Linguistic Linked Open Data
In natural language processing, linguistics, and neighboring fields, Linguistic Linked Open Data (LLOD) describes a method and an interdisciplinary community concerned with creating, sharing, and (re-)using language resources in accordance with Linked Data principles. The Linguistic Linked Open Data Cloud was conceived and is being maintained by the Open Linguistics Working Group (OWLG) of the Open Knowledge Foundation, but has been a point of focal activity for several W3C community groups, research projects, and infrastructure efforts since then.
Definition and Development
Linguistic Linked Open Data describes the publication of data for linguistics and natural language processing using the following principles:[1]
- Data should be openly licensed using licenses such as the Creative Commons licenses.
- The elements in a dataset should be uniquely identified by means of a URI.
- The URI should resolve, so users can access more information using web browsers.
- Resolving an LLOD resource should return results using web standards such as the Resource Description Framework (RDF).
- Links to other resources should be included to help users discover new resources and provide semantics.
The primary benefits of LLOD have been identified as:[2]
- Representation: Linked graphs are a more flexible representation format for linguistic data.
- Interoperability: Common RDF models can easily be integrated.
- Federation: Data from multiple sources can trivially be combined.
- Ecosystem: Tools for RDF and linked data are widely available under open source licenses.
- Expressivity: Existing vocabularies help express linguistic resources.
- Semantics: Common links express what you mean.
- Dynamicity: Web data can be continuously improved.
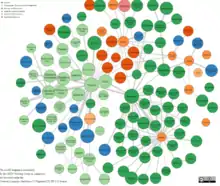
The home of the LLOD cloud diagram is under linguistic-lod.org[3]
LLOD vocabularies
Aside from gathering metadata and generating the LLOD cloud diagram, the LLOD community is driving the development of community standards with respect to vocabularies, metadata and best practice recommendations.
According to the state-of-the-art overview by Cimiano et al. (2020),[4] these include:
- for modelling lexical resources
- OntoLex-Lemon, community standard for lexical resources (machine-readable dictionaries, multilingual terminologies, ontology lexicalization)[5]
- for modelling linguistic annotations (in corpora or NLP)
- Web Annotation, a W3C standard for the annotation of web resources (textual or otherwise)[6]
- NLP Interchange Format (NIF), a community standard for the grammatical annotation of text[7]
- CoNLL-RDF, a NIF-based vocabulary for the RDF representation of corpora in conventional TSV ("CoNLL") formats[8]
- POWLA, a vocabulary for generic linguistic data structures that can be used to complement NIF, CoNLL-RDF or Web Annotation[9]
- for linguistic data categories
- Ontologies of Linguistic Annotation (OLiA) for linguistic annotation[10]
- lexinfo for grammatical and other features in lexical resources[11]
- for language identification
- as language-tagged strings using IETF BCP 47 language tags
- with ISO 639-3 URIs provided by lexvo.org[12]
- with Glottolog URIs for language varieties not covered by ISO 639
- for metadata
- Dublin Core, a community standard of terms that can be used to describe web resources
- Data Catalog Vocabulary (DCAT), a W3C standard for data catalogs published on the web[13]
- METASHARE-OWL, vocabulary for language resource metadata[14]
As of mid-2020, most of these community standards are actively worked on. Particularly problematic is the existence of multiple incompatible standards for linguistic annotations, and in early 2020, the W3C Community Group Linked Data for Language Technology has begun to work towards a consolidation of these (and other) vocabularies for linguistic annotations on the web.[15]
Community
The LLOD cloud diagram has been developed and is maintained by the Open Linguistics Working Group (OWLG) of the Open Knowledge Foundation (since 2014 Open Knowledge), an open and interdisciplinary of experts in language resources.
The OWLG organizes community events and coordinates LLOD developments and facilitates interdisciplinary communication between and among LLOD contributors and users.
Several W3C Business and Community Groups focus on specialized aspects of LLOD:
- The W3C Ontology-Lexica Community Group (OntoLex) develops and maintains specifications for machine-readable dictionaries in the LLOD cloud.
