Cold start (recommender systems)
Cold start is a potential problem in computer-based information systems which involves a degree of automated data modelling. Specifically, it concerns the issue that the system cannot draw any inferences for users or items about which it has not yet gathered sufficient information.
| Recommender systems |
|---|
| Concepts |
| Methods and challenges |
| Implementations |
| Research |
Systems affected
The cold start problem is a well known and well researched problem for recommender systems. Recommender systems form a specific type of information filtering (IF) technique that attempts to present information items (e-commerce, films, music, books, news, images, web pages) that are likely of interest to the user. Typically, a recommender system compares the user's profile to some reference characteristics. These characteristics may be related to item characteristics (content-based filtering) or the user's social environment and past behavior (collaborative filtering). Depending on the system, the user can be associated to various kinds of interactions: ratings, bookmarks, purchases, likes, number of page visits etc.
There are three cases of cold start:[1]
- New community: refers to the start-up of the recommender, when, although a catalogue of items might exist, almost no users are present and the lack of user interaction makes it very hard to provide reliable recommendations
- New item: a new item is added to the system, it might have some content information but no interactions are present
- New user: a new user registers and has not provided any interaction yet, therefore it is not possible to provide personalized recommendations
New community
The new community problem, or systemic bootstrapping, refers to the startup of the system, when virtually no information the recommender can rely upon is present.[2] This case presents the disadvantages of both the New user and the New item case, as all items and users are new. Due to this some of the techniques developed to deal with those two cases are not applicable to the system bootstrapping.
New item
The item cold-start problem refers to when items added to the catalogue have either none or very little interactions. This constitutes a problem mainly for collaborative filtering algorithms due to the fact that they rely on the item's interactions to make recommendations. If no interactions are available then a pure collaborative algorithm cannot recommend the item. In case only a few interactions are available, although a collaborative algorithm will be able to recommend it, the quality of those recommendations will be poor.[3] This arises another issue, which is not anymore related to new items, but rather to unpopular items. In some cases (e.g. movie recommendations) it might happen that a handful of items receive an extremely high number of interactions, while most of the items only receive a fraction of them. This is referred to as popularity bias.[4]
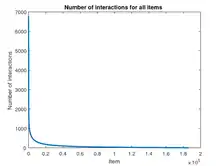
In the context of cold-start items the popularity bias is important because it might happen that many items, even if they have been in the catalogue for months, received only a few interactions. This creates a negative loop in which unpopular items will be poorly recommended, therefore will receive much less visibility than popular ones, and will struggle to receive interactions.[5] While it is expected that some items will be less popular than others, this issue specifically refers to the fact that the recommender has not enough collaborative information to recommend them in a meaningful and reliable way.[6]
Content-based filtering algorithms, on the other hand, are in theory much less prone to the new item problem. Since content based recommenders choose which items to recommend based on the feature the items possess, even if no interaction for a new item exist, still its features will allow for a recommendation to be made.[7] This of course assumes that a new item will be already described by its attributes, which is not always the case. Consider the case of so-called editorial features (e.g. director, cast, title, year), those are always known when the item, in this case movie, is added to the catalogue. However, other kinds of attributes might not be e.g. features extracted from user reviews and tags.[8] Content-based algorithms relying on user provided features suffer from the cold-start item problem as well, since for new items if no (or very few) interactions exist, also no (or very few) user reviews and tags will be available.
