Consensus clustering
Consensus clustering is a method of aggregating (potentially conflicting) results from multiple clustering algorithms. Also called cluster ensembles[1] or aggregation of clustering (or partitions), it refers to the situation in which a number of different (input) clusterings have been obtained for a particular dataset and it is desired to find a single (consensus) clustering which is a better fit in some sense than the existing clusterings.[2] Consensus clustering is thus the problem of reconciling clustering information about the same data set coming from different sources or from different runs of the same algorithm. When cast as an optimization problem, consensus clustering is known as median partition, and has been shown to be NP-complete,[3] even when the number of input clusterings is three.[4] Consensus clustering for unsupervised learning is analogous to ensemble learning in supervised learning.
Issues with existing clustering techniques
- Current clustering techniques do not address all the requirements adequately.
- Dealing with large number of dimensions and large number of data items can be problematic because of time complexity;
- Effectiveness of the method depends on the definition of "distance" (for distance-based clustering)
- If an obvious distance measure doesn't exist, we must "define" it, which is not always easy, especially in multidimensional spaces.
- The result of the clustering algorithm (that, in many cases, can be arbitrary itself) can be interpreted in different ways.
Justification for using consensus clustering
There are potential shortcomings for all existing clustering techniques. This may cause interpretation of results to become difficult, especially when there is no knowledge about the number of clusters. Clustering methods are also very sensitive to the initial clustering settings, which can cause non-significant data to be amplified in non-reiterative methods. An extremely important issue in cluster analysis is the validation of the clustering results, that is, how to gain confidence about the significance of the clusters provided by the clustering technique (cluster numbers and cluster assignments). Lacking an external objective criterion (the equivalent of a known class label in supervised analysis), this validation becomes somewhat elusive. Iterative descent clustering methods, such as the SOM and k-means clustering circumvent some of the shortcomings of hierarchical clustering by providing for univocally defined clusters and cluster boundaries. Consensus clustering provides a method that represents the consensus across multiple runs of a clustering algorithm, to determine the number of clusters in the data, and to assess the stability of the discovered clusters. The method can also be used to represent the consensus over multiple runs of a clustering algorithm with random restart (such as K-means, model-based Bayesian clustering, SOM, etc.), so as to account for its sensitivity to the initial conditions. It can provide data for a visualization tool to inspect cluster number, membership, and boundaries. However, they lack the intuitive and visual appeal of hierarchical clustering dendrograms, and the number of clusters must be chosen a priori.
The Monti consensus clustering algorithm
The Monti consensus clustering algorithm[5] is one of the most popular consensus clustering algorithms and is used to determine the number of clusters, . Given a dataset of total number of points to cluster, this algorithm works by resampling and clustering the data, for each and a consensus matrix is calculated, where each element represents the fraction of times two samples clustered together. A perfectly stable matrix would consist entirely of zeros and ones, representing all sample pairs always clustering together or not together over all resampling iterations. The relative stability of the consensus matrices can be used to infer the optimal .



More specifically, given a set of points to cluster, , let be the list of pertubed (resampled) datasets of the original dataset , and let denote the connectivity matrix resulting from applying a clustering algorithm to the dataset . The entries of are defined as follows:








Let be the identicator matrix where the -th entry is equal to 1 if points and are in the same perturbed dataset , and 0 otherwise. The indicator matrix is used to keep track of which samples were selected during each resampling iteration for the normalisation step. The consensus matrix is defined as the normalised sum of all connectivity matrices of all the perturbed datasets and a different one is calculated for every .






That is the entry in the consensus matrix is the number of times points and were clustered together divided by the total number of times they were selected together. The matrix is symmetric and each element is defined within the range . A consensus matrix is calculated for each to be tested, and the stability of each matrix, that is how far the matrix is towards a matrix of perfect stability (just zeros and ones) is used to determine the optimal . One way of quantifying the stability of the th consensus matrix is examining its CDF curve (see below).

Over-interpretation potential of the Monti consensus clustering algorithm
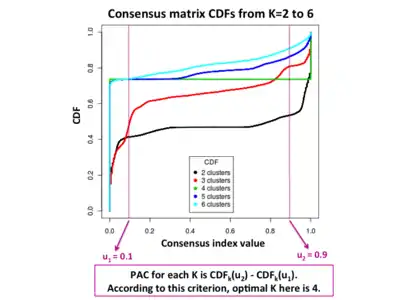
Monti consensus clustering can be a powerful tool for identifying clusters, but it needs to be applied with caution as shown by Şenbabaoğlu et al. [6] It has been shown that the Monti consensus clustering algorithm is able to claim apparent stability of chance partitioning of null datasets drawn from a unimodal distribution, and thus has the potential to lead to over-interpretation of cluster stability in a real study.[6][7] If clusters are not well separated, consensus clustering could lead one to conclude apparent structure when there is none, or declare cluster stability when it is subtle. Identifying false positive clusters is a common problem throughout cluster research,[8] and has been addressed by methods such as SigClust[8] and the GAP-statistic.[9] However, these methods rely on certain assumptions for the null model that may not always be appropriate.
