Kubernetes
Kubernetes (/ˌk(j)uːbərˈnɛtɪs, -ˈneɪtɪs, -ˈneɪtiːz/, commonly stylized as K8s[4]) is an open-source container-orchestration system for automating computer application deployment, scaling, and management.[5]
| Original author(s) | |
|---|---|
| Developer(s) | Cloud Native Computing Foundation |
| Initial release | 7 June 2014[1] |
| Stable release | |
| Repository | |
| Written in | Go |
| Type | Cluster management software |
| License | Apache License 2.0 |
| Website | kubernetes |
It was originally designed by Google and is now maintained by the Cloud Native Computing Foundation. It aims to provide a "platform for automating deployment, scaling, and operations of application containers across clusters of hosts".[6] It works with a range of container tools and runs containers in a cluster, often with images built using Docker. Kubernetes originally interfaced with the Docker runtime[7] through a "Dockershim"; however, the shim has since been deprecated in favor of directly interfacing with containerd or another CRI-compliant runtime.[8]
Many cloud services offer a Kubernetes-based platform or infrastructure as a service (PaaS or IaaS) on which Kubernetes can be deployed as a platform-providing service. Many vendors also provide their own branded Kubernetes distributions.
History

Kubernetes (κυβερνήτης, Greek for "helmsman" or "pilot" or "governor", and the etymological root of cybernetics)[6] was founded by Joe Beda, Brendan Burns, and Craig McLuckie,[9] who were quickly joined by other Google engineers including Brian Grant and Tim Hockin, and was first announced by Google in mid-2014.[10] Its development and design are heavily influenced by Google's Borg system,[11][12] and many of the top contributors to the project previously worked on Borg. The original codename for Kubernetes within Google was Project 7, a reference to the Star Trek ex-Borg character Seven of Nine.[13] The seven spokes on the wheel of the Kubernetes logo are a reference to that codename. The original Borg project was written entirely in C++,[11] but the rewritten Kubernetes system is implemented in Go.
Kubernetes v1.0 was released on July 21, 2015.[14] Along with the Kubernetes v1.0 release, Google partnered with the Linux Foundation to form the Cloud Native Computing Foundation (CNCF)[15] and offered Kubernetes as a seed technology. In February 2016[16] Helm[17][18] package manager for Kubernetes was released. On March 6, 2018, Kubernetes Project reached ninth place in commits at GitHub, and second place in authors and issues, after the Linux kernel.[19]
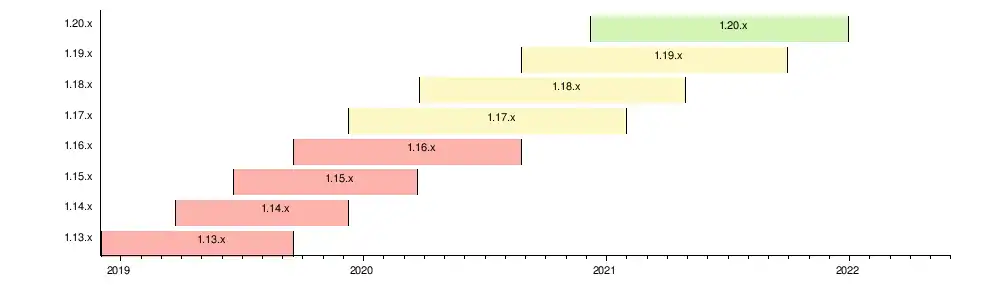
Up to v1.18, Kubernetes followed an N-2 support policy[20] (meaning that the 3 most recent minor versions receive security and bug fixes)
From v1.19 onwards, Kubernetes will follow an N-3 support policy.[21]
Concepts
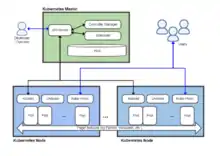
Kubernetes defines a set of building blocks ("primitives"), which collectively provide mechanisms that deploy, maintain, and scale applications based on CPU, memory[24] or custom metrics.[25] Kubernetes is loosely coupled and extensible to meet different workloads. This extensibility is provided in large part by the Kubernetes API, which is used by internal components as well as extensions and containers that run on Kubernetes.[26] The platform exerts its control over compute and storage resources by defining resources as Objects, which can then be managed as such.
