Block Range Index
A Block Range Index or BRIN is a database indexing technique. They are intended to improve performance with extremely large[lower-roman 1] tables.
BRIN indexes provide similar benefits to horizontal partitioning or sharding but without needing to explicitly declare partitions.[1]
A BRIN is applicable to an index on a table that is large and where the index key value is easily sorted and evaluated with a MinMax function.[lower-roman 2]
BRIN were originally proposed by Alvaro Herrera of 2ndQuadrant in 2013 as 'Minmax indexes'.[2] Implementations thus far are tightly coupled to internal implementation and storage techniques for the database tables. This makes them efficient, but limits them to particular vendors. So far PostgreSQL is the only vendor to have announced a live product with this specific feature, in PostgreSQL 9.5.[3][4] Other vendors have described some similar features,[2] including Oracle,[5][6] Netezza 'zone maps',[7] Infobright 'data packs',[8] MonetDB[9] and Apache Hive with ORC/Parquet.[10]
Design
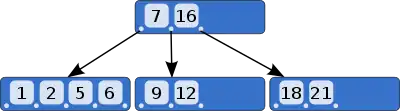
BRIN operate by "summarising" large blocks of data into a compact form, which can be efficiently tested to exclude many of them from a database query, early on. These tests exclude a large block of data for each comparison. By reducing the data volume so early on, both by representing large blocks as small tuples, and by eliminating many blocks, BRIN substantially reduce the amount of detailed data that must be examined by the database node on a row-by-row basis.[11]
Data storage in large databases is layered and chunked, with the table storage arranged into 'blocks'. Each block contains perhaps 1MB in each chunk[lower-roman 3][13] and they are retrieved by requesting specific blocks from a disk-based storage layer. BRIN are a lightweight in-memory summary layer above this: each tuple in the index summarises one block as to the range of the data contained therein: its minimum and maximum values, and if the block contains any non-null data for the column(s) of interest.[14]
Unlike a traditional index which locates the regions of the table containing values of interest, BRIN act as "negative indexes",[5] showing the blocks that are definitely not of interest and thus do not need to be processed further.
Some simple benchmarks suggest a five-fold improvement in search performance with an index scan, compared to the unindexed table.[3] Compared to B-trees, they avoid their maintenance overhead.[2]
As BRIN are so lightweight, they may be held entirely in memory, thus avoiding disk overhead during the scan. The same may not be true of B-tree: B-tree requires a tree node for every approximately N rows in the table, where N is the capacity of a single node, thus the index size is large. As BRIN only requires a tuple for each block (of many rows), the index becomes sufficiently small to make the difference between disk and memory. For a 'narrow' table[lower-roman 4] the B-tree index volume approaches that of the table itself; the BRIN may be only 5-15% of it.[15]
Advantages
Search and index scan
A large database index would typically use B-tree algorithms. BRIN is not always a substitute for B-tree, it is an improvement on sequential scanning of an index, with particular (and potentially large) advantages when the index meets particular conditions for being ordered and for the search target to be a narrow set of these values. In the general case, with random data, B-tree may still be superior.[3]
A particular advantage of the BRIN technique, shared with Oracle Exadata's Smart Scanning,[6] is in the use of this type of index with Big Data or data warehousing applications, where it is known that almost all of the table is irrelevant to the range of interest. BRIN allows the table to be queried in such cases by only retrieving blocks that may contain data of interest and excluding those which are clearly outside the range, or contain no data for this column.
Insert
A regular problem with the processing of large tables is that retrieval requires the use of an index, but maintaining this index slows down the addition of new records. Typical practices have been to group additions together and add them as a single bulk transaction, or to drop the index, add the batch of new records and then recreate the index. Both of these are disruptive to simultaneous read / write operations and may not be possible in some continuously-operating businesses.[16]
With BRIN, the slowdown from maintaining the index is much reduced compared to B-tree.[17] Wong reports that B-tree slowed down additions to an unindexed 10GB table by 85%, but a comparable BRIN only had an overhead of 11%.[1]
Index creation
BRIN may be created for extremely large data where B-tree would require horizontal partitioning.[14]
Creating the BRIN is also much faster than for a B-tree, by 80%.[1] This would be a useful improvement to refactoring existing database applications that use the drop-add-reindex approach, without requiring code changes.
Implementation
Dependence on table ordering
Multiple BRIN may be defined for different columns on a single table. However, there are restrictions.
BRIN are only efficient if the ordering of the key values follows the organisation of blocks in the storage layer.[13][15] In the simplest case, this could require the physical ordering of the table, which is often the creation order of the rows within it, to match the key's order. Where this key is a creation date, that may be a trivial requirement.[14]:9
If the data is truly random, or if there is much churn of the key values in a 'hot' database, the assumptions underlying BRIN may break down. All blocks contain entries "of interest" and so few may be excluded early on by the BRIN range filter.
