Kolakoski sequence
In mathematics, the Kolakoski sequence, sometimes also known as the Oldenburger-Kolakoski sequence,[1] is an infinite sequence of symbols {1,2} that is the sequence of run lengths in its own run-length encoding,[2] and the prototype for an infinite family of related sequences. It is named after the recreational mathematician William Kolakoski (1944–97) who described it in 1965,[3] but subsequent research has shown that the sequence was previously discussed by Rufus Oldenburger in 1939.[1][4]
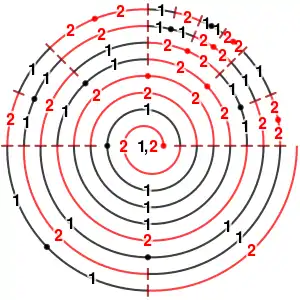
Definition of the classic Kolakoski sequence
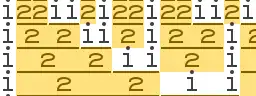
The initial terms of the Kolakoski sequence are:
Each symbol occurs in a "run" (a sequence of equal elements) of either one or two consecutive terms, and writing down the lengths of these runs gives exactly the same sequence:
- 1,2,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,2,2,1,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,2,2,...
- 1, 2 , 2 ,1,1, 2 ,1, 2 , 2 ,1, 2 , 2 ,1,1, 2 ,1,1, 2 , 2 ,1, 2 ,1,1, 2 ,1, 2 , 2 ,1,1, 2 ,...
The description of the Kolakoski sequence is therefore reversible. If K stands for "the Kolakoski sequence", description #1 logically implies description #2 (and vice versa):
- 1. The terms of K are generated by the runs (i.e., run-lengths) of K
- 2. The runs of K are generated by the terms of K
Accordingly, one can say that each term of the Kolakoski sequence generates a run of one or two future terms. The first 1 of the sequence generates a run of "1", i.e. itself; the first 2 generates a run of "22", which includes itself; the second 2 generates a run of "11"; and so on. Each number in the sequence is the length of the next run to be generated, and the element to be generated alternates between 1 and 2:
- 1,2 (length of sequence l = 2; sum of terms s = 3)
- 1,2,2 (l = 3, s = 5)
- 1,2,2,1,1 (l = 5, s = 7)
- 1,2,2,1,1,2,1 (l = 7, s = 10)
- 1,2,2,1,1,2,1,2,2,1 (l = 10, s = 15)
- 1,2,2,1,1,2,1,2,2,1,2,2,1,1,2 (l = 15, s = 23)
As can be seen, the length of the sequence at each stage is equal to the sum of terms in the previous stage. This animation illustrates the process:
These self-generating properties, which remain if the sequence is written without the initial 1, mean that the Kolakoski sequence can be described as a fractal, or mathematical object that encodes its own representation on other scales.[1] Bertran Steinsky has created a recursive formula for the i-th term of the sequence[5] but the sequence is believed to be aperiodic,[6] that is, its terms do not have a general repeating pattern (cf. irrational numbers like π and √2).
Other self-generating Kolakoski sequences
From finite integer alphabets
The Kolakoski sequence is the prototype for an infinite family of other sequences that are each their own run-length encodings. Each sequence is based on what is formally called an alphabet of integers. For example, the classic Kolakoski sequence described above has the alphabet {1,2}. Some of the additional Kolakoski sequences listed at the OEIS are:
- With alphabet {1,3}
- 1,3,3,3,1,1,1,3,3,3,1,3,1,3,3,3,1,1,1,3,3,3,1,3,3,3,1,3,3,3,1,1,1,3,3,3,1,3,1,3,3,3,1,1,1,3,3,3,1,3,3,3,1,1,1,3,3,3,1,3,3,3,... (sequence A064353 in the OEIS)
- With alphabet {2,3}
- 2,2,3,3,2,2,2,3,3,3,2,2,3,3,2,2,3,3,3,2,2,2,3,3,3,2,2,3,3,2,2,2,3,3,3,2,2,3,3,2,2,2,3,3,3,2,2,2,3,3,2,2,3,3,2,2,2,3,3,3,... (sequence A071820 in the OEIS)
- With alphabet {1,2,3}
- 1,2,2,3,3,1,1,1,2,2,2,3,1,2,3,3,1,1,2,2,3,3,3,1,2,2,3,3,3,1,1,1,2,3,1,1,2,2,3,3,3,1,1,1,2,2,2,3,1,1,2,2,3,3,3,1,1,1,2,2,2,... (sequence A079729 in the OEIS)
Like the Kolakoski {1,2}-sequence, writing the run-lengths returns the same sequence. More generally, any alphabet of integers, {n1,n2,..ni}, can generate a Kolakoski sequence if the same integer does not occur 1) twice or more in a row; 2) at the beginning and end of the alphabet. For example, the alphabet {3,1,2} generates:
- 3,3,3,1,1,1,2,2,2,3,1,2,3,3,1,1,2,2,3,3,3,1,2,2,3,3,3,1,1,1,2,3,1,1,2,2,3,3,3,1,1,1,2,2,2,3,1,1,2,2,3,3,3,1,1,1,2,2,2,3,1,2,...
