Cache-oblivious algorithm
In computing, a cache-oblivious algorithm (or cache-transcendent algorithm) is an algorithm designed to take advantage of a CPU cache without having the size of the cache (or the length of the cache lines, etc.) as an explicit parameter. An optimal cache-oblivious algorithm is a cache-oblivious algorithm that uses the cache optimally (in an asymptotic sense, ignoring constant factors). Thus, a cache-oblivious algorithm is designed to perform well, without modification, on multiple machines with different cache sizes, or for a memory hierarchy with different levels of cache having different sizes. Cache-oblivious algorithms are contrasted with explicit blocking, as in loop nest optimization, which explicitly breaks a problem into blocks that are optimally sized for a given cache.
Optimal cache-oblivious algorithms are known for matrix multiplication, matrix transposition, sorting, and several other problems. Some more general algorithms, such as Cooley–Tukey FFT, are optimally cache-oblivious under certain choices of parameters. Because these algorithms are only optimal in an asymptotic sense (ignoring constant factors), further machine-specific tuning may be required to obtain nearly optimal performance in an absolute sense. The goal of cache-oblivious algorithms is to reduce the amount of such tuning that is required.
Typically, a cache-oblivious algorithm works by a recursive divide-and-conquer algorithm, where the problem is divided into smaller and smaller subproblems. Eventually, one reaches a subproblem size that fits into cache, regardless of the cache size. For example, an optimal cache-oblivious matrix multiplication is obtained by recursively dividing each matrix into four sub-matrices to be multiplied, multiplying the submatrices in a depth-first fashion. In tuning for a specific machine, one may use a hybrid algorithm which uses blocking tuned for the specific cache sizes at the bottom level, but otherwise uses the cache-oblivious algorithm.
History
The idea (and name) for cache-oblivious algorithms was conceived by Charles E. Leiserson as early as 1996 and first published by Harald Prokop in his master's thesis at the Massachusetts Institute of Technology in 1999.[1] There were many predecessors, typically analyzing specific problems; these are discussed in detail in Frigo et al. 1999. Early examples cited include Singleton 1969 for a recursive Fast Fourier Transform, similar ideas in Aggarwal et al. 1987, Frigo 1996 for matrix multiplication and LU decomposition, and Todd Veldhuizen 1996 for matrix algorithms in the Blitz++ library.
Idealized cache model
Cache-oblivious algorithms are typically analyzed using an idealized model of the cache, sometimes called the cache-oblivious model. This model is much easier to analyze than a real cache's characteristics (which have complicated associativity, replacement policies, etc.), but in many cases is provably within a constant factor of a more realistic cache's performance. It is different than the external memory model because cache-oblivious algorithms do not know the block size or the cache size.
In particular, the cache-oblivious model is an abstract machine (i.e. a theoretical model of computation). It is similar to the RAM machine model which replaces the Turing machine's infinite tape with an infinite array. Each location within the array can be accessed in time, similar to the random-access memory on a real computer. Unlike the RAM machine model, it also introduces a cache: a second level of storage between the RAM and the CPU. The other differences between the two models are listed below. In the cache-oblivious model:

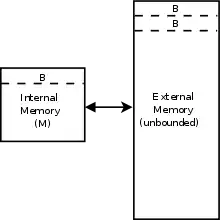


- Memory is broken into blocks of objects each.
- A load or a store between main memory and a CPU register may now be serviced from the cache.
- If a load or a store cannot be serviced from the cache, it is called a cache miss.
- A cache miss results in one block being loaded from main memory into the cache. Namely, if the CPU tries to access word and is the line containing , then is loaded into the cache. If the cache was previously full, then a line will be evicted as well (see replacement policy below).
- The cache holds objects, where . This is also known as the tall cache assumption.
- The cache is fully associative: each line can be loaded into any location in the cache.[2]
- The replacement policy is optimal. In other words, the cache is assumed to be given the entire sequence of memory accesses during algorithm execution. If it needs to evict a line at time , it will look into its sequence of future requests and evict the line that is accessed furthest in the future. This can be emulated in practice with the Least Recently Used policy, which is shown to be within a small constant factor of the offline optimal replacement strategy[3][4]