Kubernetes follows the primary/replica architecture. The components of Kubernetes can be divided into those that manage an individual node and those that are part of the control plane.[26][27]
Control plane
The Kubernetes master is the main controlling unit of the cluster, managing its workload and directing communication across the system. The Kubernetes control plane consists of various components, each its own process, that can run both on a single master node or on multiple masters supporting high-availability clusters.[27] The various components of the Kubernetes control plane are as follows:
- etcd: etcd[28] is a persistent, lightweight, distributed, key-value data store developed by CoreOS that reliably stores the configuration data of the cluster, representing the overall state of the cluster at any given point of time. Just like Apache ZooKeeper, etcd is a system that favors consistency over availability in the event of a network partition (see CAP theorem). This consistency is crucial for correctly scheduling and operating services. The Kubernetes API Server uses etcd's watch API to monitor the cluster and roll out critical configuration changes or simply restore any divergences of the state of the cluster back to what was declared by the deployer. As an example, if the deployer specified that three instances of a particular pod need to be running, this fact is stored in etcd. If it is found that only two instances are running, this delta will be detected by comparison with etcd data, and Kubernetes will use this to schedule the creation of an additional instance of that pod.[27]
- API server: The API server is a key component and serves the Kubernetes API using JSON over HTTP, which provides both the internal and external interface to Kubernetes.[26][29] The API server processes and validates REST requests and updates state of the API objects in etcd, thereby allowing clients to configure workloads and containers across Worker nodes.[30]
- Scheduler: The scheduler is the pluggable component that selects which node an unscheduled pod (the basic entity managed by the scheduler) runs on, based on resource availability. The scheduler tracks resource use on each node to ensure that workload is not scheduled in excess of available resources. For this purpose, the scheduler must know the resource requirements, resource availability, and other user-provided constraints and policy directives such as quality-of-service, affinity/anti-affinity requirements, data locality, and so on. In essence, the scheduler's role is to match resource "supply" to workload "demand".[31]
- Controller manager: A controller is a reconciliation loop that drives actual cluster state toward the desired cluster state, communicating with the API server to create, update, and delete the resources it manages (pods, service endpoints, etc.).[32][29] The controller manager is a process that manages a set of core Kubernetes controllers. One kind of controller is a Replication Controller, which handles replication and scaling by running a specified number of copies of a pod across the cluster. It also handles creating replacement pods if the underlying node fails.[32] Other controllers that are part of the core Kubernetes system include a DaemonSet Controller for running exactly one pod on every machine (or some subset of machines), and a Job Controller for running pods that run to completion, e.g. as part of a batch job.[33] The set of pods that a controller manages is determined by label selectors that are part of the controller's definition.[34]
Nodes
A Node, also known as a Worker or a Minion, is a machine where containers (workloads) are deployed. Every node in the cluster must run a container runtime such as Docker, as well as the below-mentioned components, for communication with the primary for network configuration of these containers.
- Kubelet: Kubelet is responsible for the running state of each node, ensuring that all containers on the node are healthy. It takes care of starting, stopping, and maintaining application containers organized into pods as directed by the control plane.[26][35]
- Kubelet monitors the state of a pod, and if not in the desired state, the pod re-deploys to the same node. Node status is relayed every few seconds via heartbeat messages to the primary. Once the primary detects a node failure, the Replication Controller observes this state change and launches pods on other healthy nodes.
- Kube-proxy: The Kube-proxy is an implementation of a network proxy and a load balancer, and it supports the service abstraction along with other networking operation.[26] It is responsible for routing traffic to the appropriate container based on IP and port number of the incoming request.
- Container runtime: A container resides inside a pod. The container is the lowest level of a micro-service, which holds the running application, libraries, and their dependencies. Containers can be exposed to the world through an external IP address. Kubernetes has supported Docker containers since its first version, and in July 2016 the rkt container engine was added.[36]
Pods
The basic scheduling unit in Kubernetes is a pod.[37] A pod is a grouping of containerized components. A pod consists of one or more containers that are guaranteed to be co-located on the same node.[26]
Each pod in Kubernetes is assigned a unique IP address within the cluster, which allows applications to use ports without the risk of conflict.[38] Within the pod, all containers can reference each other on localhost, but a container within one pod has no way of directly addressing another container within another pod; for that, it has to use the Pod IP Address. An application developer should never use the Pod IP Address though, to reference / invoke a capability in another pod, as Pod IP addresses are ephemeral - the specific pod that they are referencing may be assigned to another Pod IP address on restart. Instead, they should use a reference to a Service, which holds a reference to the target pod at the specific Pod IP Address.