And the alphabet {2,1,3,1} generates:
- 2,2,1,1,3,1,2,2,2,1,3,3,1,1,2,2,1,3,3,3,1,1,1,2,1,3,3,1,1,2,1,1,1,3,3,3,1,1,1,2,1,3,1,1,2,1,1,1,3,3,3,1,2,1,1,3,1,2,1,1,1,...
Again, writing the run-lengths returns the same sequence.
From infinite integer alphabets
Kolakoski sequences can also be created from infinite alphabets of integers, such as {1,2,1,3,1,4,1,5,...}:
- 1,2,2,1,1,3,1,4,4,4,1,5,5,5,5,1,1,1,1,6,6,6,6,1,7,7,7,7,7,1,1,1,1,1,8,8,8,8,8,1,1,1,1,1,9,1,10,1,11,11,11,11,11,11,...
The infinite alphabet {1,2,3,4,5,...} generates the Golomb sequence:
- 1,2,2,3,3,4,4,4,5,5,5,6,6,6,6,7,7,7,7,8,8,8,8,9,9,9,9,9,10,10,10,10,10,11,11,11,11,11,12,12,12,12,12,12,... (sequence A001462 in the OEIS)
A Kolakoski sequence can also be created from integers chosen at random from a finite alphabet, with the restriction that the same number cannot be chosen twice in a row. If the finite alphabet is {1,2,3}, one possible sequence is this:
- 2,2,1,1,3,1,3,3,3,2,1,1,1,2,2,2,1,1,1,3,3,2,1,3,2,2,3,3,2,2,3,1,3,1,1,1,3,3,3,1,1,3,2,2,2,3,3,1,1,3,3,3,1,1,1,3,3,1,1,2,2,2,...
In effect, the sequence is based on the infinite alphabet {2,1,3,1,3,2,1,2,1,3,2,...}, which contains a random sequence of 1s, 2s and 3s from which repeats have been removed.
Chain sequences
Whereas the classic Kolakoski {1,2}-sequence generates itself, these two sequences generate each other:
- 1,1,2,1,1,2,2,1,2,2,1,2,1,1,2,2,1,2,2,1,1,2,1,2,2,1,2,1,1,2,1,1,2,2,1,2,1,1,2,1,2,2,1,1,2,1,1,2,1,2,2,... (sequence A025142 in the OEIS)
- 2,1,2,2,1,2,1,1,2,2,1,2,2,1,1,2,1,1,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,1,2,2,1,2,2,1,2,1,1,2,1,2,2,... (sequence A025143 in the OEIS)
In other words, if you write the run-lengths of the first sequence, you generate the second; if you write the run-lengths of the second, you generate the first. In the following chain of three sequences, the run-lengths of each generate the next in the order 1 → 2 → 3 → 1:
- seq(1) = 1,1,2,2,3,3,1,1,1,2,3,1,1,2,2,3,3,3,1,1,1,2,2,2,3,1,2,3,3,1,1,1,2,3,3,... (sequence A288723 in the OEIS)
- seq(2) = 2,2,2,3,1,1,2,2,3,3,3,1,1,1,2,3,1,2,2,3,3,1,1,2,2,2,3,1,1,2,2,2,3,3,3,... (sequence A288724 in the OEIS)
- seq(3) = 3,1,2,2,3,3,1,1,1,2,2,2,3,1,2,3,3,1,1,1,2,3,1,1,2,2,3,3,3,1,1,1,2,2,2,... (sequence A288725 in the OEIS)
The sequences use the integer alphabet {1,2,3}, but each starts at a different point in the alphabet. The following five sequences form a similar chain using the alphabet {1,2,3,4,5}:
- seq(1) = 1,1,2,2,3,3,4,4,4,5,5,5,1,1,1,2,2,2,2,3,3,3,3,4,4,4,4,5,5,5,5,5,...
