Burroughs large systems
The Burroughs Large Systems Group produced a family of large 48-bit mainframes using stack machine instruction sets with dense syllables.[NB 1] The first machine in the family was the B5000 in 1961. It was optimized for compiling ALGOL 60 programs extremely well, using single-pass compilers. It evolved into the B5500. Subsequent major redesigns include the B6500/B6700 line and its successors, as well as the separate B8500 line.
In the 1970s, the Burroughs Corporation was organized into three divisions with very different product line architectures for high-end, mid-range, and entry-level business computer systems. Each division's product line grew from a different concept for how to optimize a computer's instruction set for particular programming languages. "Burroughs Large Systems" referred to all of these large-system product lines together, in contrast to the COBOL-optimized Medium Systems (B2000, B3000, and B4000) or the flexible-architecture Small Systems (B1000).
Background
Founded in the 1880s, Burroughs was the oldest continuously operating company in computing (Elliott Brothers was founded before Burroughs, but didn't make computing devices in the 19th century). By the late 1950s its computing equipment was still limited to electromechanical accounting machines such as the Sensimatic. It had nothing to compete with its traditional rivals IBM and NCR, who had started to produce larger-scale computers, or with recently founded Univac. In 1956 they purchased a 3rd party company and rebranded its design as the B205.
Burroughs' first internally developed machine, the B5000, was designed in 1961 and Burroughs sought to address its late entry in the market with the strategy of a completely different design based on the most advanced computing ideas available at the time. While the B5000 architecture is dead, it inspired the B6500 (and subsequent B6700 and B7700). Computers using that architecture were still in production as the Unisys ClearPath Libra servers which run an evolved but compatible version of the MCP operating system first introduced with the B6700. The third and largest line, the B8500,[1][2] had no commercial success. In addition to a proprietary CMOS processor design, Unisys also uses Intel Xeon processors and runs MCP, Microsoft Windows and Linux operating systems on their Libra servers; the use of custom chips was gradually eliminated, and by 2018 the Libra servers had been strictly commodity Intel for some years.
B5000
The first member of the first series, the B5000,[3] was designed beginning in 1961 by a team under the leadership of Robert (Bob) Barton. It was a unique machine, well ahead of its time. It has been listed by the influential computing scientist John Mashey as one of the architectures that he admires the most. "I always thought it was one of the most innovative examples of combined hardware/software design I've seen, and far ahead of its time."[4] The B5000 was succeeded by the B5500[5] (which used disks rather than drum storage) and the B5700 (which allowed multiple CPUs to be clustered around shared disk). While there was no successor to the B5700, the B5000 line heavily influenced the design of the B6500, and Burroughs ported the Master Control Program (MCP) to that machine.
Unique features
- All code automatically reentrant (fig 4.5 from the ACM Monograph shows in a nutshell why): programmers don't have to do anything more to have any code in any language spread across processors than to use just the two shown simple primitives. This is perhaps the canonical but no means the only benefit of these major distinguishing features of this architecture:
- Partially data-driven tagged and descriptor-based design
- Hardware was designed to support software requirements
- Hardware designed to exclusively support high-level programming languages
- No Assembly language or assembler; all system software written in an extended variety of ALGOL 60. However, ESPOL had statements for each of the syllables in the architecture.
- Few programmer accessible registers
- Simplified instruction set
- Stack machine where all operations use the stack rather than explicit operands
- All interrupts and procedure calls use the stack
- Support for high-level operating system (MCP, Master Control Program)
- Support for asymmetric (master/slave) multiprocessing
- Support for other languages such as COBOL
- Powerful string manipulation
- An attempt at a secure architecture prohibiting unauthorized access of data or disruptions to operations[NB 2]
- Early error-detection supporting development and testing of software
- First commercial implementation of virtual memory[NB 3]
First segmented memory model - Successors still exist in the Unisys ClearPath/MCP machines
- Influenced many of today's computing techniques
Unique system design
The B5000 was revolutionary at the time in that the architecture and instruction set were designed with the needs of software taken into consideration. This was a large departure from the computer system design of the time, where a processor and its instruction set would be designed and then handed over to the software people, and is still. That is, most other instruction sets, such as the IBM System/360 instruction set of that era, and later instruction set designs such as the x86, PPC, and ARM instruction set architectures, are essentially traditional instruction set based architectures rather than holistic designs like the original Burroughs systems.
The B5000, B5500 and B5700 in Word Mode has two different addressing modes, depending on whether it is executing a main program (SALF off) or a subroutine (SALF on). For a main program, the T field of an Operand Call or Descriptor Call syllable is relative to the Program Reference Table (PRT). For subroutines, the type of addressing is dependent on the high three bits of T and on the Mark Stack FlipFlop (MSFF), as shown in B5x00 Relative Addressing.
| SALF[lower-alpha 1] | T0 A38 |
T1 A39 |
T2 A40 |
MSFF[lower-alpha 2] | Base | Contents | Index Sign | Index Bits[lower-alpha 3] |
Max Index | |
|---|---|---|---|---|---|---|---|---|---|---|
| OFF | - | - | - | - | R | Address of PRT | + | T 0-9 A 38-47 |
1023 | |
| ON | OFF | - | - | - | R | Address of PRT | + | T 1-9 A 39-47 |
511 | |
| ON | ON | OFF | - | OFF | F | Address of last RCW[lower-alpha 4] or MSCW[lower-alpha 5] on stack | + | T 2-9 A 40-47 |
255 | |
| ON | ON | OFF | - | ON | (R+7)[lower-alpha 6] | F register from MSCW[lower-alpha 5] at PRT+7 | + | T 2-9 A 40-47 |
255 | |
| ON | ON | ON | OFF | - | C[lower-alpha 7] | Address of current instruction word | + | T 3-9 A 41-47 |
127 | |
| ON | ON | ON | ON | OFF | F | Address of last RCW[lower-alpha 4] or MSCW[lower-alpha 5] on stack | - | T 3-9 A 41-47 |
127 | |
| ON | ON | ON | ON | ON | (R+7)[lower-alpha 6] | F register from MSCW[lower-alpha 5] at PRT+7 | - | T 3-9 A 41-47 |
127 | |
Notes:
| ||||||||||
Language support
The B5000 was designed to exclusively support high-level languages. This was at a time when such languages were just coming to prominence with FORTRAN and then COBOL. FORTRAN and COBOL were considered weaker languages by some, when it comes to modern software techniques, so a newer, mostly untried language was adopted, ALGOL-60. The ALGOL dialect chosen for the B5000 was Elliott ALGOL, first designed and implemented by C.A.R. Hoare on an Elliott 503. This was a practical extension of ALGOL with I/O instructions (which ALGOL had ignored) and powerful string processing instructions. Hoare's famous Turing Award lecture was on this subject.