Şenbabaoğlu et al [6] demonstrated the original delta K metric to decide in the Monti algorithm performed poorly, and proposed a new superior metric for measuring the stability of consensus matrices using their CDF curves. In the CDF curve of a consensus matrix, the lower left portion represents sample pairs rarely clustered together, the upper right portion represents those almost always clustered together, whereas the middle segment represent those with ambiguous assignments in different clustering runs. The proportion of ambiguous clustering (PAC) score measure quantifies this middle segment; and is defined as the fraction of sample pairs with consensus indices falling in the interval (u1, u2) ∈ [0, 1] where u1 is a value close to 0 and u2 is a value close to 1 (for instance u1=0.1 and u2=0.9). A low value of PAC indicates a flat middle segment, and a low rate of discordant assignments across permuted clustering runs. One can therefore infer the optimal number of clusters by the value having the lowest PAC.[6][7]
Related work
1. Clustering ensemble (Strehl and Ghosh): They considered various formulations for the problem, most of which reduce the problem to a hyper-graph partitioning problem. In one of their formulations they considered the same graph as in the correlation clustering problem. The solution they proposed is to compute the best k-partition of the graph, which does not take into account the penalty for merging two nodes that are far apart.
2. Clustering aggregation (Fern and Brodley): They applied the clustering aggregation idea to a collection of soft clusterings they obtained by random projections. They used an agglomerative algorithm and did not penalize for merging dissimilar nodes.
3. Fred and Jain: They proposed to use a single linkage algorithm to combine multiple runs of the k-means algorithm.
4. Dana Cristofor and Dan Simovici: They observed the connection between clustering aggregation and clustering of categorical data. They proposed information theoretic distance measures, and they propose genetic algorithms for finding the best aggregation solution.
5. Topchy et al.: They defined clustering aggregation as a maximum likelihood estimation problem, and they proposed an EM algorithm for finding the consensus clustering.
Hard ensemble clustering
This approach by Strehl and Ghosh introduces the problem of combining multiple partitionings of a set of objects into a single consolidated clustering without accessing the features or algorithms that determined these partitionings. They discuss three approaches towards solving this problem to obtain high quality consensus functions. Their techniques have low computational costs and this makes it feasible to evaluate each of the techniques discussed below and arrive at the best solution by comparing the results against the objective function.
Efficient consensus functions
1. Cluster-based similarity partitioning algorithm (CSPA)
In CSPA the similarity between two data-points is defined to be directly proportional to number of constituent clusterings of the ensemble in which they are clustered together. The intuition is that the more similar two data-points are the higher is the chance that constituent clusterings will place them in the same cluster. CSPA is the simplest heuristic, but its computational and storage complexity are both quadratic in n. SC3 is an example of a CSPA type algorithm.[10] The following two methods are computationally less expensive:
2. Hyper-graph partitioning algorithm (HGPA)
The HGPA algorithm takes a very different approach to finding the consensus clustering than the previous method. The cluster ensemble problem is formulated as partitioning the hypergraph by cutting a minimal number of hyperedges. They make use of hMETIS which is a hypergraph partitioning package system.
3. Meta-clustering algorithm (MCLA)
The meta-cLustering algorithm (MCLA) is based on clustering clusters. First, it tries to solve the cluster correspondence problem and then uses voting to place data-points into the final consensus clusters. The cluster correspondence problem is solved by grouping the clusters identified in the individual clusterings of the ensemble. The clustering is performed using METIS and Spectral clustering.
Soft clustering ensembles
Punera and Ghosh extended the idea of hard clustering ensembles to the soft clustering scenario. Each instance in a soft ensemble is represented by a concatenation of r posterior membership probability distributions obtained from the constituent clustering algorithms. We can define a distance measure between two instances using the Kullback–Leibler (KL) divergence, which calculates the "distance" between two probability distributions.
1. sCSPA
sCSPA extends CSPA by calculating a similarity matrix. Each object is visualized as a point in dimensional space, with each dimension corresponding to probability of its belonging to a cluster. This technique first transforms the objects into a label-space and then interprets the dot product between the vectors representing the objects as their similarity.
2. sMCLA
sMCLA extends MCLA by accepting soft clusterings as input. sMCLA's working can be divided into the following steps:
- Construct Soft Meta-Graph of Clusters
- Group the Clusters into Meta-Clusters
- Collapse Meta-Clusters using Weighting
- Compete for Objects
3. sHBGF
HBGF represents the ensemble as a bipartite graph with clusters and instances as nodes, and edges between the instances and the clusters they belong to.[11] This approach can be trivially adapted to consider soft ensembles since the graph partitioning algorithm METIS accepts weights on the edges of the graph to be partitioned. In sHBGF, the graph has n + t vertices, where t is the total number of underlying clusters.