- seq(2) = 2,2,2,3,3,3,4,4,4,5,5,5,1,1,1,1,2,2,2,2,3,3,3,3,4,4,4,4,5,5,5,5,5,...
- seq(3) = 3,3,3,3,4,4,4,4,5,5,5,5,1,1,1,1,2,2,2,2,3,3,3,3,3,4,5,1,1,2,2,3,3,3,...
- seq(4) = 4,4,4,4,4,5,1,1,2,2,3,3,3,4,4,4,5,5,5,5,1,1,1,1,2,2,2,2,3,3,3,3,3,...
- seq(5) = 5,1,2,2,3,3,4,4,4,5,5,5,1,1,1,1,2,2,2,2,3,3,3,3,4,4,4,4,4,...
However, to create a sequence-chain of length l, it is not necessary to have distinct integer alphabets of size l. For example, the alphabet-series {2,1}, {1,2}, {1,2}, {1,2} and {1,2} is sufficient for a five-link chain:
- seq(1) = 2,1,1,2,2,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,1,2,2,1,...
- seq(2) = 1,2,2,1,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,2,2,1,2,1,1,2,1,1,2,2,1,2,2,...
- seq(3) = 1,2,2,1,2,1,1,2,1,2,2,1,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,...
- seq(4) = 1,2,1,1,2,1,1,2,2,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,...
- seq(5) = 1,1,2,1,2,2,1,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,2,2,...
Each sequence is unique and the run-lengths of each generate the terms of the next sequence in the chain. The integer alphabets used to generate a chain can also be of different sizes. A Kolakoski mirror (as a two-link chain might be called) can be created from the alphabets {1,2} and {1,2,3,4,5}:
- seq(1) = 1,2,2,1,1,2,2,2,1,1,1,2,2,2,2,1,1,1,1,1,2,1,2,2,1,1,2,2,2,...
- seq(2) = 1,2,2,3,3,4,5,1,1,2,2,3,3,4,5,1,2,2,3,3,4,4,5,5,1,2,3,4,5,...
Research into the classic sequence
Density of the sequence
It seems plausible that the density of 1s in the Kolakoski {1,2}-sequence is 1/2, but this conjecture remains unproved.[6] Václav Chvátal has proved that the upper density of 1s is less than 0.50084.[7] Nilsson has used the same method with far greater computational power to obtain the bound 0.500080.[8]
Although calculations of the first 3×108 values of the sequence appeared to show its density converging to a value slightly different from 1/2,[5] later calculations that extended the sequence to its first 1013 values show the deviation from a density of 1/2 growing smaller, as one would expect if the limiting density actually is 1/2.[9]
Connection with tag systems
Stephen Wolfram describes the Kolakoski sequence in connection with the history of cyclic tag systems.[10]
Uniqueness of the sequence
Some discussions of the classic Kolakoski sequence make the claim that, written with or without the initial 1, it is the "only sequence" that is its own run-length encoding or the only such sequence that begins with 1.[11][6] As can be seen above, this is untrue: an infinite number of additional sequences possess these properties. However, the Kolakoski {1,2}- and {2,1}-sequences are the only such sequences using solely the integers 1 and 2.
Anti-Kolakoski sequence
In the anti-Kolakoski sequence, the run-lengths of 1s and 2s never coincide with the terms of the original sequence:
- 2,1,1,2,2,1,2,1,1,2,1,1,2,2,1,2,2,1,1,2,1,2,2,1,2,1,1,2,2,1,2,2,1,2,1,1,... (sequence A049705 in the OEIS)
- 2,1,1,2,2,1,2,1,1,2,1,1,2,2,1,2,2,1,1,2,1,2,2,1,2,1,1,2,2,...
- 1, 2 , 2 ,1,1, 2 ,1, 2 , 2 ,1, 2 , 2 ,1,1, 2 ,1,1, 2 , 2 ,...