Thus the B5000 was based on a very powerful language. Most other vendors could only dream of implementing an ALGOL compiler and most in the industry dismissed ALGOL as being unimplementable. However, a bright young student named Donald Knuth had previously implemented ALGOL 58 on an earlier Burroughs machine during the three months of his summer break, and he was peripherally involved in the B5000 design as a consultant. Many wrote ALGOL off, mistakenly believing that high-level languages could not have the same power as assembler, and thus not realizing ALGOL's potential as a systems programming language.
The Burroughs ALGOL compiler was very fast — this impressed the Dutch scientist Edsger Dijkstra when he submitted a program to be compiled at the B5000 Pasadena plant. His deck of cards was compiled almost immediately and he immediately wanted several machines for his university, Eindhoven University of Technology in the Netherlands. The compiler was fast for several reasons, but the primary reason was that it was a one-pass compiler. Early computers did not have enough memory to store the source code, so compilers (and even assemblers) usually needed to read the source code more than once. The Burroughs ALGOL syntax, unlike the official language, requires that each variable (or other object) be declared before it is used, so it is feasible to write an ALGOL compiler that reads the data only once. This concept has profound theoretical implications, but it also permits very fast compiling. Burroughs large systems could compile as fast as they could read the source code from the punched cards, and they had the fastest card readers in the industry.
The powerful Burroughs COBOL compiler was also a one-pass compiler and equally fast. A 4000-card COBOL program compiled as fast as the 1000-card/minute readers could read the code. The program was ready to use as soon as the cards went through the reader.
B6500 and B7500
The B6500[7] (delivery in 1969[8][9]) and B7500 were the first computers in the only line of Burroughs systems to survive to the present day. While they were inspired by the B5000, they had a totally new architecture. Among the most important differences were
- The B6500 had variable length instructions with an 8-bit syllable instead of fixed length instructions with a 12-bit syllable.
- The B6500 had a 51-bit[NB 4] instead of a 48-bit word, and used 3 bits as a tag
- The B6500 had Symmetric Multiprocessing (SMP)
- The B6500 had a Saguaro stack
- The B6500 had paged arrays
- The B6500 had Display Registers, D1 thru D32 to allow nested subroutines to access variables in outer blocks.
- The B6500 used monolithic integrated circuits with magnetic thin-film memory.[8]
B6700 and B7700
Among other customers were all five New Zealand universities in 1971.[10]
B8500
The B8500[1][2] line derives from the D825,[11] a military computer that was inspired by the B5000.
The B8500 was designed in the 1960s as an attempt to merge the B5500 and the D825 designs. The system used monolithic integrated circuits with magnetic thin-film memory. The architecture employed a 48-bit word, stack, and descriptors like the B5500, but was not advertised as being upward-compatible.[1] The B8500 could never be gotten to work reliably, and the project was canceled after 1970, never having delivered a completed system.[2]
History
The central concept of virtual memory appeared in the designs of the Ferranti Atlas and the Rice Institute Computer, and the central concepts of descriptors and tagged architecture appeared in the design of the Rice Institute Computer[12] in the late 1950s. However, even if those designs had a direct influence on Burroughs, the architectures of the B5000, B6500 and B8500 were very different from those of the Atlas and the Rice machine; they are also very different from each other.
The first of the Burroughs large systems was the B5000. Designed in 1961, it was a second-generation computer using discrete transistor logic and magnetic core memory. The first machines to replace the B5000 architecture were the B6500 and B7500. The successor machines followed the hardware development trends to re-implement the architectures in new logic over the next 25 years, with the B5500, B6500, B5700, B6700, B7700, B6800, B7800, and finally the Burroughs A series. After a merger in which Burroughs acquired Sperry Corporation and changed its name to Unisys, the company continued to develop new machines based on the MCP CMOS ASIC. These machines were the Libra 100 through the Libra 500, With the Libra 590 being announced in 2005. Later Libras, including the 590, also incorporate Intel Xeon processors and can run the Burroughs large systems architecture in emulation as well as on the MCP CMOS processors. It is unclear if Unisys will continue development of new MCP CMOS ASICs.
| Burroughs (1961–1986) | |||
|---|---|---|---|
| B5000 | 1961 | initial system, 2nd generation (transistor) computer | |
| B5500 | 1964 | 3x speed improvement[2][13] | |
| B6500 | 1969 | 3rd generation computer (integrated circuits), up to 4 processors | |
| B5700 | 1971 | new name for B5500 | |
| B6700 | 1971 | new name/bug fix for B6500 | |
| B7700 | 1972 | faster processor, cache for stack, up to 8 requestors (I/O or Central processors) in one or two partitions. | |
| B6800 | 1977? | semiconductor memory, NUMA architecture | |
| B7800 | 1977? | semiconductor memory, faster, up to 8 requestors (I/O or Central processors) in one or two partitions. | |
| B5900 | 1980? | semiconductor memory, NUMA architecture. Max of 4 B5900 CPUs bound to a local memory and a common Global Memory II (tm) | |
| B6900 | 1979? | semiconductor memory, NUMA architecture. Max of 4 B6900 CPUs bound to a local memory and a common Global Memory(tm) | |
| B7900 | 1982? | semiconductor memory, faster, code & data caches, NUMA architecture,
1-2 HDUs (I/O), 1-2 APs, 1-4 CPUs, Soft implementation of NUMA memory allowed CPUs to float from memory space to memory space. | |
| A9/A10 | 1984 | B6000 class, First pipelined processor in the mid-range, single CPU (dual on A10), First to support eMode Beta (expanded Memory Addressing) | |
| A12/A15 | 1985 | B7000 class, Re-implemented in custom-designed Motorola ECL MCA1, then MCA2 gate arrays, single CPU single HDU (A12) 1–4 CPU, 1–2 HDU (A15) | |
| Unisys (1986–present) | |||
| Micro A | 1989 | desktop "mainframe" with single-chip SCAMP[14][15] processor. | |
| Clearpath HMP NX 4000 | 198? | ?? | |
| Clearpath HMP NX 5000 | 199? | ?? | |
| Clearpath HMP LX 5000 | 1998 | Implements Burroughs Large systems in emulation only (Xeon processors)[16] | |
| Libra 100 | 2002? | ?? | |
| Libra 200 | 200? | ?? | |
| Libra 300 | 200? | ?? | |
| Libra 400 | 200? | ?? | |
| Libra 500 | 2005? | e.g. Libra 595[17] | |
| Libra 600 | 2006? | ?? | |
| Libra 700 | 2010 | e.g. Libra 750[18] | |
Primary lines of hardware
Hardware and software design, development, and manufacturing were split between two primary locations, in Orange County, California, and the outskirts of Philadelphia. The initial Large Systems Plant, which developed the B5000 and B5500, was located in Pasadena, California but moved to City of Industry, California, where it developed the B6500. The Orange County location, which was based in a plant in Mission Viejo, California but at times included facilities in nearby Irvine and Lake Forest, was responsible for the smaller B6x00 line, while the East Coast operations, based in Tredyffrin, Pennsylvania, handled the larger B7x00 line. All machines from both lines were fully object-compatible, meaning a program compiled on one could be executed on another. Newer and larger models had instructions which were not supported on older and slower models, but the hardware, when encountering an unrecognized instruction, invoked an operating system function which interpreted it. Other differences include how process switching and I/O were handled, and maintenance and cold-starting functionality. Larger systems included hardware process scheduling and more capable input/output modules, and more highly functional maintenance processors. When the Bxx00 models were replaced by the A Series models, the differences were retained but no longer readily identifiable by model number.
