Concurrent hash table
A concurrent hash table (concurrent hash map) is an implementation of hash tables allowing concurrent access by multiple threads using a hash function.[1][2]
Concurrent hash tables thus represent a key concurrent data structure for use in concurrent computing which allow multiple threads to more efficiently cooperate for a computation among shared data.[1]
Due to the natural problems associated with concurrent access - namely contention - the way and scope in which the table can be concurrently accessed differs depending on the implementation. Furthermore, the resulting speed up might not be linear with the amount of threads used as contention needs to be resolved, producing processing overhead.[1] There exist multiple solutions to mitigate the effects of contention, that each preserve the correctness of operations on the table.[1][2][3][4]
As with their sequential counterpart, concurrent hash tables can be generalized and extended to fit broader applications, such as allowing more complex data types to be used for keys and values. These generalizations can however negatively impact performance and should thus be chosen in accordance to the requirements of the application.[1]
Concurrent hashing
When creating concurrent hash tables, the functions accessing the table with the chosen hashing algorithm need to be adapted for concurrency by adding a conflict resolution strategy. Such a strategy requires managing accesses in a way such that conflicts caused by them do not result in corrupt data, while ideally increasing their efficiency when used in parallel. Herlihy and Shavit[5] describe how the accesses to a hash table without such a strategy - in its example based on a basic implementation of the Cuckoo hashing algorithm - can be adapted for concurrent use. Fan et al.[6] further describe a table access scheme based on cuckoo hashing that is not only concurrent, but also keeps the space efficiency of its hashing function while also improving cache locality as well as the throughput of insertions.
When hash tables are not bound in size and are thus allowed to grow/shrink when necessary, the hashing algorithm needs to be adapted to allow this operation. This entails modifying the used hash function to reflect the new key-space of the resized table. A concurrent growing algorithm is described by Maier et al.[1]
Mega-KV[7] is a high performance key-value store system, where the cuckoo hashing is used and the KV indexing is massively parallelized in batch mode by GPU. With further optimizations of GPU acceleration by NVIDIA and Oak Ridge National Lab, Mega-KV was pushed to another high record of the throughput in 2018 (up to 888 millions of key-value operations per second).[8]
Contention handling
As with any concurrent data structure, concurrent hash tables suffer from a variety of problems known in the field of concurrent computing as a result of contention.[3] Examples for such are the ABA problem, race conditions, and deadlocks. The extent in which these problems manifest or even occur at all depends on the implementation of the concurrent hash table; specifically which operations the table allows to be run concurrently, as well as its strategies for mitigating problems associated with contention. When handling contention, the main goal is the same as with any other concurrent data structure, namely ensuring correctness for every operation on the table. At the same time, it should naturally be done in such a way as to be more efficient than a sequential solution when used concurrently. This is also known as concurrency control.
Atomic instructions
Using atomic instructions such as compare-and-swap or fetch-and-add, problems caused by contention can be reduced by ensuring that an access is completed before another access has the chance to interfere. Operations such as compare-and-swap often present limitations as to what size of data they can handle, meaning that the types of keys and values of a table have to be chosen or converted accordingly.[1]
Using so called Hardware Transactional Memory (HTM), table operations can be thought of much like database transactions,[3] ensuring atomicity. An example of HTM in practice are the Transactional Synchronization Extensions.
Locking
With the help of locks, operations trying to concurrently access the table or values within it can be handled in a way that ensures correct behavior. This can however lead to negative performance impacts,[1][6] in particular when the locks used are too restrictive, thus blocking accesses that would otherwise not contend and could execute without causing any problems. Further considerations have to be made to avoid even more critical problems that threaten correctness, as with livelocks, deadlocks or starvation.[3]
Phase concurrency
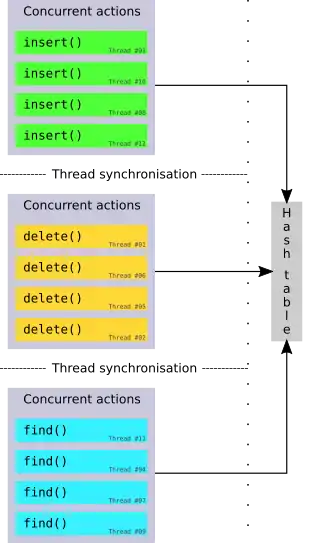
A phase concurrent hash table groups accesses by creating phases in which only one type of operation is allowed (i.e. a pure write-phase), followed by a synchronization of the table state across all threads. A formally proven algorithm for this is given by Shun and Blelloch.[2]
Read-Copy-Update
Widely used within the Linux kernel,[3] read-copy-update (RCU) is especially useful in cases where the number of reads far exceeds the number of writes.[4]
Applications
Naturally, concurrent hash tables find application wherever sequential hash tables are useful. The advantage that concurrency delivers herein lies within the potential speedup of these use-cases, as well as the increased scalability.[1] Considering hardware such as multi-core processors that become increasingly more capable of concurrent computation, the importance of concurrent data structures within these applications grow steadily.[3]
Performance Analysis
Maier et al.[1] perform a thorough analysis on a variety of concurrent hash table implementations, giving insight into the effectiveness of each in different situations that are likely to occur in real use-cases. The most important findings can be summed up as the following:
| Operation | Contention | Notes | |
|---|---|---|---|
| Low | High | ||
find | Very high speedups both when successful and unsuccessful unique finds, even with very high contention | ||
insert | High speedups reached, high contention becomes problematic when keys can hold more than one value (otherwise inserts are simply discarded if key already exists) | ||
update | Both overwrites and modifications of existing values reach high speedups when contention is kept low, otherwise performs worse than sequential | ||
delete | Phase concurrency reached highest scalability; Fully concurrent implementations where delete uses update with dummy-elements were closely behind | ||
As expected low contention leads to positive behavior across every operation, whereas high contention becomes problematic when it comes to writing. The latter however is a problem of high contention in general, wherein the benefit of concurrent computation is negated due to the natural requirement for concurrency control restricting contending accesses. The resulting overhead causes worse performance than that of the ideal sequential version. In spite of this, concurrent hash tables still prove invaluable even in such high contention scenarios when observing that a well-designed implementation can still achieve very high speedups by leveraging the benefits of concurrency to read data concurrently.