- The W3C Best Practices for Multilingual Linked Open Data Community Group gathers information on best practices for producing multilingual linked open data.[16]
- The W3C Linked Data for Language Technology Community Group assembles user cases and requirements for language technology applications that use Linked Data.[17]
LLOD development is driven forward by and documented in a series of international workshops, datathons, and associated publications. Among others, these include
- Linked Data in Linguistics (LDL), annual scientific workshop, started 2012
- Multilingual Linked Open Data for Enterprises (MLODE), bi-annual community meeting (2012 and 2014)
- Summer Datathon on Linguistic Linked Open Data (SD-LLOD), bi-annual datathon, since 2015
Applications of LLOD
Linguistic Linked Open Data is applied to address a number of scientific research problems:
- In all areas of empirical linguistics, computational philology, and natural language processing, linguistic annotation and linguistic markup represent central elements of analysis. However, progress in this field is being hampered by interoperability challenges, most notably differences in vocabularies and annotation schemes used for different resources and tools. Using Linked Data to connect language resources and ontologies/terminology repositories facilitate re-using shared vocabularies and interpreting them against a common basis.
- In corpus linguistics and computational philology, overlapping markup represents a notorious problem to conventional XML formats. Hence, graph-based data models have been suggested since the late 1990s.[18] These are traditionally represented by means of multiple, interlinked XML files (standoff XML),[19] which are poorly supported by off-the-shelf XML technology.[20] Modeling such complex annotations as Linked Data represents a formalism semantically equivalent to standoff XML,[21] but eliminates the need for special-purpose technology, and, instead, relies on the existing RDF ecosystem.
- Multilingual issues, including the linking of lexical resources such as WordNet as performed in the Interlingual Index of the Global WordNet Association and interconnecting heterogeneous resources such as WordNet and Wikipedia, as was done in BabelNet.
- Providing forums for standardization of linguistic resource information
Linguistic Linked Open Data is closely related with the development of
- best practices for linking lexical data on the web (for data published in accordance with OntoLex conventions)
- best practices for creating annotations on the web (e.g., using the Web Annotation standard)
- best practices for modelling and sharing textual resources with overlapping markup
Selected research projects
Uses and development of LLOD have been subject to several large-scale research projects, including
- LOD2. Creating Knowledge out of Interlinked Data (11 EU countries + Korea, 2010–2014)[22]
- MONNET. Multilingual Ontologies for Networked Knowledge (5 EU countries, 2010–2013)[23]
- LIDER. Linked Data as an enabler of cross-media and multilingual content analytics for enterprises across Europe (5 EU countries, 2013–2015)[24]
- QTLeap. Quality Translation by Deep Language Engineering Approaches (6 EU countries, 2013–2016)[25]
- LiODi. Linked Open Dictionaries (BMBF eHumanities Early Career Research Group, Goethe University Frankfurt, Germany, 2015-2020)[26]
- FREME. Open Framework of E-Services for Multilingual and Semantic Enrichment of Digital Content (6 EU countries, 2015-2017)[27]
- POSTDATA. Poetry Standardization and Linked Open Data (ERC Starting Grant, UNED, Spain, 2016-2021)[28]
- Linking Latin (ERC Consolidator Grant, Universita Cattolica del Sacro Cuore, Italy, 2018-2023)[29]
- Pret-a-LLOD (5 EU countries, 2019-2021)[30]
- NexusLinguarum. European network for Web-centred linguistic data science (COST Action, 35 COST countries, 2 near neighboring countries, one international partner country, 2019-2023) [31]
Selected resources
As of October 2018, the 10 most frequently linked resources in the LLOD diagram are (in order of the number of linked datasets):
- The Ontologies of Linguistic Annotation (OLiA, linked with 74 datasets) provide reference terminology for linguistic annotations and grammatical metadata;
- WordNet (linked with 51 datasets), a lexical database for English and pivot for developing similar databases for other languages, with several editions (Princeton edition linked with 36 datasets; W3C edition linked with 8 datasets; VU edition linked with 7 datasets);
- DBpedia (linked with 50 datasets) multilingual knowledge basis of general world knowledge, based on Wikipedia;
- lexinfo.net (linked with 36 datasets) provides reference terminology for lexical resources;
- BabelNet (linked with 33 datasets) multilingual lexicalized semantic network, based on the aggregation of various other resources, most notably WordNet and Wikipedia;
- lexvo.org (linked with 26 datasets) provides language identifiers and other language-related data. Most importantly, lexvo provides an RDF representation of ISO 639-3 3-letter codes for language identifiers and information about these languages;
- The ISO 12620 Data Category Registry (ISOcat; RDF edition, linked with 10 datasets) provides a semistructured repository for various language-related terminology. ISOcat is hosted by The Language Archive, respectively, the DOBES project, at the Max Planck Institute for Psycholinguistics, but currently in transition to CLARIN;
- UBY (RDF edition lemon-Uby, linked with 9 datasets), a lexical network for English, aggregated from various lexical resources;
- Glottolog (linked with 7 datasets) provides fine-grained language identifiers for low-resource languages, in particular, many not covered by lexvo.org;
- Wiktionary-DBpedia links (wiktionary.dbpedia.org, linked with 7 datasets), Wiktionary-based lexicalizations for DBpedia concepts.
