Cray XMT
Cray XMT (Cray eXtreme MultiThreading,[1] codenamed Eldorado[2]) is a scalable multithreaded shared memory supercomputer architecture by Cray, based on the third generation of the Tera MTA architecture, targeted at large graph problems (e.g. semantic databases, big data, pattern matching).[3][4][5] Presented in 2005, it supersedes the earlier unsuccessful Cray MTA-2. It uses the Threadstorm3 CPUs inside Cray XT3 blades. Designed to make use of commodity parts and existing subsystems for other commercial systems, it alleviated the shortcomings of Cray MTA-2's high cost of fully custom manufacture and support.[2] It brought various substantial improvements over Cray MTA-2, most notably nearly tripling the peak performance, and vastly increased maximum CPU count to 8,192 and maximum memory to 128 TB, with a data TLB of maximal 512 TB.[2][3]
| Designer | Cray |
|---|---|
| Bits | 64-bit |
| Introduced | 2005 |
| Version | 3rd generation of Tera MTA |
| Endianness | Big-endian |
| Predecessor | Cray MTA-2 |
| Successor | Cray XMT2 |
| Registers | |
| 32 general-purpose per stream (4096 per CPU) 8 target per stream (1024 per CPU) | |
Cray XMT uses a scrambled[3] content-addressable memory[6] model on DDR1 ECC modules to implicitly load-balance memory access across the whole shared global address space of the system.[5] Use of 4 additional Extended Memory Semantics bits (full/empty, forwarding and 2 trap bits) per 64-bit memory word enables lightweight, fine-grained synchronization on all memory.[7] There are no hardware interrupts and hardware threads are allocated by an instruction, not the OS.[5][7]
Front-end (login, I/O, and other service nodes, utilizing AMD Opteron processors and running SLES Linux) and back-end (compute nodes, utilizing Threadstorm3 processors and running MTK, a simple BSD Unix-based microkernel[3]) communicate through the LUC (Lightweight User Communication) interface, a RPC-style bidirectional client/server interface.[1][5]
Threadstorm3
 | |
| General information | |
|---|---|
| Launched | 2005 |
| Discontinued | 2011 |
| Designed by | Cray |
| Performance | |
| Max. CPU clock rate | 500 MHz |
| HyperTransport speeds | to 300 GT/s |
| Architecture and classification | |
| Instruction set | MTA ISA |
| Physical specifications | |
| Cores |
|
| Socket(s) | |
| History | |
| Predecessor | Cray MTA-2 CPU |
| Successor | Threadstorm4 |
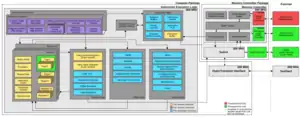
Threadstorm3 (referred to as "MT processor"[2] and Threadstorm before XMT2[8]) is a 64-bit single-core VLIW barrel processor (compatible with 940-pin Socket 940 used by AMD Opteron processors) with 128 hardware streams, onto each a software thread can be mapped (effectively creating 128 hardware threads per CPU), running at 500 MHz and using the MTA instruction set or a superset of it.[7][9][nb 1] It has a 128KB, 4-way associative data buffer. Each Threadstorm3 has 128 separate register sets and program counters (one per each stream), which are fairly[10] fully context-switched at each cycle.[5] Its estimated peak performance is 1.5 GFLOPS. It has 3 functional units (memory, fused multiply-add and control), which receive operations from the same MTA instruction and operate within the same cycle.[7] Each stream has 32 general-purpose registers, 8 target registers and a status word, containing the program counter.[6] High-level control of job allocation across threads is not possible.[5][nb 2] Due to the MTA's pipeline length of 21, each stream is selected to execute instructions again no prior than 21 cycles later.[11] The TDP of the processor package is 30 W.[12]