As can be seen, the run-lengths of the anti-Kolakoski sequence return the Kolakoski {1,2}-sequence, which means that the former can be created from the latter by simple subtraction. If k(i) is the i-th term of the Kolakoski {1,2}-sequence and ak(i) is the i-th term of the anti-Kolakoski sequence, then ak(i) = 3-k(i), just as k(i) = 3-ak(i).[12] Accordingly, like the Kolakoski sequence, the anti-Kolakoski sequence retains its defining property when written without its initial term, i.e. 2.[12]
Kolakoski Constant
The so-called Kolakoski constant is created by subtracting 1 from each term of the Kolakoski {2,1}-sequence (which begins 22112122122...) and treating the result as a binary fraction.[13]
- 0.11001011011001001101001011001001011... = 2−1 + 2−2 + 2−5 + 2−7 + 2−8 + 2−10 + 2−11 + 2−14 + 2−17 + 2−18 + 2−20 + 2−23 + 2−25 + 2−26 + 2−29... = 0.7945071927794792762403624156360456462...[14]
Algorithms
Algorithm for the Kolakoski {1,2}-sequence
The Kolakoski {1,2}-sequence may be generated by an algorithm that, in the i-th iteration, reads the value xi that has already been output as the i-th value of the sequence (or, if no such value has been output yet, sets xi = i). Then, if i is odd, it outputs xi copies of the number 1, while if i is even, it outputs xi copies of the number 2. Thus, the first few steps of the algorithm are:
- The first value has not yet been output, so set x1 = 1, and output 1 copy of the number 1
- The second value has not yet been output, so set x2 = 2, and output 2 copies of the number 2
- The third value x3 was output as 2 in the second step, so output 2 copies of the number 1.
- The fourth value x4 was output as 1 in the third step, so output 1 copy of the number 2. Etc.
This algorithm takes linear time, but because it needs to refer back to earlier positions in the sequence it needs to store the whole sequence, taking linear space. An alternative algorithm that generates multiple copies of the sequence at different speeds, with each copy of the sequence using the output of the previous copy to determine what to do at each step, can be used to generate the sequence in linear time and only logarithmic space.[9]
General algorithm for Kolakoski sequences
In general, a Kolakoski sequence for any integer alphabet {n1, n2,..nj} may be generated by an algorithm that, in the i-th iteration, reads the value xi that has already been output as the i-th value of the sequence (or, if no such value has been output yet, sets xi = ni). At each step, the output ni is adjusted according to the size of the alphabet, reverting to n1 when the final position in the alphabet is exceeded. The first few steps of the algorithm for the alphabet {1,2,3,4} are:
- The first value has not yet been output, so set x1 = 1 = n1, and output 1 copy of the number 1
- The second value has not yet been output, so set x2 = 2 = n2, and output 2 copies of the number 2
- The third value x3 was output as 2 in the second step, so output 2 copies of 3 = n3.
- The fourth value x4 was output as 3 in the third step, so output 3 copies of 4 = n4.
- The fifth value x5 was output as 3 in the third step, so output 3 copies of the number 1 = n1=adjusted(5).
- The sixth value x6 was output as 4 in the fourth step, so output 4 copies of the number 2 = n2=adjusted(6). Etc.
The resultant sequence is:
Algorithm for Kolakoski-chains
Kolakoski chains of any desired length can be generated with a simple algorithm. Suppose that one wishes to generate a chain with 3 sequences where the terms of seq(i) are generated by the run-lengths of seq(i+1) and the alphabet is {1,2}. Begin by setting the first term of seq(1), the initial sequence in the chain, to the value of 2. The next sequence in the chain, seq(2), whose run-lengths generate the terms of seq(1), must therefore have the terms (1,1). Therefore seq(3), whose run-lengths generate seq(2) = (1,1), must have the runs (1,2). Here is the first stage of the algorithm:
- Stage 1
- seq(1) = 2
- seq(2) = 1,1
- seq(3) = 1,2
Now, note that the run-lengths of seq(1) generate the terms of seq(3), which means that the terms of seq(3) generate the runs of seq(1). Because seq(3) = (1,2) after stage 1 of the algorithm, seq(1) must equal (2,1,1) in the next stage. From this extended seq(1), one can generate further runs (and terms) of seq(2), then further runs (and terms) of seq(3):
- Stage 2
- seq(1) = 2,1,1
- seq(2) = 1,1,2,1
- seq(3) = 1,2,1,1,2
Now use the terms of seq(3) in stage 2 to generate further runs of seq(1) in stage 3:
- Stage 3
- seq(1) = 2,1,1,2,1,2,2
- seq(2) = 1,1,2,1,2,2,1,2,2,1,1
- seq(3) = 1,2,1,1,2,1,1,2,2,1,2,2,1,1,2,1
- Stage 4
- seq(1) = 2,1,1,2,1,2,2,1,2,1,1,2,2,1,2,2,1,1,2,1,2,2,1
- seq(2) = 1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,1,2,...