ALGOL
| Paradigms | Multi-paradigm: procedural, imperative, structured |
|---|---|
| Family | ALGOL |
| Designed by | John McClintock, others |
| Developer | Burroughs Corporation |
| First appeared | 1962 |
| Platform | Burroughs large systems |
| OS | Burroughs MCP |
| Influenced by | |
| ALGOL 60 | |
| Influenced | |
| ESPOL, MCP, NEWP | |
The Burroughs large systems implement an ALGOL-derived stack architecture. The B5000 was the first stack-based system.
While B5000 was specifically designed to support ALGOL, this was only a starting point. Other business-oriented languages such as COBOL were also well supported, most notably by the powerful string operators which were included for the development of fast compilers.
The ALGOL used on the B5000 is an extended ALGOL subset. It includes powerful string manipulation instructions but excludes certain ALGOL constructs, notably unspecified formal parameters. A DEFINE mechanism serves a similar purpose to the #defines found in C, but is fully integrated into the language rather than being a preprocessor. The EVENT data type facilitates coordination between processes, and ON FAULT blocks enable handling program faults.
The user level of ALGOL does not include many of the insecure constructs needed by the operating system and other system software. Two levels of language extensions provide the additional constructs: ESPOL and NEWP for writing the MCP and closely related software, and DCALGOL and DMALGOL to provide more specific extensions for specific kinds of system software.
ESPOL and NEWP
Originally, the B5000 MCP operating system was written in an extension of extended ALGOL called ESPOL (Executive Systems Programming Oriented Language). This was replaced in the mid-to-late 70s by a language called NEWP. Though NEWP probably just meant "New Programming language", legends surround the name. A common (perhaps apocryphal) story within Burroughs at the time suggested it came from “No Executive Washroom Privileges.” Another story is that circa 1976, John McClintock of Burroughs (the software engineer developing NEWP) named the language "NEWP" after being asked, yet again, "does it have a name yet": answering "nyoooop", he adopted that as a name. NEWP, too, was a subset ALGOL extension, but it was more secure than ESPOL, and dropped some little-used complexities of ALGOL. In fact, all unsafe constructs are rejected by the NEWP compiler unless a block is specifically marked to allow those instructions. Such marking of blocks provide a multi-level protection mechanism.
NEWP programs that contain unsafe constructs are initially non-executable. The security administrator of a system is able to "bless" such programs and make them executable, but normal users are not able to do this. (Even "privileged users", who normally have essentially root privilege, may be unable to do this depending on the configuration chosen by the site.) While NEWP can be used to write general programs and has a number of features designed for large software projects, it does not support everything ALGOL does.
NEWP has a number of facilities to enable large-scale software projects, such as the operating system, including named interfaces (functions and data), groups of interfaces, modules, and super-modules. Modules group data and functions together, allowing easy access to the data as global within the module. Interfaces allow a module to import and export functions and data. Super-modules allow modules to be grouped.
DCALGOL and Message Control Systems (MCS)
The second intermediate level of security between operating system code (in NEWP) and user programs (in ALGOL) is for middleware programs, which are written in DCALGOL (data comms ALGOL). This is used for message reception and dispatching which remove messages from input queues and places them on queues for other processes in the system to handle. Middleware such as COMS (introduced around 1984) receive messages from around the network and dispatch these messages to specific handling processes or to an MCS (Message Control System) such as CANDE ("Command AND Edit," the program development environment).
MCSs are items of software worth noting – they control user sessions and provide keeping track of user state without having to run per-user processes since a single MCS stack can be shared by many users. Load balancing can also be achieved at the MCS level. For example, saying that you want to handle 30 users per stack, in which case if you have 31 to 60 users, you have two stacks, 61 to 90 users, three stacks, etc. This gives B5000 machines a great performance advantage in a server since you don't need to start up another user process and thus create a new stack each time a user attaches to the system. Thus you can efficiently service users (whether they require state or not) with MCSs. MCSs also provide the backbone of large-scale transaction processing.
The MCS talked with an external co-processor, the DCP (Datacomm Control Processor). This was a 24-bit minicomputer with a conventional register architecture and hardware I/O capability to handle thousands of remote terminals. The DCP and the B6500 communicated by messages in memory, essentially packets in today's terms, and the MCS did the B6500-side processing of those messages. In the early years the DCP did have an assembler (Dacoma), an application program called DCPProgen written in B6500 ALGOL. Later the NDL (Network Definition Language) compiler generated the DCP code and NDF (network definition file). There was one ALGOL function for each kind of DCP instruction, and if you called that function then the corresponding DCP instruction bits would be emitted to the output. A DCP program was an ALGOL program comprising nothing but a long list of calls on these functions, one for each assembly language statement. Essentially ALGOL acted like the macro pass of a macro assembler. The first pass was the ALGOL compiler; the second pass was running the resulting program (on the B6500) which would then emit the binary for the DCP.
DMALGOL and databases
Another variant of ALGOL is DMALGOL (Data Management ALGOL). DMALGOL is ALGOL extended for compiling the DMSII database software from database description files created by the DASDL (Data Access and Structure Definition Language) compiler. Database designers and administrators compile database descriptions to generate DMALGOL code tailored for the tables and indexes specified. Administrators never need to write DMALGOL themselves. Normal user-level programs obtain database access by using code written in application languages, mainly ALGOL and COBOL, extended with database instructions and transaction processing directives. The most notable feature of DMALGOL is its preprocessing mechanisms to generate code for handling tables and indices.