New user
The new user case refers to when a new user enrolls in the system and for a certain period of time the recommender has to provide recommendation without relying on the user's past interactions, since none has occurred yet.[9] This problem is of particular importance when the recommender is part of the service offered to users, since a user who is faced with recommendations of poor quality might soon decide to stop using the system before providing enough interaction to allow the recommender to understand his/her interests. The main strategy in dealing with new users is to ask them to provide some preferences to build an initial user profile. A threshold has to be found between the length of the user registration process, which if too long might indice too many users to abandon it, and the amount of initial data required for the recommender to work properly. [2]
Similarly to the new items case, not all recommender algorithms are affected in the same way. Item-item recommenders will be affected as they rely on user profile to weight how relevant other user's preferences are. Collaborative filtering algorithms are the most affected as without interactions no inference can be made about the user's preferences. User-user recommender algorithms [10] behave slightly differently. A user-user content based algorithm will rely on user's features (e.g. age, gender, country) to find similar users and recommend the items they interacted with in a positive way, therefore being robust to the new user case. Note that all these information is acquired during the registration process, either by asking the user to input the data himself, or by leveraging data already available e.g. in his social media accounts.[11]
Mitigation strategies
Due to the high number of recommender algorithms available as well as system type and characteristics, many strategies to mitigate the cold-start problem have been developed. The main approach is to rely on hybrid recommenders, in order to mitigate the disadvantages of one category or model by combining it with another.[12][13][14]
All three categories of cold-start (new community, new item, and new user) have in common the lack of user interactions and presents some commonalities in the strategies available to address them.
A common strategy when dealing with new items is to couple a collaborative filtering recommender, for warm items, with a content-based filtering recommender, for cold-items. While the two algorithms can be combined in different ways, the main drawback of this method is related to the poor recommendation quality often exhibited by content-based recommenders in scenarios where it is difficult to provide a comprehensive description of the item characteristics. [15] In case of new users, if no demographic feature is present or their quality is too poor, a common strategy is to offer them non-personalized recommendations. This means that they could be recommended simply the most popular items either globally or for their specific geographical region or language.
Profile completion
One of the available options when dealing with cold users or items is to rapidly acquire some preference data. There are various ways to do that depending on the amount of information required. These techniques are called preference elicitation strategies.[16][17] This may be done either explicitly (by querying the user) or implicitly (by observing the user's behaviour). In both cases, the cold start problem would imply that the user has to dedicate an amount of effort using the system in its 'dumb' state – contributing to the construction of their user profile – before the system can start providing any intelligent recommendations. [18]
For example MovieLens, a web-based recommender system for movies, asks the user to rate some movies as a part of the registration. While preference elicitation strategy are a simple and effective way to deal with new users, the additional requirements during the registration will make the process more time-consuming for the user. Moreover, the quality of the obtained preferences might not be ideal as the user could rate items he/she has seen months or years ago or the provided ratings could be almost random if the user provided them without paying attention just to complete the registration quickly.
The construction of the user's profile may also be automated by integrating information from other user activities, such as browsing histories or social media platforms. If, for example, a user has been reading information about a particular music artist from a media portal, then the associated recommender system would automatically propose that artist's releases when the user visits the music store.[19]
A variation of the previous approach is to automatically assign ratings to new items, based on the ratings assigned by the community to other similar items. Item similarity would be determined according to the items' content-based characteristics.[18]
It is also possible to create initial profile of a user based on the personality characteristics of the user and use such profile to generate personalized recommendation.[20][21] Personality characteristics of the user can be identified using a personality model such as five factor model (FFM).
Another of the possible techniques is to apply active learning (machine learning). The main goal of active learning is to guide the user in the preference elicitation process in order to ask him to rate only the items that for the recommender point of view will be the most informative ones. This is done by analysing the available data and estimating the usefulness of the data points (e.g., ratings, interactions). [22] As an example, say that we want to build two clusters from a certain cloud of points. As soon as we have identified two points each belonging to a different cluster, which is the next most informative point? If we take a point close to one we already know we can expect that it will likely belong to the same cluster. If we choose a point which is in between the two clusters, knowing which cluster it belongs to will help us in finding where the boundary is, allowing to classify many other points with just a few observations.