Aspects
There are a number of recurring discussions regarding the different aspects of the term, its applicability and for a particular type of resources.[32]
Linguistic Data: Scope and Classification
Aside from resources used in and created for linguistic research, the LLOD cloud diagram also includes ontologies, terminologies and general knowledge bases whose development was not originally driven by interest in language sciences or language technology, e.g., the DBpedia. As a criterion for inclusion into the LLOD diagram, the OWLG requires "linguistic relevance": "[A] dataset is linguistically relevant if it provides or describes language data that can be used for the purpose of linguistic research or natural language processing."[33] This does include linguistic resources in a strict sense ("condition 1": an annotated or otherwise structured resource created for application in language sciences or language technology, as demonstrated, for example, by a scientific publication at a linguistics-related journal or conference), but also resources "that can be used for annotating, enriching, retrieving or classifying language resources ... [if their relevance] can be verified by the existence of links between a resource (whose linguistic relevance is to be confirmed) and resources fulfilling condition (1)" ("condition 2").[34]
A related issue is the classification of linguistically relevant datasets (or language resources in general). The OWLG developed the following classification for the LLOD cloud diagram:[35]
- corpora: linguistically analyzed collection of language data
- lexicons: lexical-conceptual data
- lexical resources: lexicons and dictionaries
- term bases: terminologies, thesauri and knowledge bases
- metadata
- linguistic resource metadata (metadata about language resources, incl. digital language resources and printed books)
- linguistic data categories (metadata about linguistic terminology, incl. linguistic categories, language identifiers)
- typological databases (metadata about individual languages, esp., linguistic features of those languages)
- other (placeholder for resources that are not (yet) classified)[1]
Note that in this classification, term bases are at the fringes of linguistic relevance, as these are normally created for purposes other than language technology or linguistic research.
Open Data: Availability
LLOD is defined in relation to Linked Open Data, and LLOD resources (data) should thus conform to licenses in accordance with the Open Definition.[36] For generating the LLOD cloud diagram (and the LOD diagram), this does, however, not seem to be enforced yet, so that the technical criterion is availability over the web and a metadata entry. In the OWLG, it has been repeatedly discussed whether non-commercial (academic) resources could be included with a general consensus of admitting them for the moment (2015) but subsequently enforcing stricter requirements along with the growth of the LLOD cloud. As of January 2018, it was not agreed upon yet when this move was about to happen.[37] As of January 2020, machine-readable license metadata was available for 86 LLOD resources, of these, 82 adopted open licenses, 4 adopted non-commercial licenses.[38]
In a broader sense, the term LLOD technology (infrastructures, tools, vocabularies) can also used to refer to the technology independently from whether actually open resources are involved, e.g., in the name of the EU project Pret-a-LLOD that features several commercial business cases.[39] This is justified for applications that consume (rather than provide) open data, but moreover, also when linked data technology and the adoptation of other LLOD conventions (esp., the use of RDF vocabularies developed in the context of LLOD) are applied in order to facilitates the seamless integration of LLOD resources (open resources).