To measure the complexity of an algorithm that executes within the cache-oblivious model, we measure the number of cache misses that the algorithm experiences. Because the model captures the fact that accessing elements in the cache is much faster than accessing things in main memory, the running time of the algorithm is defined only by the number of memory transfers between the cache and main memory. This is similar to the external memory model, which all of the features above, but cache-oblivious algorithms are independent of cache parameters ( and ).[5] The benefit of such an algorithm is that what is efficient on a cache-oblivious machine is likely to be efficient across many real machines without fine tuning for particular real machine parameters. For many problems, an optimal cache-oblivious algorithm will also be optimal for a machine with more than two memory hierarchy levels.[3]
Examples
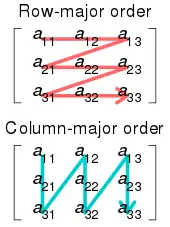
The simplest cache-oblivious algorithm presented in Frigo et al. is an out-of-place matrix transpose operation (in-place algorithms have also been devised for transposition, but are much more complicated for non-square matrices). Given m×n array A and n×m array B, we would like to store the transpose of A in B. The naive solution traverses one array in row-major order and another in column-major. The result is that when the matrices are large, we get a cache miss on every step of the column-wise traversal. The total number of cache misses is .

The cache-oblivious algorithm has optimal work complexity and optimal cache complexity . The basic idea is to reduce the transpose of two large matrices into the transpose of small (sub)matrices. We do this by dividing the matrices in half along their larger dimension until we just have to perform the transpose of a matrix that will fit into the cache. Because the cache size is not known to the algorithm, the matrices will continue to be divided recursively even after this point, but these further subdivisions will be in cache. Once the dimensions m and n are small enough so an input array of size and an output array of size fit into the cache, both row-major and column-major traversals result in work and cache misses. By using this divide and conquer approach we can achieve the same level of complexity for the overall matrix.





(In principle, one could continue dividing the matrices until a base case of size 1×1 is reached, but in practice one uses a larger base case (e.g. 16×16) in order to amortize the overhead of the recursive subroutine calls.)
Most cache-oblivious algorithms rely on a divide-and-conquer approach. They reduce the problem, so that it eventually fits in cache no matter how small the cache is, and end the recursion at some small size determined by the function-call overhead and similar cache-unrelated optimizations, and then use some cache-efficient access pattern to merge the results of these small, solved problems.
Like external sorting in the external memory model, cache-oblivious sorting is possible in two variants: funnelsort, which resembles mergesort, and cache-oblivious distribution sort, which resembles quicksort. Like their external memory counterparts, both achieve a running time of , which matches a lower bound and is thus asymptotically optimal.[5]

References
- Harald Prokop. Cache-Oblivious Algorithms. Masters thesis, MIT. 1999.
- Kumar, Piyush. "Cache-Oblivious Algorithms". Algorithms for Memory Hierarchies. LNCS 2625. Springer Verlag: 193–212. CiteSeerX 10.1.1.150.5426.
- Frigo, M.; Leiserson, C. E.; Prokop, H.; Ramachandran, S. (1999). Cache-oblivious algorithms (PDF). Proc. IEEE Symp. on Foundations of Computer Science (FOCS). pp. 285–297.
- Daniel Sleator, Robert Tarjan. Amortized Efficiency of List Update and Paging Rules. In Communications of the ACM, Volume 28, Number 2, pp. 202–208. Feb 1985.
- Erik Demaine. Cache-Oblivious Algorithms and Data Structures, in Lecture Notes from the EEF Summer School on Massive Data Sets, BRICS, University of Aarhus, Denmark, June 27–July 1, 2002.