The cold start problem is also exhibited by interface agents. Since such an agent typically learns the user's preferences implicitly by observing patterns in the user's behaviour – "watching over the shoulder" – it would take time before the agent may perform any adaptations personalised to the user. Even then, its assistance would be limited to activities which it has formerly observed the user engaging in.[23] The cold start problem may be overcome by introducing an element of collaboration amongst agents assisting various users. This way, novel situations may be handled by requesting other agents to share what they have already learnt from their respective users.[23]
Feature mapping
In recent years more advanced strategies have been proposed, they all rely on machine learning and attempt to merge the content and collaborative information in a single model. One example of this approaches is called attribute to feature mapping[24] which is tailored to matrix factorization algorithms.[25] The basic idea is the following. A matrix factorization model represents the user-item interactions as the product of two rectangular matrices whose content is learned using the known interactions via machine learning. Each user will be associated to a row of the first matrix and each item with a column of the second matrix. The row or column associated to a specific user or item is called latent factors.[26] When a new item is added it has no associated latent factors and the lack of interactions does not allow to learn them, as it was done with other items. If each item is associated to some features (e.g. author, year, publisher, actors) it is possible to define an embedding function, which given the item features estimates the corresponding item latent factors. The embedding function can be designed in many ways and it is trained with the data already available from warm items. Alternatively, one could apply a group-specific method.[27][28] A group-specific method further decomposes each latent factor into two additive parts: One part corresponds to each item (and/or each user), while the other part is shared among items within each item group (e.g., a group of movies could be movies of the same genre). Then once a new item arrives, we can assign a group label to it, and approximates its latent factor by the group-specific part (of the corresponding item group). Therefore, although the individual part of the new item is not available, the group-specific part provides an immediate and effective solution. The same applies for a new user, as if some information is available for them (e.g. age, nationality, gender) then his/her latent factors can be estimated via an embedding function or a group-specific latent factor.
Hybrid feature weighting
Another recent approach which bears similarities with feature mapping is building a hybrid content-based filtering recommender in which features, either of the items or of the users, are weighted according to the user's perception of importance. In order to identify a movie that the user could like, different attributes (e.g. which are the actors, director, country, title) will have different importance. As an example consider the James Bond movie series, the main actor changed many times during the years, while some did not, like Lois Maxwell. Therefore, her presence will probably be a better identifier of that kind of movie than the presence of one of the various main actors. [15][29] Although various techniques exist to apply feature weighting to user or item features in recommender systems, most of them are from the information retrieval domain like tf–idf, Okapi BM25, only a few have been developed specifically for recommenders.[30]
Hybrid feature weighting techniques in particular are tailored for the recommender system domain. Some of them learn feature weight by exploiting directly the user's interactions with items, like FBSM. [29] Others rely on an intermediate collaborative model trained on warm items and attempt to learn the content feature weights which will better approximate the collaborative model.[15]
Many of the hybrid methods can be considered special cases of factorization machines. [31][32]
Differentiating regularization weights
The above methods rely on affiliated information from users or items. Recently, another approach mitigates the cold start problem by assigning lower constraints to the latent factors associated with the items or users that reveal more information (i.e., popular items and active users), and set higher constraints to the others (i.e., less popular items and inactive users).[33] It is shown that various recommendation models benefit from this strategy. Differentiating regularization weights can be integrated with the other cold start mitigating strategies.
See also
References
- Bobadilla, Jesús; Ortega, Fernando; Hernando, Antonio; Bernal, Jesús (February 2012). "A collaborative filtering approach to mitigate the new user cold start problem". Knowledge-Based Systems. 26: 225–238. doi:10.1016/j.knosys.2011.07.021.
- Rashid, Al Mamunur; Karypis, George; Riedl, John (20 December 2008). "Learning preferences of new users in recommender systems". ACM SIGKDD Explorations Newsletter. 10 (2): 90. doi:10.1145/1540276.1540302.
- Lika, Blerina; Kolomvatsos, Kostas; Hadjiefthymiades, Stathes (March 2014). "Facing the cold start problem in recommender systems". Expert Systems with Applications. 41 (4): 2065–2073. doi:10.1016/j.eswa.2013.09.005.
- Hou, Lei; Pan, Xue; Liu, Kecheng (7 March 2018). "Balancing the popularity bias of object similarities for personalised recommendation". The European Physical Journal B. 91 (3): 47. Bibcode:2018EPJB...91...47H. doi:10.1140/epjb/e2018-80374-8.
- Abdollahpouri, Himan; Burke, Robin; Mobasher, Bamshad (27 August 2017). Proceedings of the Eleventh ACM Conference on Recommender Systems - Rec Sys '17. ACM. pp. 42–46. doi:10.1145/3109859.3109912. ISBN 9781450346528.