A pod can define a volume, such as a local disk directory or a network disk, and expose it to the containers in the pod.[39] Pods can be managed manually through the Kubernetes API, or their management can be delegated to a controller.[26] Such volumes are also the basis for the Kubernetes features of ConfigMaps (to provide access to configuration through the filesystem visible to the container) and Secrets (to provide access to credentials needed to access remote resources securely, by providing those credentials on the filesystem visible only to authorized containers).
ReplicaSets
A ReplicaSet’s purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods.[40]
The ReplicaSets[41] can also be said to be a grouping mechanism that lets Kubernetes maintain the number of instances that have been declared for a given pod. The definition of a Replica Set uses a selector, whose evaluation will result in identifying all pods that are associated with it.
Services
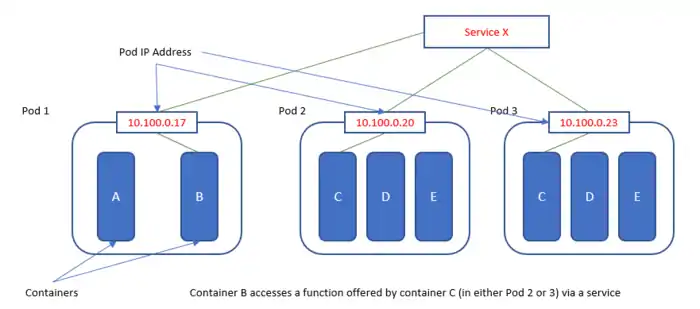
A Kubernetes service is a set of pods that work together, such as one tier of a multi-tier application. The set of pods that constitute a service are defined by a label selector.[26] Kubernetes provides two modes of service discovery, using environmental variables or using Kubernetes DNS.[42] Service discovery assigns a stable IP address and DNS name to the service, and load balances traffic in a round-robin manner to network connections of that IP address among the pods matching the selector (even as failures cause the pods to move from machine to machine).[38] By default a service is exposed inside a cluster (e.g., back end pods might be grouped into a service, with requests from the front-end pods load-balanced among them), but a service can also be exposed outside a cluster (e.g., for clients to reach front-end pods).[43]
Volumes
Filesystems in the Kubernetes container provide ephemeral storage, by default. This means that a restart of the pod will wipe out any data on such containers, and therefore, this form of storage is quite limiting in anything but trivial applications. A Kubernetes Volume[44] provides persistent storage that exists for the lifetime of the pod itself. This storage can also be used as shared disk space for containers within the pod. Volumes are mounted at specific mount points within the container, which are defined by the pod configuration, and cannot mount onto other volumes or link to other volumes. The same volume can be mounted at different points in the filesystem tree by different containers.
Namespaces
Kubernetes provides a partitioning of the resources it manages into non-overlapping sets called namespaces.[45] They are intended for use in environments with many users spread across multiple teams, or projects, or even separating environments like development, test, and production.
ConfigMaps and Secrets
A common application challenge is deciding where to store and manage configuration information, some of which may contain sensitive data. Configuration data can be anything as fine-grained as individual properties or coarse-grained information like entire configuration files or JSON / XML documents. Kubernetes provides two closely related mechanisms to deal with this need: "configmaps" and "secrets", both of which allow for configuration changes to be made without requiring an application build. The data from configmaps and secrets will be made available to every single instance of the application to which these objects have been bound via the deployment. A secret and / or a configmap is only sent to a node if a pod on that node requires it. Kubernetes will keep it in memory on that node. Once the pod that depends on the secret or configmap is deleted, the in-memory copy of all bound secrets and configmaps are deleted as well. The data is accessible to the pod through one of two ways: a) as environment variables (which will be created by Kubernetes when the pod is started) or b) available on the container filesystem that is visible only from within the pod.
The data itself is stored on the master which is a highly secured machine which nobody should have login access to. The biggest difference between a secret and a configmap is that the content of the data in a secret is base64 encoded. Recent versions of Kubernetes have introduced support for encryption to be used as well. Secrets are often used to store data like certificates, passwords, pull secrets (credentials to work with image registries), and ssh keys.