DMALGOL preprocessing includes variables and loops, and can generate names based on compile-time variables. This enables tailoring far beyond what can be done by preprocessing facilities which lack loops.
DMALGOL is used to provide tailored access routines for DMSII databases. After a database is defined using the Data Access and Structure Definition Language (DASDL), the schema is translated by the preprocessor into tailored DMALGOL access routines and then compiled. This means that, unlike in other DBMS implementations, there is often no need for database-specific if/then/else code at run-time. In the 1970s, this "tailoring" was used very extensively to reduce the code footprint and execution time. It became much less used in later years, partly because low-level fine tuning for memory and speed became less critical, and partly because eliminating the preprocessing made coding simpler and thus enabled more important optimizations. DMALGOL included verbs like "find", "lock", "store". Also the verbs "begintransaction" and "endtransaction" were included, solving the deadlock situation when multiple processes accessed and updated the same structures.
Roy Guck of Burroughs was one of the main developers of DMSII.
In later years, with compiler code size being less of a concern, most of the preprocessing constructs were made available in the user level of ALGOL. Only the unsafe constructs and the direct processing of the database description file remain restricted to DMALGOL.
Stack architecture
In many early systems and languages, programmers were often told not to make their routines too small. Procedure calls and returns were expensive, because a number of operations had to be performed to maintain the stack. The B5000 was designed as a stack machine – all program data except for arrays (which include strings and objects) was kept on the stack. This meant that stack operations were optimized for efficiency. As a stack-oriented machine, there are no programmer addressable registers.
Multitasking is also very efficient on the B5000 and B6500 lines. There are specific instruction to perform process switches:
- B5000, B5500, B5700
- Initiate P1 (IP1) and Initiate P2 (IP2)[5]:6–30
- B6500, B7500 and successors
- MVST (move stack).[7]:8–19[19]
Each stack and associated[NB 5] Program Reference Table (PRT) represents a process (task or thread) and tasks can become blocked waiting on resource requests (which includes waiting for a processor to run on if the task has been interrupted because of preemptive multitasking). User programs cannot issue an IP1,[NB 5] IP2[NB 5] or MVST,[NB 6] and there is only one place in the operating system where this is done.
So a process switch proceeds something like this – a process requests a resource that is not immediately available, maybe a read of a record of a file from a block which is not currently in memory, or the system timer has triggered an interrupt. The operating system code is entered and run on top of the user stack. It turns off user process timers. The current process is placed in the appropriate queue for the resource being requested, or the ready queue waiting for the processor if this is a preemptive context switch. The operating system determines the first process in the ready queue and invokes the instruction move_stack, which makes the process at the head of the ready queue active.
Stack speed and performance
Some of the detractors of the B5000 architecture believed that stack architecture was inherently slow compared to register-based architectures. The trick to system speed is to keep data as close to the processor as possible. In the B5000 stack, this was done by assigning the top two positions of the stack to two registers A and B. Most operations are performed on those two top of stack positions. On faster machines past the B5000, more of the stack may be kept in registers or cache near the processor.
Thus the designers of the current successors to the B5000 systems can optimize in whatever is the latest technique, and programmers do not have to adjust their code for it to run faster – they do not even need to recompile, thus protecting software investment. Some programs have been known to run for years over many processor upgrades. Such speed up is limited on register-based machines.
Another point for speed as promoted by the RISC designers was that processor speed is considerably faster if everything is on a single chip. It was a valid point in the 1970s when more complex architectures such as the B5000 required too many transistors to fit on a single chip. However, this is not the case today and every B5000 successor machine now fits on a single chip as well as the performance support techniques such as caches and instruction pipelines.
In fact, the A Series line of B5000 successors included the first single chip mainframe, the Micro-A of the late 1980s. This "mainframe" chip (named SCAMP for Single-Chip A-series Mainframe Processor) sat on an Intel-based plug-in PC board.
How programs map to the stack
Here is an example of how programs map to the stack structure
begin
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
— This is lexical level 2 (level zero is reserved for the operating system and level 1 for code segments).
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
— At level 2 we place global variables for our program.
integer i, j, k;
real f, g;
array a [0:9];
procedure p (real p1, p2);
value p1; — p1 passed by value, p2 implicitly passed by reference.
begin
— — — — — — — — — — — — — — — — — —
— This block is at lexical level 3
— — — — — — — — — — — — — — — — — —
real r1, r2;
r2 := p1 * 5;
p2 := r2; — This sets g to the value of r2
p1 := r2; — This sets p1 to r2, but not f
— Since this overwrites the original value of f in p1 it might be a
— coding mistake. Some few of ALGOL's successors therefore insist that
— value parameters be read only – but most do not.
if r2 > 10 then
begin
— — — — — — — — — — — — — — — — — — — — — — — — — — — —
— A variable declared here makes this lexical level 4
— — — — — — — — — — — — — — — — — — — — — — — — — — — —
integer n;
— The declaration of a variable makes this a block, which will invoke some
— stack building code. Normally you won't declare variables here, in which
— case this would be a compound statement, not a block.
... <== sample stack is executing somewhere here.
end;
end;
.....
p (f, g);
end.
Each stack frame corresponds to a lexical level in the current execution environment. As you can see, lexical level is the static textual nesting of a program, not the dynamic call nesting. The visibility rules of ALGOL, a language designed for single pass compilers, mean that only variables declared before the current position are visible at that part of the code, thus the requirement for forward declarations. All variables declared in enclosing blocks are visible. Another case is that variables of the same name may be declared in inner blocks and these effectively hide the outer variables which become inaccessible.
Lexical nesting is static, unrelated to execution nesting with recursion, etc. so it is very rare to find a procedure nested more than five levels deep, and it could be argued that such programs would be poorly structured. B5000 machines allow nesting of up to 32 levels. This could cause difficulty for some systems that generated Algol source as output (tailored to solve some special problem) if the generation method frequently nested procedure within procedure.
Procedures
Procedures can be invoked in four ways – normal, call, process, and run.
The normal invocation invokes a procedure in the normal way any language invokes a routine, by suspending the calling routine until the invoked procedure returns.
The call mechanism invokes a procedure as a coroutine. Coroutines have partner tasks, where control is explicitly passed between the tasks by means of a CONTINUE instruction. These are synchronous processes.