- seq(3) = 1,2,1,1,2,1,1,2,2,1,2,2,1,1,2,1,2,2,1,2,1,1,2,1,1,2,2,1,2,1,1,2,1,...
- Stage 5
- seq(1) = 2,1,1,2,1,2,2,1,2,1,1,2,2,1,2,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,1,2,...
- seq(2) = 1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,1,2,...
- seq(3) = 1,2,1,1,2,1,1,2,2,1,2,2,1,1,2,1,2,2,1,2,1,1,2,1,1,2,2,1,2,1,1,2,1,...
The sequences can now be re-arranged so that the run-lengths of seq(i) generate the terms of seq(i+1) (where seq(3+1) = seq(1)):
- seq(1) = 2,1,1,2,1,2,2,1,2,1,1,2,2,1,2,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,1,2,...
- seq(2) = 1,2,1,1,2,1,1,2,2,1,2,2,1,1,2,1,2,2,1,2,1,1,2,1,1,2,2,1,2,1,1,2,1,...
- seq(3) = 1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,1,2,...
If the chain has 5 sequences, the algorithm yields these stages:
- Stage 1
- seq(1) = 2
- seq(2) = 1,1
- seq(3) = 1,2
- seq(4) = 1,2,2
- seq(5) = 1,2,2,1,1
- Stage 2
- seq(1) = 2,1,1,2,2,1,2
- seq(2) = 1,1,2,1,2,2,1,1,2,1,1
- seq(3) = 1,2,1,1,2,1,1,2,2,1,2,1,1,2,1
- seq(4) = 1,2,2,1,2,1,1,2,1,2,2,1,1,2,1,1,2,1,2,2,1
- seq(5) = 1,2,2,1,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,2,2,1,2,1,1,2,1,1,2,2,1
- Stage 3
- seq(1) = 2,1,1,2,2,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,1,2,2,1,...
- seq(2) = 1,1,2,1,2,2,1,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,2,2,...
- seq(3) = 1,2,1,1,2,1,1,2,2,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,...
- seq(4) = 1,2,2,1,2,1,1,2,1,2,2,1,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,...
- seq(5) = 1,2,2,1,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,2,2,1,2,1,1,2,1,1,2,2,1,2,2,...
Finally, the sequences are re-arranged so that the run-lengths of seq(i) generate the terms of seq(i+1):
- seq(1) = 2,1,1,2,2,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,1,2,2,1,...
- seq(2) = 1,2,2,1,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,2,2,1,2,1,1,2,1,1,2,2,1,2,2,...
- seq(3) = 1,2,2,1,2,1,1,2,1,2,2,1,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,...
- seq(4) = 1,2,1,1,2,1,1,2,2,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,...
- seq(5) = 1,1,2,1,2,2,1,1,2,1,1,2,1,2,2,1,2,2,1,1,2,1,1,2,2,1,2,1,1,2,1,2,2,...
See also
- Golomb sequence — another self-generating sequence based on run-length
- Gijswijt's sequence
- Look-and-say sequence
Notes
- Sloane, N. J. A. (ed.). "Sequence A000002 (Kolakoski sequence: a(n) is length of n-th run; a(1) = 1; sequence consists just of 1's and 2's)". The On-Line Encyclopedia of Integer Sequences. OEIS Foundation.
- Pytheas Fogg, N. (2002). Berthé, Valérie; Ferenczi, Sébastien; Mauduit, Christian; Siegel, A. (eds.). Substitutions in dynamics, arithmetics and combinatorics. Lecture Notes in Mathematics. 1794. Berlin: Springer-Verlag. p. 93. ISBN 3-540-44141-7. Zbl 1014.11015.