StatefulSets
It is very easy to address the scaling of stateless applications: one simply adds more running pods—which is something that Kubernetes does very well. Stateful workloads are much harder, because the state needs to be preserved if a pod is restarted, and if the application is scaled up or down, then the state may need to be redistributed. Databases are an example of stateful workloads. When run in high-availability mode, many databases come with the notion of a primary instance and secondary instance(s). In this case, the notion of ordering of instances is important. Other applications like Kafka distribute the data amongst their brokers—so one broker is not the same as another. In this case, the notion of instance uniqueness is important. StatefulSets[46] are controllers (see Controller Manager, below) that are provided by Kubernetes that enforce the properties of uniqueness and ordering amongst instances of a pod and can be used to run stateful applications.
DaemonSets
Normally, the locations where pods are run are determined by the algorithm implemented in the Kubernetes Scheduler. For some use cases, though, there could be a need to run a pod on every single node in the cluster. This is useful for use cases like log collection, ingress controllers, and storage services. The ability to do this kind of pod scheduling is implemented by the feature called DaemonSets.[47]
Labels and selectors
Kubernetes enables clients (users or internal components) to attach keys called "labels" to any API object in the system, such as pods and nodes. Correspondingly, "label selectors" are queries against labels that resolve to matching objects.[26] When a service is defined, one can define the label selectors that will be used by the service router / load balancer to select the pod instances that the traffic will be routed to. Thus, simply changing the labels of the pods or changing the label selectors on the service can be used to control which pods get traffic and which don't, which can be used to support various deployment patterns like blue-green deployments or A-B testing. This capability to dynamically control how services utilize implementing resources provides a loose coupling within the infrastructure.
For example, if an application's pods have labels for a system tier (with values such as front-end, back-end, for example) and a release_track (with values such as canary, production, for example), then an operation on all of back-end and canary nodes can use a label selector, such as:[34]
tier=back-end AND release_track=canary
Just like labels, field selectors also let one select Kubernetes resources. Unlike labels, the selection is based on the attribute values inherent to the resource being selected, rather than user-defined categorization. metadata.name and metadata.namespace are field selectors that will be present on all Kubernetes objects. Other selectors that can be used depend on the object/resource type.
Replication Controllers and Deployments
A ReplicaSet declares the number of instances of a pod that is needed, and a Replication Controller manages the system so that the number of healthy pods that are running matches the number of pods declared in the ReplicaSet (determined by evaluating its selector).
Deployments are a higher level management mechanism for ReplicaSets. While the Replication Controller manages the scale of the ReplicaSet, Deployments will manage what happens to the ReplicaSet - whether an update has to be rolled out, or rolled back, etc. When deployments are scaled up or down, this results in the declaration of the ReplicaSet changing - and this change in declared state is managed by the Replication Controller.
Add-ons
Add-ons operate just like any other application running within the cluster: they are implemented via pods and services, and are only different in that they implement features of the Kubernetes cluster. The pods may be managed by Deployments, ReplicationControllers, and so on. There are many add-ons, and the list is growing. Some of the more important are:
- DNS: All Kubernetes clusters should have cluster DNS; it is a mandatory feature. Cluster DNS is a DNS server, in addition to the other DNS server(s) in your environment, which serves DNS records for Kubernetes services. Containers started by Kubernetes automatically include this DNS server in their DNS searches.
- Web UI: This is a general purpose, web-based UI for Kubernetes clusters. It allows users to manage and troubleshoot applications running in the cluster, as well as the cluster itself.
- Container Resource Monitoring: Providing a reliable application runtime, and being able to scale it up or down in response to workloads, means being able to continuously and effectively monitor workload performance. Container Resource Monitoring provides this capability by recording metrics about containers in a central database, and provides a UI for browsing that data. The cAdvisor is a component on a slave node that provides a limited metric monitoring capability. There are full metrics pipelines as well, such as Prometheus, which can meet most monitoring needs.
- Cluster-level logging: Logs should have a separate storage and lifecycle independent of nodes, pods, or containers. Otherwise, node or pod failures can cause loss of event data. The ability to do this is called cluster-level logging, and such mechanisms are responsible for saving container logs to a central log store with search/browsing interface. Kubernetes provides no native storage for log data, but one can integrate many existing logging solutions into the Kubernetes cluster.
Storage
Containers emerged as a way to make software portable. The container contains all the packages you need to run a service. The provided filesystem makes containers extremely portable and easy to use in development. A container can be moved from development to test or production with no or relatively few configuration changes.