The abbreviation "LLOD" can be used to refer to either LLOD technology (use of Linked Data and LLOD vocabularies, independent from the legal status of the data being processed) and LLOD resources (open data). For disambiguation, the terms "LLOD resources" and "LLOD technology" can be used. For emphasizing application or applicability to non-open resources, also "LLD" (Linguistic Linked Data) has been used.[40] A possible compromise is the acronym "LL(O)D" for the technology. A "Licensed Linguistic Linked Data" cloud that contains non-open resources does currently (June 2020) not exist.[41]
Linked Data: Formats
The definition of Linked Data requires the application of RDF or related standards. This includes the W3C recommendations SPARQL, Turtle, JSON-LD, RDF-XML, RDFa, etc. In language technology and the language sciences, however, other formalisms are currently more popular, and the inclusion of such data into the LLOD cloud diagram has been occasionally requested.[32] For several such languages, W3C-standardized wrapping mechanisms exist (e.g., for XML, CSV or relational databases, see Knowledge extraction#Extraction from structured sources to RDF), and such data can be integrated under the condition that the corresponding mapping is provided along with the source data.
Selected literature
An exhaustive description on the state of the art on LLOD is provided by
- Cimiano, Philipp; Chiarcos, Christian; McCrae, John P.; Gracia, Jorge (2020). Linguistic Linked Data: Representation, Generation and Applications. Springer International Publishing
The concept of a Linguistic Linked Open Data cloud has been originally introduced by
- Chiarcos, Christian, Hellmann, Sebastian, and Nordhoff, Sebastian (2011). Towards a Linguistic Linked Open Data cloud: The Open Linguistics Working Group. TAL (Traitement Automatique des Langues), 52(3), 245-275.
The first book on the topic is
- Christian Chiarcos, Sebastian Nordhoff, and Sebastian Hellmann (eds., 2012). Linked Data in Linguistics. Representing and Connecting Language Data and Language Metadata. Springer, Heidelberg.
According to Cimiano et al. (2020),[42] other seminal publications since then include
- Christian Chiarcos, Steven Moran, Pablo N. Mendes, Sebastian Nordhoff, and Richard Littauer. Building a Linked Open Data cloud of linguistic resources: Motivations and developments. In Iryna Gurevych and Jungi Kim (eds.), The People’s Web Meets NLP. Collaboratively Constructed Language Resources.Springer, Heidelberg, 2013.
- Christian Chiarcos, John McCrae, Philipp Cimiano, and Christiane Fellbaum. Towards open data for linguistics: Lexical Linked Data. In Alessandro Oltramari, Piek Vossen, Lu Qin, and Eduard Hovy (eds.), New Trends of Research in Ontologies and Lexical Resources. Springer, Heidelberg, 2013.
- Jorge Gracia, Elena Montiel-Ponsoda, Philipp Cimiano, Asunción Gómez-Pérez, Paul Buitelaar, and John McCrae. Challenges for the multilingual Web of Data.Journal of Web Semantics, vol. 11, pp. 63–71. Elsevier B.V., 2012.
Developments from 2015 to 2019 are summarized in the collected volume by
- Pareja-Lora, Antonio; Lust, Barbara; Blume, Maria; Chiarcos, Christian (eds., 2020). Development of Linguistic Linked Open Data Resources for Collaborative Data-Intensive Research in the Language Sciences. The MIT Press
References
- Open Linguistics Working Group. "Linguistic LOD". linguistic-lod.org. LIDER project. Retrieved 2016-05-24.
- Chiarcos, Christian; McCrae, John; Cimiano, Philipp; Fellbaum, Christiane (2013). Towards open data for linguistics: Lexical Linked Data (PDF). Heidelberg: In: Alessandro Oltramari, Piek Vossen, Lu Qin, and Eduard Hovy (eds.), New Trends of Research in Ontologies and Lexical Resources. Springer. Retrieved 2016-05-24.
- "Linguistic Linked Open Data. Information about the current status of the growing cloud of linguistic linked open data". Retrieved 10 December 2019.
- Cimiano, Philipp; Chiarcos, Christian; McCrae, John P.; Gracia, Jorge (2020). Linguistic Linked Data: Representation, Generation and Applications. Springer International Publishing. ISBN 978-3-030-30224-5.
- "Lexicon Model for Ontologies: Community Report, 10 May 2016". www.w3.org. Retrieved 2020-06-05.