The process mechanism invokes a procedure as an asynchronous task and in this case a separate stack is set up starting at the lexical level of the processed procedure. As an asynchronous task, there is no control over exactly when control will be passed between the tasks, unlike coroutines. The processed procedure still has access to the enclosing environment and this is a very efficient IPC (Inter Process Communication) mechanism. Since two or more tasks now have access to common variables, the tasks must be synchronized to prevent race conditions, which is handled by the EVENT data type, where processes can WAIT on an event until they are caused by another cooperating process. EVENTs also allow for mutual exclusion synchronization through the PROCURE and LIBERATE functions. If for any reason the child task dies, the calling task can continue – however, if the parent process dies, then all child processes are automatically terminated. On a machine with more than one processor, the processes may run simultaneously. This EVENT mechanism is a basic enabler for multiprocessing in addition to multitasking.
Run invocation type
The last invocation type is run. This runs a procedure as an independent task which can continue on after the originating process terminates. For this reason, the child process cannot access variables in the parent's environment, and all parameters passed to the invoked procedure must be call-by-value.
Thus Burroughs Extended ALGOL had some of the multi-processing and synchronization features of later languages like Ada. It made use of the support for asynchronous processes that was built into the hardware.
Inline procedures
One last possibility is that a procedure may be declared INLINE, that is when the compiler sees a reference to it the code for the procedure is generated inline to save the overhead of a procedure call; this is best done for small pieces of code. Inline functions are similar to parameterized macros such as C #defines, except you don't get the problems with parameters that you can with macros. This facility is available in NEWP.
Asynchronous calls
In the example program only normal calls are used, so all the information will be on a single stack. For asynchronous calls, the stack would be split into multiple stacks so that the processes share data but run asynchronously.
Display registers
A stack hardware optimization is the provision of D (or "display") registers. These are registers that point to the start of each called stack frame. These registers are updated automatically as procedures are entered and exited and are not accessible by any software. There are 32 D registers, which is what limits to 32 levels of lexical nesting.
Consider how we would access a lexical level 2 (D[2]) global variable from lexical level 5 (D[5]). Suppose the variable is 6 words away from the base of lexical level 2. It is thus represented by the address couple (2, 6). If we don't have D registers, we have to look at the control word at the base of the D[5] frame, which points to the frame containing the D[4] environment. We then look at the control word at the base of this environment to find the D[3] environment, and continue in this fashion until we have followed all the links back to the required lexical level. This is not the same path as the return path back through the procedures which have been called in order to get to this point. (The architecture keeps both the data stack and the call stack in the same structure, but uses control words to tell them apart.)
As you can see, this is quite inefficient just to access a variable. With D registers, the D[2] register points at the base of the lexical level 2 environment, and all we need to do to generate the address of the variable is to add its offset from the stack frame base to the frame base address in the D register. (There is an efficient linked list search operator LLLU, which could search the stack in the above fashion, but the D register approach is still going to be faster.) With D registers, access to entities in outer and global environments is just as efficient as local variable access.
D Tag Data — Address couple, Comments register
| 0 | n | (4, 1) The integer n (declared on entry to a block, not a procedure) |-----------------------| | D[4]==>3 | MSCW | (4, 0) The Mark Stack Control Word containing the link to D[3]. |=======================| | 0 | r2 | (3, 5) The real r2 |-----------------------| | 0 | r1 | (3, 4) The real r1 |-----------------------| | 1 | p2 | (3, 3) A SIRW reference to g at (2,6) |-----------------------| | 0 | p1 | (3, 2) The parameter p1 from value of f |-----------------------| | 3 | RCW | (3, 1) A return control word |-----------------------| | D[3]==>3 | MSCW | (3, 0) The Mark Stack Control Word containing the link to D[2]. |=======================| | 1 | a | (2, 7) The array a ======>[ten word memory block] |-----------------------| | 0 | g | (2, 6) The real g |-----------------------| | 0 | f | (2, 5) The real f |-----------------------| | 0 | k | (2, 4) The integer k |-----------------------| | 0 | j | (2, 3) The integer j |-----------------------| | 0 | i | (2, 2) The integer i |-----------------------| | 3 | RCW | (2, 1) A return control word |-----------------------| | D[2]==>3 | MSCW | (2, 0) The Mark Stack Control Word containing the link to the previous stack frame. |=======================| — Stack bottom
If we had invoked the procedure p as a coroutine, or a process instruction, the D[3] environment would have become a separate D[3]-based stack. This means that asynchronous processes still have access to the D[2] environment as implied in ALGOL program code. Taking this one step further, a totally different program could call another program’s code, creating a D[3] stack frame pointing to another process’ D[2] environment on top of its own process stack. At an instant the whole address space from the code’s execution environment changes, making the D[2] environment on the own process stack not directly addressable and instead make the D[2] environment in another process stack directly addressable. This is how library calls are implemented. At such a cross-stack call, the calling code and called code could even originate from programs written in different source languages and be compiled by different compilers.
The D[1] and D[0] environments do not occur in the current process's stack. The D[1] environment is the code segment dictionary, which is shared by all processes running the same code. The D[0] environment represents entities exported by the operating system.
Stack frames actually don’t even have to exist in a process stack. This feature was used early on for file I/O optimization, the FIB (file information block) was linked into the display registers at D[1] during I/O operations. In the early nineties, this ability was implemented as a language feature as STRUCTURE BLOCKs and – combined with library technology - as CONNECTION BLOCKs. The ability to link a data structure into the display register address scope implemented object orientation. Thus, the B5000 actually used a form of object orientation long before the term was ever used.
On other systems, the compiler might build its symbol table in a similar manner, but eventually the storage requirements would be collated and the machine code would be written to use flat memory addresses of 16-bits or 32-bits or even 64-bits. These addresses might contain anything so that a write to the wrong address could damage anything. Instead, the two-part address scheme was implemented by the hardware. At each lexical level, variables were placed at displacements up from the base of the level's stack, typically occupying one word - double precision or complex variables would occupy two. Arrays were not stored in this area, only a one word descriptor for the array was. Thus, at each lexical level the total storage requirement was not great: dozens, hundreds or a few thousand in extreme cases, certainly not a count requiring 32-bits or more. And indeed, this was reflected in the form of the VALC instruction (value call) that loaded an operand onto the stack. This op-code was two bits long and the rest of the byte's bits were concatenated with the following byte to give a fourteen-bit addressing field. The code being executed would be at some lexical level, say six: this meant that only lexical levels zero to six were valid, and so just three bits were needed to specify the lexical level desired. The address part of the VALC operation thus reserved just three bits for that purpose, with the remainder being available for referring to entities at that and lower levels. A deeply nested procedure (thus at a high lexical level) would have fewer bits available to identify entities: for level sixteen upwards five bits would be needed to specify the choice of levels 0–31 thus leaving nine bits to identify no more than the first 512 entities of any lexical level. This is much more compact than addressing entities by their literal memory address in a 32-bit addressing space. Further, only the VALC opcode loaded data: opcodes for ADD, MULT and so forth did no addressing, working entirely on the top elements of the stack.