4. Bayesian consensus clustering (BCC)
BCC defines a fully Bayesian model for soft consensus clustering in which multiple source clusterings, defined by different input data or different probability models, are assumed to adhere loosely to a consensus clustering.[12] The full posterior for the separate clusterings, and the consensus clustering, are inferred simultaneously via Gibbs sampling.
Sources
- Strehl, Alexander; Ghosh, Joydeep (2002). "Cluster ensembles – a knowledge reuse framework for combining multiple partitions" (PDF). Journal on Machine Learning Research (JMLR). 3: 583–617.
- VEGA-PONS, SANDRO; RUIZ-SHULCLOPER, JOSÉ (1 May 2011). "A Survey of Clustering Ensemble Algorithms". International Journal of Pattern Recognition and Artificial Intelligence. 25 (3): 337–372. doi:10.1142/S0218001411008683. S2CID 4643842.
- Filkov, Vladimir (2003). Integrating microarray data by consensus clustering. In Proceedings of the 15th IEEE International Conference on Tools with Artificial Intelligence. pp. 418–426. CiteSeerX 10.1.1.116.8271. doi:10.1109/TAI.2003.1250220. ISBN 978-0-7695-2038-4.
- Bonizzoni, Paola; Della Vedova, Gianluca; Dondi, Riccardo; Jiang, Tao (2008). "On the Approximation of Correlation Clustering and Consensus Clustering". Journal of Computer and System Sciences. 74 (5): 671–696. doi:10.1016/j.jcss.2007.06.024.
- Monti, Stefano; Tamayo, Pablo; Mesirov, Jill; Golub, Todd (2003-07-01). "Consensus Clustering: A Resampling-Based Method for Class Discovery and Visualization of Gene Expression Microarray Data". Machine Learning. 52 (1): 91–118. doi:10.1023/A:1023949509487. ISSN 1573-0565.
- Şenbabaoğlu, Y.; Michailidis, G.; Li, J. Z. (2014). "Critical limitations of consensus clustering in class discovery". Scientific Reports. 4: 6207. Bibcode:2014NatSR...4E6207.. doi:10.1038/srep06207. PMC 4145288. PMID 25158761.
- Şenbabaoğlu, Y.; Michailidis, G.; Li, J. Z. (Feb 2014). "A reassessment of consensus clustering for class discovery". bioRxiv 10.1101/002642.
- Liu, Yufeng; Hayes, David Neil; Nobel, Andrew; Marron, J. S. (2008-09-01). "Statistical Significance of Clustering for High-Dimension, Low–Sample Size Data". Journal of the American Statistical Association. 103 (483): 1281–1293. doi:10.1198/016214508000000454. ISSN 0162-1459.
- Tibshirani, Robert; Walther, Guenther; Hastie, Trevor (2001). "Estimating the number of clusters in a data set via the gap statistic". Journal of the Royal Statistical Society: Series B (Statistical Methodology). 63 (2): 411–423. doi:10.1111/1467-9868.00293. ISSN 1467-9868.
- Kiselev, Vladimir Yu; Kirschner, Kristina; Schaub, Michael T; Andrews, Tallulah; Yiu, Andrew; Chandra, Tamir; Natarajan, Kedar N; Reik, Wolf; Barahona, Mauricio; Green, Anthony R; Hemberg, Martin (May 2017). "SC3: consensus clustering of single-cell RNA-seq data". Nature Methods. 14 (5): 483–486. doi:10.1038/nmeth.4236. ISSN 1548-7091. PMC 5410170. PMID 28346451.
- Solving cluster ensemble problems by bipartite graph partitioning, Xiaoli Zhang Fern and Carla Brodley, Proceedings of the twenty-first international conference on Machine learning
- Lock, E.F.; Dunson, D.B. (2013). "Bayesian consensus clustering". Bioinformatics. 29 (20): 2610–2616. arXiv:1302.7280. Bibcode:2013arXiv1302.7280L. doi:10.1093/bioinformatics/btt425. PMC 3789539. PMID 23990412.
References
- Alexander Strehl and J. Ghosh, Cluster ensembles – a knowledge reuse framework for combining multiple partitions, Journal on Machine Learning Research (JMLR) 2002, 3, 583–617.
- Kunal Punera, Joydeep Ghosh. Consensus Based Ensembles of Soft Clusterings.
- Aristides Gionis, Heikki Mannila, Panayiotis Tsaparas. Clustering Aggregation. 21st International Conference on Data Engineering (ICDE 2005)
- Hongjun Wang, Hanhuai Shan, Arindam Banerjee. Bayesian Cluster Ensembles, SIAM International Conference on Data Mining, SDM 09
- Nam Nguyen, Rich Caruana. Consensus Clusterings. Seventh IEEE International Conference on Data Mining.
- Alexander Topchy, Anil K. Jain, William Punch. Clustering Ensembles: Models of Consensus and Weak Partitions. IEEE International Conference on Data Mining, ICDM 03 & SIAM International Conference on Data Mining, SDM 04