- "Deliverables of W3C's Web Annotation Working Group". w3c.github.io. Retrieved 2020-06-05.
- Hellmann, Sebastian; Lehmann, Jens; Auer, Sören; Brümmer, Martin (2013). Alani, Harith; Kagal, Lalana; Fokoue, Achille; Groth, Paul; Biemann, Chris; Parreira, Josiane Xavier; Aroyo, Lora; Noy, Natasha; Welty, Chris (eds.). "Integrating NLP Using Linked Data". The Semantic Web – ISWC 2013. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer: 98–113. doi:10.1007/978-3-642-41338-4_7. ISBN 978-3-642-41338-4.
- Chiarcos, Christian; Fäth, Christian (2017). Gracia, Jorge; Bond, Francis; McCrae, John P.; Buitelaar, Paul; Chiarcos, Christian; Hellmann, Sebastian (eds.). "CoNLL-RDF: Linked Corpora Done in an NLP-Friendly Way". Language, Data, and Knowledge. Lecture Notes in Computer Science. Cham: Springer International Publishing: 74–88. doi:10.1007/978-3-319-59888-8_6. ISBN 978-3-319-59888-8.
- Chiarcos, Christian (2012). Simperl, Elena; Cimiano, Philipp; Polleres, Axel; Corcho, Oscar; Presutti, Valentina (eds.). "POWLA: Modeling Linguistic Corpora in OWL/DL". The Semantic Web: Research and Applications. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer: 225–239. doi:10.1007/978-3-642-30284-8_22. ISBN 978-3-642-30284-8.
- Chiarcos, Christian; Sukhareva, Maria (2015-01-01). "OLiA – Ontologies of Linguistic Annotation". Semantic Web. 6 (4): 379–386. doi:10.3233/SW-140167. ISSN 1570-0844.
- Cimiano, P.; Buitelaar, P.; McCrae, J.; Sintek, M. (2011-03-01). "LexInfo: A declarative model for the lexicon-ontology interface". Journal of Web Semantics. 9 (1): 29–51. doi:10.1016/j.websem.2010.11.001. ISSN 1570-8268.
- de Melo, Gerard (2015-01-01). "Lexvo.org: Language-related information for the Linguistic Linked Data cloud". Semantic Web. 6 (4): 393–400. doi:10.3233/SW-150171. ISSN 1570-0844.
- "Data Catalog Vocabulary (DCAT) - Version 2". www.w3.org. Retrieved 2020-06-05.
- McCrae, John P.; Labropoulou, Penny; Gracia, Jorge; Villegas, Marta; Rodríguez-Doncel, Víctor; Cimiano, Philipp (2015). Gandon, Fabien; Guéret, Christophe; Villata, Serena; Breslin, John; Faron-Zucker, Catherine; Zimmermann, Antoine (eds.). "One Ontology to Bind Them All: The META-SHARE OWL Ontology for the Interoperability of Linguistic Datasets on the Web". The Semantic Web: ESWC 2015 Satellite Events. Lecture Notes in Computer Science. Cham: Springer International Publishing: 271–282. doi:10.1007/978-3-319-25639-9_42. ISBN 978-3-319-25639-9.
- ld4lt/linguistic-annotation, ld4lt, 2020-05-19, retrieved 2020-06-05
- "Best Practices for Multilingual Linked Open Data Community Group". Retrieved 9 December 2019.
- "Linked Data for Language Technology Community Group". Retrieved 9 December 2019.
- Bird, Steven; Liberman, Mark. "Towards a formal framework for linguistic annotations" (PDF). In: Proceedings of the International Conference on Spoken Language Processing, Sydney, 1998. Retrieved 2016-05-25.
- ISO 24612:2012. "Language resource management -- Linguistic annotation framework (LAF)". ISO. Retrieved 2016-05-25.
- Eckart, Richard (2008). Choosing an XML database for linguistically annotated corpora. SDV. Sprache und Datenverarbeitung 32.1/2008: International Journal for Language Data Processing, Workshop Datenbanktechnologien für hypermediale linguistische Anwendungen (KONVENS 2008), Universitätsverlag Rhein-Ruhr, Berlin, Sep 2008. pp. 7–22.