Historically Kubernetes was suitable only for stateless services. However, many applications have a database, which requires persistence, which leads to the creation of persistent storage for Kubernetes. Implementing persistent storage for containers is one of the top challenges of Kubernetes administrators, DevOps and cloud engineers. Containers may be ephemeral, but more and more of their data is not, so one needs to ensure the data's survival in case of container termination or hardware failure.
When deploying containers with Kubernetes or containerized applications, companies often realize that they need persistent storage. They need to provide fast and reliable storage for databases, root images and other data used by the containers.
In addition to the landscape, the Cloud Native Computing Foundation (CNCF), has published other information about Kubernetes Persistent Storage including a blog helping to define the container attached storage pattern. This pattern can be thought of as one that uses Kubernetes itself as a component of the storage system or service.[48]
More information about the relative popularity of these and other approaches can be found on the CNCF's landscape survey as well, which showed that OpenEBS from MayaData and Rook - a storage orchestration project - were the two projects most likely to be in evaluation as of the Fall of 2019.[49]
Container Attached Storage is a type of data storage that emerged as Kubernetes gained prominence. The Container Attached Storage approach or pattern relies on Kubernetes itself for certain capabilities while delivering primarily block, file, object and interfaces to workloads running on Kubernetes.[50]
Common attributes of Container Attached Storage include the use of extensions to Kubernetes, such as custom resource definitions, and the use of Kubernetes itself for functions that otherwise would be separately developed and deployed for storage or data management. Examples of functionality delivered by custom resource definitions or by Kubernetes itself include retry logic, delivered by Kubernetes itself, and the creation and maintenance of an inventory of available storage media and volumes, typically delivered via a custom resource definition.[51][52]
API
The design principles underlying Kubernetes allow one to programmatically create, configure, and manage Kubernetes clusters. This function is exposed via an API called the Cluster API. A key concept embodied in the API is the notion that the Kubernetes cluster is itself a resource / object that can be managed just like any other Kubernetes resources. Similarly, machines that make up the cluster are also treated as a Kubernetes resource. The API has two pieces - the core API, and a provider implementation. The provider implementation consists of cloud-provider specific functions that let Kubernetes provide the cluster API in a fashion that is well-integrated with the cloud-provider's services and resources.
Uses
Kubernetes is commonly used as a way to host a microservice-based implementation, because it and its associated ecosystem of tools provide all the capabilities needed to address key concerns of any microservice architecture.
See also
References
- "First GitHub commit for Kubernetes". github.com. 2014-06-07. Archived from the original on 2017-03-01.
- "GitHub Releases page". github.com. Retrieved 2020-10-31.
- "Kubernetes 1.20: The Raddest Release". Kubernetes. Retrieved 2020-12-14.
- "Kubernetes GitHub Repository". GitHub. January 22, 2021.
- "kubernetes/kubernetes". GitHub. Archived from the original on 2017-04-21. Retrieved 2017-03-28.
- "What is Kubernetes?". Kubernetes. Retrieved 2017-03-31.
- "Kubernetes v1.12: Introducing RuntimeClass". kubernetes.io.
- "Don't Panic: Kubernetes and Docker". Kubernetes Blog. Retrieved 2020-12-22.
- "Google Made Its Secret Blueprint Public to Boost Its Cloud". Archived from the original on 2016-07-01. Retrieved 2016-06-27.
- "Google Open Sources Its Secret Weapon in Cloud Computing". Wired. Archived from the original on 10 September 2015. Retrieved 24 September 2015.
- Abhishek Verma; Luis Pedrosa; Madhukar R. Korupolu; David Oppenheimer; Eric Tune; John Wilkes (April 21–24, 2015). "Large-scale cluster management at Google with Borg". Proceedings of the European Conference on Computer Systems (EuroSys). Archived from the original on 2017-07-27.
- "Borg, Omega, and Kubernetes - ACM Queue". queue.acm.org. Archived from the original on 2016-07-09. Retrieved 2016-06-27.
- "Early Stage Startup Heptio Aims to Make Kubernetes Friendly". Retrieved 2016-12-06.
- "As Kubernetes Hits 1.0, Google Donates Technology To Newly Formed Cloud Native Computing Foundation". TechCrunch. Archived from the original on 23 September 2015. Retrieved 24 September 2015.
- "Cloud Native Computing Foundation". Archived from the original on 2017-07-03.
- https://github.com/helm/helm/releases/tag/v1.0
- https://www.wikieduonline.com/wiki/Helm_(package_manager)
- https://helm.sh/
- Conway, Sarah. "Kubernetes Is First CNCF Project To Graduate" (html). Cloud Native Computing Foundation. Archived from the original on 29 October 2018. Retrieved 3 December 2018.