Much more important is that this method meant that many errors available to systems employing flat addressing could not occur because they were simply unspeakable even at the machine code level. A task had no way to corrupt memory in use by another task, because it had no way to develop its address. Offsets from a specified D-register would be checked by the hardware against the stack frame bound: rogue values would be trapped. Similarly, within a task, an array descriptor contained information on the array's bounds, and so any indexing operation was checked by the hardware: put another way, each array formed its own address space. In any case, the tagging of all memory words provided a second level of protection: a misdirected assignment of a value could only go to a data-holding location, not to one holding a pointer or an array descriptor, etc. and certainly not to a location holding machine code.
Array storage
Arrays were not stored contiguous in memory with other variables, they were each granted their own address space, which was located via the descriptor. The access mechanism was to calculate on the stack the index variable (which therefore had the full integer range potential, not just fourteen bits) and use it as the offset into the array's address space, with bound checking provided by the hardware. Should an array's length exceed 1,024 words, the array would be segmented, and the index be converted into a segment index and an offset into the indexed segment. In ALGOL's case, a multidimensional array would employ multiple levels of such addressing. For a reference to A(i,j), the first index would be into an array of descriptors, one descriptor for each of the rows of A, which row would then be indexed with j as for a single-dimensional array, and so on for higher dimensions. Hardware checking against the known bounds of all the array's indices would prevent erroneous indexing.
FORTRAN however regards all multidimensional arrays as being equivalent to a single-dimensional array of the same size, and for a multidimensional array simple integer arithmetic is used to calculate the offset where element A(i,j,k) would be found in that single sequence. The single-dimensional equivalent array, possibly segmented if large enough, would then be accessed in the same manner as a single-dimensional array in ALGOL. Although accessing outside this array would be prevented, a wrong value for one index combined with a suitably wrong value for another index might not result in a bounds violation of the single sequence array; in other words, the indices were not checked individually.
Because an array's storage was not bounded on each side by storage for other items, it was easy for the system to "resize" an array - though changing the number of dimensions was precluded because compilers required all references to have the same number of dimensions. In ALGOL's case, this enabled the development of "ragged" arrays, rather than the usual fixed rectangular (or higher dimension) arrays. Thus in two dimensions, a ragged array would have rows that were of different sizes. For instance, given a large array A(100,100) of mostly-zero values, a sparse array representation that was declared as SA(100,0) could have each row resized to have exactly enough elements to hold only the non-zero values of A along that row.
Because arrays larger than 1024 words were segmented but smaller arrays were not, on a system that was short of real memory, increasing the declared size of a collection of scratchpad arrays from 1,000 to say 1,050 could mean that the program would run with far less "thrashing" as only the smaller individual segments in use were needed in memory. Actual storage for an array segment would be allocated at run time only if an element in that segment were accessed, and all elements of a created segment would be initialised to zero. Not initialising an array to zero at the start therefore was encouraged by this, normally an unwise omission.
Stack structure advantages
One nice thing about the stack structure is that if a program does happen to fail, a stack dump is taken and it is very easy for a programmer to find out exactly what the state of a running program was. Compare that to core dumps and exchange packages of other systems.
Another thing about the stack structure is that programs are implicitly recursive. FORTRAN was not expected to support recursion and perhaps one stumbling block to people's understanding of how ALGOL was to be implemented was how to implement recursion. On the B5000, this was not a problem – in fact, they had the reverse problem, how to stop programs from being recursive. In the end they didn't bother. The Burroughs FORTRAN compiler allowed recursive calls (just as every other FORTRAN compiler does), but unlike many other computers, on a stack-based system the returns from such calls succeeded as well. This could have odd effects, as with a system for the formal manipulation of mathematical expressions whose central subroutines repeatedly invoked each other without ever returning: large jobs were ended by stack overflow!
Thus Burroughs FORTRAN had better error checking than other contemporary implementation of FORTRAN. For instance, for subroutines and functions it checked that they were invoked with the correct number of parameters, as is normal for ALGOL-style compilers. On other computers, such mismatches were common causes of crashes. Similarly with the array-bound checking: programs that had been used for years on other systems embarrassingly often would fail when run on a Burroughs system. In fact, Burroughs became known for its superior compilers and implementation of languages, including the object-oriented Simula (a superset of ALGOL), and Iverson, the designer of APL declared that the Burroughs implementation of APL was the best he'd seen. John McCarthy, the language designer of LISP disagreed, since LISP was based on modifiable code, he did not like the unmodifiable code of the B5000, but most LISP implementations would run in an interpretive environment anyway.
The storage required for the multiple processes came from the system's memory pool as needed. There was no need to do SYSGENs on Burroughs systems as with competing systems in order to preconfigure memory partitions in which to run tasks.
Tagged architecture
The most defining aspect of the B5000 is that it is a stack machine as treated above. However, two other very important features of the architecture is that it is tag-based and descriptor-based.
In the original B5000, a flag bit in each control or numeric word[NB 7] was set aside to identify the word as a control word or numeric word. This was partially a security mechanism to stop programs from being able to corrupt control words on the stack.
Later, when the B6500 was designed, it was realized that the 1-bit control word/numeric distinction was a powerful idea and this was extended to three bits outside of the 48 bit word into a tag. The data bits are bits 0–47 and the tag is in bits 48–50. Bit 48 was the read-only bit, thus odd tags indicated control words that could not be written by a user-level program. Code words were given tag 3. Here is a list of the tags and their function:
| Tag | Word kind | Description |
|---|---|---|
| 0 | Data | All kinds of user and system data (text data and single precision numbers) |
| 2 | Double | Double Precision data |
| 4 | SIW | Step Index word (used in loops) |
| 6 | Uninitialized data | |
| SCW | Software Control Word (used to cut back the stack) | |
| 1 | IRW | Indirect Reference Word |
| SIRW | Stuffed Indirect Reference Word | |
| 3 | Code | Program code word |
| MSCW | Mark Stack Control Word | |
| RCW | Return Control Word | |
| TOSCW | Top of Stack Control Word | |
| SD | Segment Descriptor | |
| 5 | Descriptor | Data block descriptors |
| 7 | PCW | Program Control Word |
Internally, some of the machines had 60 bit words, with the extra bits being used for engineering purposes such as a Hamming code error-correction field, but these were never seen by programmers.