Due to their thread-level context switch at each cycle, performance of Threadstorm CPUs is not constrained by memory access time. In a simplified model, at each clock cycle an instruction from one of the threads is executed and another memory request is queued with the understanding that by the time the next round of execution is ready the requested data has arrived.[13] This is contrary to many conventional architectures which stall on memory access. The architecture excels in data walking schemes where subsequent memory access cannot be easily predicted and thus wouldn't be well suited to a conventional cache model.[1] Threadstorm's principal architect was Burton J. Smith.[1]
Cray XMT2
| Designer | Cray |
|---|---|
| Bits | 64-bits |
| Introduced | 2011 |
| Version | 4th generation of Tera MTA |
| Endianness | Big-endian |
| Predecessor | Cray XMT |
| Registers | |
| 32 general-purpose per stream (4096 per CPU) 8 target per stream (1024 per CPU) | |
Cray XMT2[3] (also "next-generation XMT"[8] or simply XMT[6]) is a scalable multithreaded shared memory supercomputer by Cray, based on the fourth generation of the Tera MTA architecture.[5] Presented in 2011, it supersedes Cray XMT, which had issues with memory hotspots.[8] It uses Threadstorm4 CPUs inside Cray XT5 blades and increases memory capacity eightfold to 512 TB and memory bandwidth trifold (300 MHz instead 200 MHz) compared to XMT by using twice the memory modules per node and DDR2.[6][8] It introduces the Node Pair Link inter-Threadstorm connect, as well as memory-only nodes, with Threadstorm4 packages having their CPU and HyperTransport 1.x components disabled.[5] The underlying scrambled content-addressable memory model has been inherited from XMT. XMT2 uses 2 additional EMS bits (full/empty and extended) instead of 4 as in XMT.
Threadstorm4
| |
| General information | |
|---|---|
| Launched | 2011 |
| Discontinued | 2015? |
| Designed by | Cray |
| Performance | |
| Max. CPU clock rate | 500 MHz |
| HyperTransport speeds | to 400 GT/s |
| Architecture and classification | |
| Instruction set | MTA ISA |
| Physical specifications | |
| Cores |
|
| Socket(s) | |
| History | |
| Predecessor | Threadstorm3 |
Threadstorm4 (also "Threadstorm IV"[1] and "Threadstorm 4.0"[nb 3]) is a 64-bit single-core VLIW barrel processor (compatible with 1207-pin Socket F used by AMD Opteron processors) with 128 hardware streams, very similar to its predecessor, Threadstorm3. It features an improved, DDR2-capable memory controller and additional 8 trap registers per stream. Cray intentionally decided against a DDR3 controller, citing the reusing of existing Cray XT5 infrastructure[nb 4] and a shorter burst length than DDR3.[nb 5] Though the longer burst length could be compensated by higher speeds of DDR3, it would also require more power, which Cray engineers wanted to avoid.[8]
Scorpio
After launching XMT, Cray researched a possible multi-core variant of the Threadstorm3, dubbed Scorpio. Most of Threadstorm3's features would be retained, including the multiplexing of many hardware streams onto an execution pipeline and the implementation of additional state bits for every 64-bit memory word. Cray later abandoned Scorpio, and the project yielded no manufactured chip.[3]
Future
Development on Threadstorm4, as well as the whole MTA architecture, ended silently after XMT2, probably due to competition from commodity processors such as Intel's Xeon[14] and possibly Xeon Phi, even though Cray never officially discontinued neither XMT nor XMT2. As of 2020, Cray has removed all customer documentation on both XMT and XMT2 from its online catalogue.
Users
Cray XMT2 was bought by several federal laboratories and academic facilities, as well as some commercial HPC clients: e.g. CSCS (2 TB global memory with 64 Threadstorm4 CPUs),[15] Noblis CAHPC.[16] Most of XMT and XMT2-based systems have been decommissioned by 2020.
Notes
- The Tera MTA ISA is closed-sourced and it is only due to a workshop presentation asserting backward-compatibility with previous MTA systems that the ISA used on Threadstorm CPUs cannot be a subset of MTA ISA.