- Park, Yoon-Joo; Tuzhilin, Alexander (23 October 2008). Proceedings of the 2008 ACM conference on Recommender systems - Rec Sys '08. ACM. pp. 11–18. CiteSeerX 10.1.1.421.1833. doi:10.1145/1454008.1454012. ISBN 9781605580937.
- Pazzani, Michael J.; Billsus, Daniel (2007). Content-Based Recommendation Systems. The Adaptive Web. Lecture Notes in Computer Science. 4321. pp. 325–341. CiteSeerX 10.1.1.130.8327. doi:10.1007/978-3-540-72079-9_10. ISBN 978-3-540-72078-2.
- Chen, Li; Chen, Guanliang; Wang, Feng (22 January 2015). "Recommender systems based on user reviews: the state of the art". User Modeling and User-Adapted Interaction. 25 (2): 99–154. doi:10.1007/s11257-015-9155-5.
- Bobadilla, Jesús; Ortega, Fernando; Hernando, Antonio; Bernal, Jesús (February 2012). "A collaborative filtering approach to mitigate the new user cold start problem". Knowledge-Based Systems. 26: 225–238. doi:10.1016/j.knosys.2011.07.021.
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. (July 2013). "Recommender systems survey". Knowledge-Based Systems. 46: 109–132. doi:10.1016/j.knosys.2013.03.012.
- Zhang, Zi-Ke; Liu, Chuang; Zhang, Yi-Cheng; Zhou, Tao (1 October 2010). "Solving the cold-start problem in recommender systems with social tags". EPL (Europhysics Letters). 92 (2): 28002. arXiv:1004.3732. Bibcode:2010EL.....9228002Z. doi:10.1209/0295-5075/92/28002.
- Huang, Zan; Chen, Hsinchun; Zeng, Daniel (1 January 2004). "Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering". ACM Transactions on Information Systems. 22 (1): 116–142. CiteSeerX 10.1.1.3.1590. doi:10.1145/963770.963775.
- Salter, J.; Antonopoulos, N. (January 2006). "CinemaScreen Recommender Agent: Combining Collaborative and Content-Based Filtering" (PDF). IEEE Intelligent Systems. 21 (1): 35–41. doi:10.1109/MIS.2006.4.
- Burke, Robin (2007). Hybrid Web Recommender Systems. The Adaptive Web. Lecture Notes in Computer Science. 4321. pp. 377–408. CiteSeerX 10.1.1.395.8975. doi:10.1007/978-3-540-72079-9_12. ISBN 978-3-540-72078-2.
- Cella, Leonardo; Cereda, Stefano; Quadrana, Massimo; Cremonesi, Paolo (2017). Deriving Item Features Relevance from Past User Interactions. UMAP '17 Proceedings of the 25th Conference on User Modeling, Adaptation and Personalization. pp. 275–279. doi:10.1145/3079628.3079695. hdl:11311/1061220. ISBN 9781450346351.
- Elahi, Mehdi; Ricci, Francesco; Rubens, Neil (2014). E-Commerce and Web Technologies. Lecture Notes in Business Information Processing. 188. Springer International Publishing. pp. 113–124. doi:10.1007/978-3-319-10491-1_12. ISBN 978-3-319-10491-1.
- Elahi, Mehdi; Ricci, Francesco; Rubens, Neil (2016). "A survey of active learning in collaborative filtering recommender systems". Computer Science Review. 20: 29–50. doi:10.1016/j.cosrev.2016.05.002 – via Elsevier.
- Andrew I. Schein; Alexandrin Popescul; Lyle H. Ungar; David M. Pennock (2002). Methods and Metrics for Cold-Start Recommendations. Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2002). New York City, New York: ACM. pp. 253–260. ISBN 1-58113-561-0. Retrieved 2008-02-02.
- "Vendor attempts to crack 'cold start' problem in content recommendations" (PDF). Mobile Media: 18. 2007-06-29. Archived from the original (PDF) on 2008-11-21. Retrieved 2008-02-02.