The current incarnation of these machines, the Unisys ClearPath has extended tags further into a four bit tag. The microcode level that specified four bit tags was referred to as level Gamma.
Even-tagged words are user data which can be modified by a user program as user state. Odd-tagged words are created and used directly by the hardware and represent a program's execution state. Since these words are created and consumed by specific instructions or the hardware, the exact format of these words can change between hardware implementation and user programs do not need to be recompiled, since the same code stream will produce the same results, even though system word format may have changed.
Tag 1 words represent on-stack data addresses. The normal IRW simply stores an address couple to data on the current stack. The SIRW references data on any stack by including a stack number in the address.
Tag 5 words are descriptors, which are more fully described in the next section. Tag 5 words represent off-stack data addresses.
Tag 7 is the program control word which describes a procedure entry point. When operators hit a PCW, the procedure is entered. The ENTR operator explicitly enters a procedure (non-value-returning routine). Functions (value-returning routines) are implicitly entered by operators such as value call (VALC). Global routines are stored in the D[2] environment as SIRWs that point to a PCW stored in the code segment dictionary in the D[1] environment. The D[1] environment is not stored on the current stack because it can be referenced by all processes sharing this code. Thus code is reentrant and shared.
Tag 3 represents code words themselves, which won't occur on the stack. Tag 3 is also used for the stack control words MSCW, RCW, TOSCW.

Descriptor-based architecture
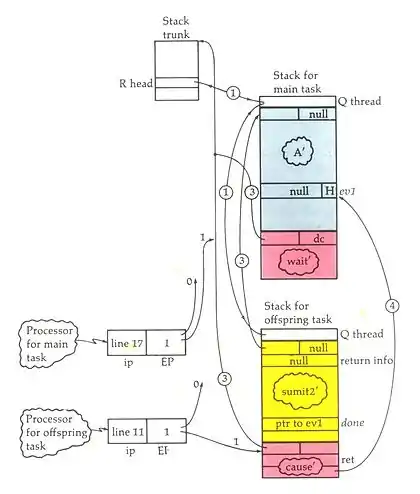
The figure to the left shows how the Burroughs Large System architecture was fundamentally a hardware architecture for object-oriented programming, something that still doesn't exist in conventional architectures.
Instruction sets
There are three distinct instruction sets for the Burroughs large systems. All three are based on short syllables that fit evenly into words.
B5000, B5500 and B5700
Programs on a B5000, B5500 and B5700 are made up of 12-bit syllables, four to a word. The architecture has two modes, Word Mode and Character Mode, and each has a separate repertoire of syllables. A processor may be either Control State or Normal State, and certain syllables are only permissible in Control State. The architecture does not provide for addressing registers or storage directly; all references are through the 1024 word Program Reference Table, current code segment, marked locations within the stack or to the A and B registers holding the top two locations on the stack. Burroughs numbers bits in a syllable from 0 (high bit) to 11 (low bit)
B6500, B7500 and successors
Programs are made up of 8-bit syllables, which may be Name Call, be Value Call or form an operator, which may be from one to twelve syllables in length. There are less than 200 operators, all of which fit into 8-bit syllables. Many of these operators are polymorphic depending on the kind of data being acted on as given by the tag. If we ignore the powerful string scanning, transfer, and edit operators, the basic set is only about 120 operators. If we remove the operators reserved for the operating system such as MVST and HALT, the set of operators commonly used by user-level programs is less than 100. The Name Call and Value Call syllables contain address couples; the Operator syllables either use no addresses or use control words and descriptors on the stack.
Multiple processors
The B5000 line also were pioneers in having multiple processors connected together on a high-speed bus. The B7000 line could have up to eight processors, as long as at least one was an I/O module. RDLK is a very low-level way of synchronizing between processors. The high level used by user programs is the EVENT data type. The EVENT data type did have some system overhead. To avoid this overhead, a special locking technique called Dahm locks (named after a Burroughs software guru, Dave Dahm) can be used.
Notable operators are:
HEYU — send an interrupt to another processor
RDLK — Low-level semaphore operator: Load the A register with the memory location given by the A register and place the value in the B register at that memory location in a single uninterruptible cycle. The Algol compiler produced code to invoke this operator via a special function that enabled a "swap" operation on single-word data without an explicit temporary value. x:=RDLK(x,y);
WHOI — Processor identification
IDLE — Idle until an interrupt is received
Two processors could infrequently simultaneously send each other a 'HEYU' command resulting in a lockup known as 'a deadly embrace'.
Influence of the B5000
The direct influence of the B5000 can be seen in the current Unisys ClearPath range of mainframes which are the direct descendants of the B5000 and still have the MCP operating system after 40 years of consistent development. This architecture is now called emode (for emulation mode) since the B5000 architecture has been implemented on machines built from Intel Xeon processors running the x86 instruction set as the native instruction set, with code running on those processors emulating the B5000 instruction set. In those machines, there was also going to be an nmode (native mode), but this was dropped, so you may often hear the B5000 successor machines being referred to as "emode machines".
B5000 machines were programmed exclusively in high-level languages; there is no assembler.
The B5000 stack architecture inspired Chuck Moore, the designer of the programming language Forth, who encountered the B5500 while at MIT. In Forth - The Early Years, Moore described the influence, noting that Forth's DUP, DROP and SWAP came from the corresponding B5500 instructions (DUPL, DLET, EXCH).
B5000 machines with their stack-based architecture and tagged memory also heavily influenced the Soviet Elbrus series of mainframes and supercomputers. The first two generations of the series featured tagged memory and stack-based CPUs that were programmed only in high-level languages. There existed a kind of an assembly language for them, called El-76, but it was more or less a modification of ALGOL 68 and supported structured programming and first-class procedures. Later generations of the series, though, switched away from this architecture to the EPIC-like VLIW CPUs.
The Hewlett-Packard designers of the HP 3000 business system had used a B5500 and were greatly impressed by its hardware and software; they aimed to build a 16-bit minicomputer with similar software. Several other HP divisions created similar minicomputer or microprocessor stack machines. Bob Barton's work on reverse Polish notation (RPN) also found its way into HP calculators beginning with the 9100A, and notably the HP-35 and subsequent calculators.
The NonStop systems designed by Tandem Computers in the late 1970s and early 1980s were also 16-bit stack machines, influenced by the B5000 indirectly through the HP 3000 connection, as several of the early Tandem engineers were formerly with HP. Around 1990, these systems migrated to MIPS RISC architecture but continued to support execution of stack machine binaries by object code translation or direct emulation. Sometime after 2000, these systems migrated to Itanium architecture and continued to run the legacy stack machine binaries.