In most cases, BRIN is restricted to a single index per table. Multiple BRIN may be defined, but only one is likely to have suitable ordering. If two (or more) indexes have similar ordering behaviour, it may be possible and useful to define multiple BRIN on the same table. An obvious example is where both a creation date and a record_id column both increase monotonically with the record creation sequence. In other cases, the key value may not be monotonic, but provided that there is still a strong grouping within the record's physical order, BRIN is effective.
Exadata Storage Indexes
BRIN have some similarities to Oracle Exadata "Storage Indexes".[2][5][18] Exadata has the strong concept of a 'storage layer' in its architecture stack. Table data is held in blocks or 'storage cells' on the storage servers. These storage cells are opaque to the storage server and are returned to the database engine on request, by their identifier. Previously, the database nodes must request all the storage cells in order to scan them.[6]
Storage Indexes provides data pruning at this layer: efficiently indicating sections that are of no further interest.[13][lower-roman 5][19] The Storage Index is loaded into memory on the storage server, so that when a request for cells is issued it may be predicated with search values. These are compared to the Storage Index and then only the relevant cells need be returned to the database node.
Performance advantages with a Storage Index are most evident when the indexed column contains many nulls. Massive performance advantages are gained when scanning across sparse data.[20]
Development
Development for PostgreSQL was carried out as part of the AXLE project (Advanced Analytics for Extremely Large European Databases)[21] This work was partially funded by the European Union's Seventh Framework Programme (FP7/2007-2013).[22]
PostgreSQL
Implementation for PostgreSQL was first evident in 2013.[2] BRIN appeared in release 9.5 of PostgreSQL at the start of 2016.[15][23]
See also
Notes
- 'Large' here refers to the number of rows in a table, rather than the field sizes or overall size.
- A function which efficiently evaluates a large number of data items and returns their minimum and maximum values. The concepts of "minimum" and "maximum" are broad and may be applied to any data type, or their combinations, which is sortable.
- PostgreSQL has a default block size of 128× 8k pages, or 1MB.[3] Oracle terms these 'storage regions' and gives them a default size of 1MB.[12]
- The table columns are barely wider than the indexed columns.
- Foote[13] describes the Index as holding "a flag to denote whether any Nulls exist". This is probably a typo: Oracle describes them as, "negative indexes" where "they identify the areas that definitely will not contain the values"[5] In such a case, the flag would be more clearly described as denoting either "Only Nulls exist" or if "Any non-Nulls exist".
References
- Mark Wong (October 10, 2014). "Loading Tables and Creating B-tree and Block Range Indexes". AXLE project.
- Alvaro Herrera (2013-06-14). "Minmax indexes". Pg Hackers.
- "What's new in PostgreSQL 9.5". PostgreSQL.
- "Chapter 62. BRIN Indexes". PostgreSQL 9.5.0 Documentation. 2016.
- Arup Nanda (May–June 2011). "Smart Scans Meet Storage Indexes". Oracle Magazine. Oracle.
- "Understanding Storage Indexes in Oracle Exadata".
- "With Netezza Always Use Integer Join Keys For Good Compression, Zone Maps, And Joins". Netezza. 2010.
- "Data packs". Infobright. Archived from the original on 2009-06-27.
- "Cooperative Scans: Dynamic Bandwidth Sharing in a DBMS". MonetDB. 2007. CiteSeerX 10.1.1.108.2662. Cite journal requires
|journal=(help) - "Hive Optimizations with Indexes, Bloom-Filters and Statistics". Jörn Franke. 2015.
- Herrera, Alvaro (7 November 2014). "commitdiff - BRIN: Block Range Indexes". git.postgresql.org. Retrieved 2017-10-03.
- "When is Exadata's storage indexes used?". OakTable.net.
- Richard Foote (4 October 2012). "Exadata Storage Indexes – Part I".
- Mark Wong (10 March 2015). "PostgreSQL Performance Presentation" (PDF). pp. 7–10.
- "Block Range (BRIN) Indexes in PostgreSQL 9.5". Python Sweetness. May 22, 2015.
- Petr Jelinek (28 November 2014). "Progress on online upgrade". AXLE project.
- Mark Wong (10 October 2014). "Index Overhead on a Growing Table".
- "Oracle Sun Database Machine Application Best Practices for Data Warehousing". Oracle. 1094934.1. Missing or empty
|url=(help) - Marc Fielding (July 20, 2010). "Exadata's Best Kept Secret: Storage Indexes".
- Kerry Osborne (August 10, 2010). "Oracle Exadata – Storage Indexes".
- "AXLE project (Advanced Analytics for Extremely Large European Databases)". 2014.
- "European Union's Seventh Framework Programme (FP7/2007-2013) under grant agreement n° 318633". Missing or empty
|url=(help) - Alvaro Herrera (2014-11-07). "BRIN: Block Range Indexes". PostgreSQL. Retrieved 2016-01-14.