- Though it is not known if it is possible on the instruction-level.
- On physical package.
- Even though the DDR3-based Cray XT6 was launched in 2009, two years prior to XMT2.
- As Cray XMT mostly operates with single 8-byte word random accesses and has a 128-bit memory channel, at DDR2 burst length of 4, the usual overhead is 56 bytes. DDR3 with its burst length of 8 would increase the usual overhead to 120 bytes.
References
- "Why is uRiKA So Fast on Graph-Oriented Queries?". YarcData Blog. November 14, 2012. Archived from the original on February 14, 2015.
- Feo, John; Harper, David; Kahan, Simon; Konecny, Petr (2005). "ELDORADO". Proceedings of the 2nd conference on Computing frontiers - CF '05. Ischia, Italy: ACM Press: 28. doi:10.1145/1062261.1062268. ISBN 978-1-59593-019-4.
- Padua, David, ed. (2011). Encyclopedia of Parallel Computing. Boston, MA: Springer US. pp. 453–457, 2033. doi:10.1007/978-0-387-09766-4. ISBN 978-0-387-09765-7.
- Mizell, David; Maschhoff, Kristyn. "Early experiences with large-scale Cray XMT systems". 2009 IEEE International Symposium on Parallel Distributed Processing: 1–9. doi:10.1109/IPDPS.2009.5161108.
- Maltby, James (2012). Cray XMT Multithreated programming model. "Using the next-generation Cray XMT (uRiKA) for Large Scale Data Analytics." Swiss National Supercomputing Centre.
- Cray XMT™ System Overview (S-2466-201) (PDF). Cray. 2011. Archived (PDF) from the original on December 3, 2012. Retrieved May 12, 2020.
- Konecny, Petr (2011). Introducing the Cray XMT (PDF). Cray.
- Kopser A, Vollrath D (May 2011). Overview of the Next Generation Cray XMT (PDF). 53rd Cray User Group meeting, CUG 2011. Fairbanks, Alaska. Retrieved February 14, 2015.
- Programming the Cray XMT (PDF). Cray. 2012. p. 14.
- Carter, Larry & Feo, John & Snavely, Allan. (2002). Performance and Programming Experience on the Tera MTA.
- Snavely, A.; Carter, L.; Boisseau, J.; Majumdar, A.; Kang Su Gatlin; Mitchell, N.; Feo, J.; Koblenz, B. (1998). "Multi-processor Performance on the Tera MTA". Proceedings of the IEEE/ACM SC98 Conference. Orlando, FL, USA: IEEE: 4–4. doi:10.1109/SC.1998.10049. ISBN 978-0-8186-8707-5.
- Cray XMT Brochure (PDF). Cray. 2005. Archived from the original (PDF) on December 24, 2016.
- Nieplocha J, Marquez A, Petrini F, Chavarria-Miranda D (2007). "Unconventional Architectures for High-Throughput Sciences" (PDF). SciDAC Review. Pacific Northwest National Laboratory (5, Fall 2007): 46–50. Archived from the original (PDF) on February 14, 2015. Retrieved February 14, 2015.
- "Cray CTO Connects The Dots On Future Interconnects". The Next Platform. 8 January 2016. Retrieved 2 May 2016.
Steve Scott: You can do it just great with a Xeon. We are not planning on doing another ThreadStorm processor. But it does take some software technology that comes out of the ThreadStorm legacy.
- "CSCS Matterhorn". Swiss National Supercomputing Centre.
- Sorin, Nita (December 16, 2011). "Cray Delivers XMT Supercomputer Powered by Its Own 128 Thread CPUs". Softpedia News.
Cray computers | ||
|---|---|---|
| Cray Research |  | |
| Cray Computer Corp. | ||
| Cray Research Superservers | ||
| Cray Inc. | ||