- Tkalcic, Marko; Chen, Li (2016). "Personality and Recommender Systems". In Ricci, Francesco; Rokach, Lior; Shapira, Bracha (eds.). Recommender Systems Handbook (2nd ed.). Springer US. doi:10.1007/978-1-4899-7637-6_21. ISBN 978-1-4899-7637-6.
- Fernández-Tobías, Ignacio; Braunhofer, Matthias; Elahi, Mehdi; Ricci, Francesco; Cantador, Iván (2016). "Alleviating the new user problem in collaborative filtering by exploiting personality information". User Modeling and User-Adapted Interaction. 26 (2–3): 221–255. doi:10.1007/s11257-016-9172-z. hdl:10486/674370.
- Rubens, Neil; Elahi, Mehdi; Sugiyama, Masashi; Kaplan, Dain (2016). "Active Learning in Recommender Systems". In Ricci, Francesco; Rokach, Lior; Shapira, Bracha (eds.). Recommender Systems Handbook (2nd ed.). Springer US. doi:10.1007/978-1-4899-7637-6_24. ISBN 978-1-4899-7637-6.
- Yezdi Lashkari; Max Metral; Pattie Maes (1994). Collaborative Interface Agents. Proceedings of the Twelfth National Conference on Artificial Intelligence. Seattle, Washington: AAAI Press. pp. 444–449. ISBN 0-262-61102-3. Retrieved 2008-02-02.
- Gantner, Zeno; Drumond, Lucas; Freudenthaler, Cristoph (20 January 2011). 2010 IEEE International Conference on Data Mining. pp. 176–185. CiteSeerX 10.1.1.187.5933. doi:10.1109/ICDM.2010.129. ISBN 978-1-4244-9131-5.
- Koren, Yehuda; Bell, Robert; Volinsky, Chris (August 2009). "Matrix Factorization Techniques for Recommender Systems". Computer. 42 (8): 30–37. CiteSeerX 10.1.1.147.8295. doi:10.1109/MC.2009.263.
- Agarwal, Deepak; Chen, Bee-Chung (28 June 2009). Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining - KDD '09. ACM. pp. 19–28. doi:10.1145/1557019.1557029. ISBN 9781605584959.
- Bi, Xuan; Qu, Annie; Wang, Junhui; Shen, Xiaotong (2017). "A group-specific recommender system". Journal of the American Statistical Association. 112 (519): 1344–1353.
- Bi, Xuan; Qu, Annie; Shen, Xiaotong (2018). "Multilayer tensor factorization with applications to recommender systems". Annals of Statistics. 46 (6B): 3303–3333.
- Sharma, Mohit; Zhou, Jiayu; Hu, Junling; Karypis, George (2015). Feature-based factorized Bilinear Similarity Model for Cold-Start Top-n Item Recommendation. Proceedings of the 2015 SIAM International Conference on Data Mining. pp. 190–198. doi:10.1137/1.9781611974010.22. ISBN 978-1-61197-401-0.
- Symeonidis, Panagiotis; Nanopoulos, Alexandros; Manolopoulos, Yannis (25 July 2007). Feature-Weighted User Model for Recommender Systems. User Modeling 2007. Lecture Notes in Computer Science. 4511. pp. 97–106. doi:10.1007/978-3-540-73078-1_13. ISBN 978-3-540-73077-4.
- Rendle, Steffen (1 May 2012). "Factorization Machines with libFM". ACM Transactions on Intelligent Systems and Technology. 3 (3): 1–22. doi:10.1145/2168752.2168771.
- Rendle, Steffen (2010). "Factorization Machines". 2010 IEEE International Conference on Data Mining. IEEE. pp. 995–1000. CiteSeerX 10.1.1.393.8529. doi:10.1109/ICDM.2010.127. ISBN 9781424491315.
- ChenHung-Hsuan; ChenPu (2019-01-09). "Differentiating Regularization Weights -- A Simple Mechanism to Alleviate Cold Start in Recommender Systems". ACM Transactions on Knowledge Discovery from Data (TKDD). 13: 1–22. doi:10.1145/3285954.