- Kolakoski, William (1965). "Problem 5304". American Mathematical Monthly. 72: 674. doi:10.2307/2313883. For a partial solution, see Üçoluk, Necdet (1966). "Self Generating Runs". American Mathematical Monthly. 73: 681–682. doi:10.2307/2314839.
- Oldenburger, Rufus (1939). "Exponent trajectories in symbolic dynamics". Transactions of the American Mathematical Society. 46: 453–466. doi:10.2307/198993. MR 0000352.
- Steinsky, Bertran (2006). "A recursive formula for the Kolakoski sequence A000002" (PDF). Journal of Integer Sequences. 9 (3). Article 06.3.7. MR 2240857. Zbl 1104.11012.
- Kimberling, Clark. "Integer Sequences and Arrays". University of Evansville. Retrieved 2016-10-13.
- Chvátal, Vašek (December 1993). Notes on the Kolakoski Sequence. Technical Report 93-84. DIMACS.
- Nilsson, J. "Letter Frequencies in the Kolakoski Sequence" (PDF). Acta Physics Polonica A. Retrieved 2014-04-24.
- Nilsson, Johan (2012). "A space-efficient algorithm for calculating the digit distribution in the Kolakoski sequence" (PDF). Journal of Integer Sequences. 15 (6): Article 12.6.7, 13. MR 2954662.
- Wolfram, Stephen (2002). A New Kind of Science. Champaign, IL: Wolfram Media, Inc. p. 895. ISBN 1-57955-008-8. MR 1920418.
- Bellos, Alex (7 October 2014). "Neil Sloane: the man who loved only integer sequences". The Guardian. Retrieved 13 June 2017.
- Anti-Kolakoski sequence (sequence of run lengths never coincides with the sequence itself).
- "Kolakoski Sequence at MathWorld". Retrieved 2017-06-16.
- Gerard, Olivier. "Kolakoski Constant to 25000 digits". Retrieved 2017-06-16.
Further reading
- Allouche, Jean-Paul; Shallit, Jeffrey (2003). Automatic Sequences: Theory, Applications, Generalizations. Cambridge University Press. p. 337. ISBN 978-0-521-82332-6. Zbl 1086.11015.
- Dekking, F. M. (1997). "What Is the Long Range Order in the Kolakoski Sequence?". In Moody, R. V. (ed.). Proceedings of the NATO Advanced Study Institute, Waterloo, ON, August 21-September 1, 1995. Dordrecht, Netherlands: Kluwer. pp. 115–125.
- Fedou, J. M.; Fici, G. (2010). "Some remarks on differentiable sequences and recursivity" (PDF). Journal of Integer Sequences. 13 (3). Article 10.3.2.
- Keane, M. S. (1991). "Ergodic Theory and Subshifts of Finite Type". In Bedford, T.; Keane, M. (eds.). Ergodic Theory, Symbolic Dynamics and Hyperbolic Spaces. Oxford, England: Oxford University Press. pp. 35–70.
- Lagarias, J. C. (1992). "Number Theory and Dynamical Systems". In Burr, S. A. (ed.). The Unreasonable Effectiveness of Number Theory. Providence, RI: American Mathematical Society. pp. 35–72.
- Păun, Gheorghe; Salomaa, Arto (1996). "Self-Reading Sequences". American Mathematical Monthly. 103: 166–168. doi:10.2307/2975113. Zbl 0854.68082.
- Shallit, Jeffrey (1999). "Number theory and formal languages". In Hejhal, Dennis A.; Friedman, Joel; Gutzwiller, Martin C.; Odlyzko, Andrew M. (eds.). Emerging applications of number theory. Based on the proceedings of the IMA summer program, Minneapolis, MN, USA, July 15--26, 1996. The IMA volumes in mathematics and its applications. 109. Springer-Verlag. pp. 547–570. ISBN 0-387-98824-6. Zbl 0919.00047.
External links
- Weisstein, Eric W. "Kolakoski Sequence". MathWorld.
- Kolakoski Constant to 25000 digits as computed by Olivier Gerard in April 1998
- Bellos, Alex. "The Kolakoski Sequence" (video). Brady Haran. Retrieved 24 July 2017.

{kind=link}