However, real use-cases of concurrent hash tables are often not simply sequences of the same operation, but rather a mixture of multiple types.
As such, when a mixture of insert and find operations is used the speedup and resulting usefulness of concurrent hash tables become more obvious, especially when observing find heavy workloads.
Ultimately the resulting performance of a concurrent hash table depends on a variety of factors based upon its desired application. When choosing the implementation, it is important to determine the necessary amount of generality, contention handling strategies and some thoughts on whether the size of the desired table can be determined in advance or a growing approach must be used instead.
Implementations
- Since Java 1.5, concurrent hash maps are provided based upon concurrent map interface.[9]
- libcuckoo provides concurrent hash tables for C/C++ allowing concurrent reads and writes. The library is available on GitHub.[10]
- Threading Building Blocks provide concurrent unordered maps for C++ which allow concurrent insertion and traversal and are kept in a similar style to the C++11
std::unordered_mapinterface. Included within are the concurrent unordered multimaps, which allow multiple values to exist for the same key in a concurrent unordered map.[11] Additionally, concurrent hash maps are provided which build upon the concurrent unordered map and further allow concurrent erasure and contain built-in locking.[12] - growt provides concurrent growing hash tables for C++ on the basis of the so-called folklore implementation. Based on this non-growing implementation, a variety of different growing hash tables is given. These implementations allow for concurrent reads, inserts, updates (notably updating values based on the current value at the key) and removals (based upon updating using tombstones). Beyond that, variants on the basis of Intel TSX are provided. The library is available on GitHub.[1][13]
- folly provides concurrent hash tables[14] for C++14 and later ensuring wait-free readers and lock-based, sharded writers. As stated on its GitHub page, this library provides useful functionality for Facebook.[15]
- Junction provides several implementations of concurrent hash tables for C++ on the basis of atomic operations to ensure thread-safety for any given member function of the table. The library is available on GitHub.[16]
See also
References
- Maier, Tobias; Sanders, Peter; Dementiev, Roman (March 2019). "Concurrent Hash Tables: Fast and General(?)!". ACM Transactions on Parallel Computing. New York, NY, USA: ACM. 5 (4). Article 16. doi:10.1145/3309206. ISSN 2329-4949.
- Shun, Julian; Blelloch, Guy E. (2014). "Phase-concurrent Hash Tables for Determinism". SPAA '14: Proceedings of the 26th ACM symposium on Parallelism in algorithms and architectures. New York: ACM. pp. 96–107. doi:10.1145/2612669.2612687. ISBN 978-1-4503-2821-0.
- Li, Xiaozhou; Andersen, David G.; Kaminsky, Michael; Freedman, Michael J. (2014). "Algorithmic Improvements for Fast Concurrent Cuckoo Hashing". Proceedings of the Ninth European Conference on Computer Systems. EuroSys '14. New York: ACM. Article No. 27. doi:10.1145/2592798.2592820. ISBN 978-1-4503-2704-6.
- Triplett, Josh; McKenney, Paul E.; Walpole, Jonathan (2011). "Resizable, Scalable, Concurrent Hash Tables via Relativistic Programming". USENIXATC'11: Proceedings of the 2011 USENIX conference on USENIX annual technical conference. Berkeley, CA: USENIX Association. p. 11.
- Herlihy, Maurice; Shavit, Nir (2008). "Chapter 13: Concurrent Hashing and Natural Parallelism". The Art of Multiprocessor Programming. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc. pp. 316–325. ISBN 978-0-12-370591-4.
- Fan, Bin; Andersen, David G.; Kaminsky, Michael (2013). "MemC3: Compact and Concurrent MemCache with Dumber Caching and Smarter Hashing". nsdi'13: Proceedings of the 10th USENIX conference on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association. pp. 371–384.
- Zhang, Kai; Wang, Kaibo; Yuan, Yuan; Guo, Lei; Lee, Rubao; and Zhang, Xiaodong (2015). "Mega-KV: a case for GPUs to maximize the throughput of in-memory key-value stores". Proceedings of the VLDB Endowment, Vol. 8, No. 11, 2015.
- Chu, Ching-Hsing; Potluri, Sreeram; Goswami, Anshuman; Venkata, Manjunath Gorentla; Imam, Neenaand; and Newburn, Chris J. (2018) "Designing High-performance in-memory key-value operations with persistent GPU kernels and OPENSHMEM"..
- Java ConcurrentHashMap documentation
- GitHub repository for libcuckoo
- Threading Building Blocks concurrent_unordered_map and concurrent_unordered_multimap documentation
- Threading Building Blocks concurrent_hash_map documentation
- GitHub repository for growt
- GitHub page for implementation of concurrent hash maps in folly
- GitHub repository for folly
- GitHub repository for Junction
Further reading
- Herlihy, Maurice; Shavit, Nir (2008). "Chapter 13: Concurrent Hashing and Natural Parallelism". The Art of Multiprocessor Programming. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc. pp. 299–328. ISBN 978-0-12-370591-4.
