etc.) have a large number of limitations. Consequently, researchers try to take advantage from text retrieval techniques to apply them to image retrieval. That can be by a new kind of vision to understand images as textual documents, which is visual words approach.[3]
Analogy text-image
Let's consider that the pixels of an image, which are the smallest parts in a digital images (can not be divided into smaller ones), are like the letters of an alphabetical language. Then, a set of pixels in an image (patches or arrays of pixels) is a word. Each word can then be re-processed into a morphological system to extract a term related to that word. Then, several words can share a same meaning, each one will refer to the same term (like in any language). More than one words shared the same meaning and its belong to the same term (have same information). By this view, researchers can take advantage from text retrieval techniques to apply them to image retrieval system.
Visual definitions
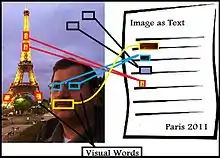
If we apply this principle to images then we have to find what those words and terms will be in our images. The idea is to try to understand the images like a collection of "visual words".
Definition 1: Visual word: [4] it is a small patch on the image (array of pixels) which can carry any kind of interesting information in any feature space (color changes, texture changes ...etc.).
In general visual words (VWs) exist in their feature space of continuous values implying huge number of words and therefore a huge language. Since image retrieval systems need to use text retrieval techniques which are dependent on natural languages and this ones have a limit to the number of terms and words, there are important needs to reduce the number of visual words.
A number of solutions exist to solve this problem, one of them is to divide the feature space into ranges, each one having common characteristics (which can be considered as a same word), nonetheless this solution carries many issues, like the division strategy, the size of range in the feature space, etc. Another solution proposed by researchers is using a clustering mechanism to classify and merge words carrying common information in a finite number of terms.
Definition 2: Visual term: it is the clustering result in the feature space (centers of the clusters), more than one patch can give nearest information in feature space, so we can consider it in the same term.
As the Term in text (the infinity verb, nouns, articles ...etc.) refer to many common words have same characteristics, the visual term (as its clustering result), it will refer to all common words which shared the same information in feature space.
And if all images refer to the same set of visual terms then all images can speak the same language (or visual language).
Definition 3: Visual language: it's a set of visual words & visual terms, (we can consider the visual terms alone is the “Visual Vocabulary” which will be the reference and the retrieval system will depend on it for retrieve images).
And all images will be represented with this visual language as a collection of visual words (VW) or what can call it bag of visual words
Definition 4: Bag of visual words: [4] it's a collection of visual words which together can give information about the meaning of the image at all (or parts of it).
Based on this kind of image representation, we can then use text retrieval techniques to design an image retrieval system. However, since all text retrieval systems depend on terms, the user's query images must be converted into a set of visual terms in the system. Then, it will compare these visual terms with all visual terms in the database.
See also
References
- BAEZA-YATES, R. A.; RIBEIRO-NETO, B. A. (1999), Modern Information Retrieval, ACM Press Addison-Wesley
- SALTON, G. (1971), The SMART Retrieval System
- JURIE, F.; TRIGGS, B. (2005), Creating Efficient Codebooks for Visual Recognition
- Yang, Jun; Jiang, Yu-Gang; Yu-Gang, Hauptmann; Ngo, Chong-Wah (2007), Evaluating bag-of-visual-words representations in scene classification, Augsburg, Bavaria, Germany: ACM