- Chiarcos, Christian. "Interoperability of Corpora and Annotations (draft version)" (PDF). In: Christian Chiarcos, Sebastian Nordhoff, and Sebastian Hellmann (eds.) Linked Data in Linguistics. Representing and Connecting Language Data and Language Metadata, 2012. Retrieved 2016-05-25.
- "lod2.okfn.org (archived version)". Archived from the original on 7 March 2014. Retrieved 9 December 2019.
- "Multilingual Ontologies for Networked Knowledge (Monnet)". European Commission, CORDIS EU research results. Retrieved 10 December 2019.
- "LIDER: Linked Data as an enabler of cross-media and multilingual content analytics for enterprises across Europe". European Commission, CORDIS EU research results. Retrieved 10 December 2019.
- "Quality Translation by Deep Language Engineering Approaches". European Commission, CORDIS EU research results. Retrieved 10 December 2019.
- "Linked Open Dictionaries (LiODi)". Retrieved 10 December 2019.
- "Open Framework of E-Services for Multilingual and Semantic Enrichment of Digital Content". Retrieved 10 December 2019.
- "POSTDATA – Poetry Standardization and Linked Open Data". Retrieved 10 December 2019.
- "Linking Latin. Building a Knowledge Base of Linguistic Resources for Latin". Retrieved 10 December 2019.
- "Pret-a-LLOD project home page". Retrieved 10 December 2019. "Pret-a-LLOD". European Commission, CORDIS EU research results. Retrieved 10 December 2019.
- "CA18209 - European network for Web-centred linguistic data science". cost. European Cooperation in Science and Technology. Retrieved 10 December 2019.
- For a history of these discussions, see the Open Linguistics mailing list archives, available only as a backup under https://github.com/open-linguistics/linguistics.okfn.org/tree/master/backup
- Cimiano, Philipp; Chiarcos, Christian; McCrae, John P.; Gracia, Jorge (2020). Linguistic Linked Data: Representation, Generation and Applications. Springer International Publishing. p. 33. ISBN 978-3-030-30224-5.
- Cimiano, Philipp; Chiarcos, Christian; McCrae, John P.; Gracia, Jorge (2020). Linguistic Linked Data: Representation, Generation and Applications. Springer International Publishing. pp. 33–34. ISBN 978-3-030-30224-5.
- Cimiano, Philipp; Chiarcos, Christian; McCrae, John P.; Gracia, Jorge (2020). Linguistic Linked Data: Representation, Generation and Applications. Springer International Publishing. pp. 36f. ISBN 978-3-030-30224-5.
- Chiarcos, Christian and Pareja-Lora, Antonio (2020), Open Data—Linked Data—Linked Open Data—Linguistic Linked Open Data (LLOD): A General Introduction. In: Pareja-Lora, Antonio; Lust, Barbara; Blume, Maria; Chiarcos, Christian (eds.). Development of Linguistic Linked Open Data Resources for Collaborative Data-Intensive Research in the Language Sciences. The MIT Press, p.1-18.
- "linguistics.okfn.org/003004.html at master · open-linguistics/linguistics.okfn.org · GitHub". Retrieved 2020-06-05.
- Cimiano, Philipp; Chiarcos, Christian; McCrae, John P.; Gracia, Jorge (2020). Linguistic Linked Data: Representation, Generation and Applications. Springer International Publishing. p. 37. ISBN 978-3-030-30224-5.
- "Prêt-à-LLOD – Prêt-à-LLOD project website". Retrieved 2020-06-05.
- See the title of the book by Cimiano, Chiarcos, Gracia, McCrae (2020). However, the acronym LLD (June 2020: 7 unambiguous Google scholar matches) seems to be rarely used in comparison to LLOD (June 2020: 309 unambiguous Google scholar matches).
- Cimiano, Philipp; Chiarcos, Christian; McCrae, John P.; Gracia, Jorge (2020). Linguistic Linked Data: Representation, Generation and Applications. Springer International Publishing. p. 37. ISBN 978-3-030-30224-5.
- Cimiano, Philipp; Chiarcos, Christian; McCrae, John P.; Gracia, Jorge (2020). Linguistic Linked Data: Representation, Generation and Applications. Springer International Publishing. pp. vi. ISBN 978-3-030-30224-5.