Bob Barton was also very influential on Alan Kay. Kay was also impressed by the data-driven tagged architecture of the B5000 and this influenced his thinking in his developments in object-oriented programming and Smalltalk.
Another facet of the B5000 architecture was that it was a secure architecture that runs directly on hardware. This technique has descendants in the virtual machines of today in their attempts to provide secure environments. One notable such product is the Java JVM which provides a secure sandbox in which applications run.
The value of the hardware-architecture binding that existed before emode would be substantially preserved in the x86-based machines to the extent that MCP was the one and only control program, but the support provided by those machines is still inferior to that provided on the machines where the B5000 instruction set is the native instruction set. A little-known Intel processor architecture that actually preceded 32-bit implementations of the x86 instruction set, the Intel iAPX 432, would have provided an equivalent physical basis, as it too was essentially an object-oriented architecture.
See also
Notes
- E.g., 12-bit syllables for B5000, 8-bit syllables for B6500
- There were security issues
- Unless you counted the Ferranti Atlas as a commercial machine.
- Not counting error controls
- Only for B5000, B5500 and B5700
- Only for B6500, B7500 and successors
- There was no flag bit in words containing character data or code
References
- The Extended ALGOL Primer (Three Volumes), Donald J. Gregory.
- Computer Architecture: A Structured Approach, R. Doran, Academic Press (1979).
- Stack Computers: The New Wave, Philip J. Koopman, available at:
- B5500, B6500, B6700, B6800, B6900, B7700 manuals at: bitsavers.org
- John T. Lynch (August 1965), "The Burroughs B8500" (PDF), Datamation: 49–50
- George Gray (October 1999), "Burroughs Third-Generation Computers", Unisys History Newsletter, 3 (5), archived from the original on September 26, 2017
- Burroughs (1963), The Operational Characteristics of the Processors for the Burroughs B5000 (PDF), Revision A, 5000-21005
- John Mashey (2006-08-15). "Admired designs / designs to study". Newsgroup: comp.arch. Usenet: 1155671202.964792.162180@b28g2000cwb.googlegroups.com. Retrieved 2007-12-15.
- Burroughs (May 1967), Burroughs B5500 Information Processing System Reference Manual (PDF), 1021326
- Taken from "Table 5-1 Relative Addressing Table". Burroughs B5500 Information Processing Systems Reference Manual (PDF). Systems Documentation. Burroughs Corporation. May 1967. p. 5-4. 1021326.
- Burroughs B6500 Information Processing System Reference Manual (PDF), Burroughs, September 1969, 1043676
- "Historical Narrative The 1960s; US vs IBM, Exhibit 14971, Part 2". ed-thelen.org. US Government. July 22, 1980. p. 648 (409). Retrieved February 21, 2019. Alt URL
- Burroughs Corporation (1969), Burroughs B6500 Status Report (film), Nigel Williams (published 2015-08-08), Timecode: 1969 status - 0:00-0:52, 6:04-7:01, 8:14; date - 3:40, 4:21, retrieved 2019-03-04
- Shipments rate, first 16 computers: burroughs :: B6500 6700 :: CUBE XVI B6500 Status Apr70. Apr 1970. pp. 1–2.
- "Computing History Displays: Fourth Floor". University of Auckland. Retrieved 18 May 2020.
- Anderson, James P.; Hoffman, Samuel A.; Shifman, Joseph; Williams, Robert J. (1962), "D825 - a multiple-computer system for command & control", Proceedings of the December 4–6, 1962, Fall Joint Computer Conference, AFIPS Conference Proceedings, Volume 24, pp. 86–96, doi:10.1145/1461518.1461527, S2CID 1186864
- Henry M. Levy, "Chapter 2 Early Descriptor Architectures" (PDF), Capability-Based Computer Systems, Digital Press
- "B5500 Announcement" (PDF). Burroughs. August 11, 1964.
- SCAMP picture at dave's Old computers
- Reitman, Valerie (January 18, 1989), "Unisys Ready To Offer A Desktop Mainframe", The Philadelphia Inquirer, retrieved 2011-04-16
- "Unisys Accelerates Mainframe Rebirth with New ClearPath Enterprise Servers, Aggressive New Pricing. - Business Wire - HighBeam Research" (Press release). June 8, 1998. Archived from the original on May 16, 2011.
- "Libra 595". Unisys.
- "Libra 750". Unisys.
- Organick, Elliot (1973). Computer System Organization. ACM. pp. 115–117. ISBN 0-12-528250-8.
{kind=link}
Further reading
- Barton, Robert S. "A New Approach to the Functional Design of a Digital Computer" Proceedings of the Western Joint Computer Conference. ACM (1961).
- Burroughs B 5000 Oral history, Charles Babbage Institute, University of Minnesota. The Burroughs 5000 computer series is discussed by individuals responsible for its development and marketing from 1957 through the 1960s in a 1985 conference sponsored by AFIPS and Burroughs Corporation.
- Gray, George (March 1999). "Some Burroughs Transistor Computers". Unisys History Newsletter. 3 (1). Archived from the original on October 1, 2016.
- Gray, George (October 1999). "Burroughs Third-Generation Computers". Unisys History Newsletter. 3 (5). Archived from the original on September 26, 2017.
- Hauck, E.A., Dent, Ben A. "Burroughs B6500/B7500 Stack Mechanism", SJCC (1968) pp. 245–251.
- McKeeman, William M. "Language Directed Computer Design", Fall Joint Computer Conference, (1967) pp. 413–417.
- Organick, Elliot I. "Computer System Organization The B5700/B6700 series", Academic Press (1973).
- Waychoff, Richard, "Stories of the B5000 and People Who Were There", September 27, 1979.
- Allweiss, Jack. "The Burroughs B5900 and E-Mode A bridge to 21st Century Computing", Revised 2010.
- Martin, Ian. "'Too far ahead of its time': Britain, Burroughs and real-time banking in the 1960s", Society for the History of Technology Annual Meeting, 20 Sep-3 Oct 2010, Tacoma, USA.
External links
- Ian Joyner's Burroughs page
- The Burroughs B5900 and E-Mode: A bridge to 21st Century Computing - Jack Allweiss
- (web archive of:) Ralph Klimek on the B7800 at Monash University
- "Early Burroughs Machines", University of Virginia's Computer Museum.
- "Computer System Organization", ACM Monograph Series.
- Index of B8500 manuals
- B5500 Emulation Project Project to create a functional emulator for the Burroughs B5500 computer system.
- "Burroughs B6500 film & transcript"