Compared to the 1.5 million projects on GitHub, Kubernetes is No. 9 for commits and No. 2 for authors/issues, second only to Linux.
- "Kubernetes version and version skew support policy". Kubernetes. Retrieved 2020-03-03.
- "Kubernetes 1.19 Release Announcement > Increase Kubernetes support window to one year". Kubernetes. Retrieved 2020-08-28.
- "Kubernetes Patch Releases". 5 January 2021.
- "Kubernetes 1.19 Release Announcement". Kubernetes. Retrieved 2020-08-28.
- Sharma, Priyanka (13 April 2017). "Autoscaling based on CPU/Memory in Kubernetes—Part II". Powerupcloud Tech Blog. Medium. Retrieved 27 December 2018.
- "Configure Kubernetes Autoscaling With Custom Metrics". Bitnami. BitRock. 15 November 2018. Retrieved 27 December 2018.
- "An Introduction to Kubernetes". DigitalOcean. Archived from the original on 1 October 2015. Retrieved 24 September 2015.
- "Kubernetes Infrastructure". OpenShift Community Documentation. OpenShift. Archived from the original on 6 July 2015. Retrieved 24 September 2015.
- Container Linux by CoreOS: Cluster infrastructure
- Marhubi, Kamal (2015-09-26). "Kubernetes from the ground up: API server". kamalmarhubi.com. Archived from the original on 2015-10-29. Retrieved 2015-11-02.
- Ellingwood, Justin (2 May 2018). "An Introduction to Kubernetes". DigitalOcean. Archived from the original on 5 July 2018. Retrieved 20 July 2018.
One of the most important primary services is an API server. This is the main management point of the entire cluster as it allows a user to configure Kubernetes' workloads and organizational units. It is also responsible for making sure that the etcd store and the service details of deployed containers are in agreement. It acts as the bridge between various components to maintain cluster health and disseminate information and commands.
- "The Three Pillars of Kubernetes Container Orchestration - Rancher Labs". rancher.com. 18 May 2017. Archived from the original on 24 June 2017. Retrieved 22 May 2017.
- "Overview of a Replication Controller". Documentation. CoreOS. Archived from the original on 2015-09-22. Retrieved 2015-11-02.
- Sanders, Jake (2015-10-02). "Kubernetes: Exciting Experimental Features". Livewyer. Archived from the original on 2015-10-20. Retrieved 2015-11-02.
- "Intro: Docker and Kubernetes training - Day 2". Red Hat. 2015-10-20. Archived from the original on 2015-10-29. Retrieved 2015-11-02.
- Marhubi, Kamal (2015-08-27). "What [..] is a Kubelet?". kamalmarhubi.com. Archived from the original on 2015-11-13. Retrieved 2015-11-02.
- "rktnetes brings rkt container engine to Kubernetes". kubernetes.io.
- "Pods". kubernetes.io.
- Langemak, Jon (2015-02-11). "Kubernetes 101 – Networking". Das Blinken Lichten. Archived from the original on 2015-10-25. Retrieved 2015-11-02.
- Strachan, James (2015-05-21). "Kubernetes for Developers". Medium (publishing platform). Archived from the original on 2015-09-07. Retrieved 2015-11-02.
- "ReplicaSet". kubernetes.io. Retrieved 2020-03-03.
- "Deployments, ReplicaSets, and pods".
- "Service". kubernetes.io.
- Langemak, Jon (2015-02-15). "Kubernetes 101 – External Access Into The Cluster". Das Blinken Lichten. Archived from the original on 2015-10-26. Retrieved 2015-11-02.
- "Volumes". kubernetes.io.
- "Namespaces". kubernetes.io.
- "StatefulSets". kubernetes.io.
- "DaemonSet". kubernetes.io.
- https://www.cncf.io/blog/2018/04/19/container-attached-storage-a-primer/
- https://www.cncf.io/wp-content/uploads/2020/03/CNCF_Survey_Report.pdf
- "Container Attached Storage: A primer". Cloud Native Computing Foundation. 2018-04-19. Retrieved 2020-10-09.
- "Container Attached Storage | SNIA". www.snia.org. Retrieved 2020-10-09.
- "Cloud Native Application Checklist: Cloud Native Storage". www.replex.io. Retrieved 2020-10-09.
