Nanopore sequencing
Nanopore sequencing is a third generation[1] approach used in the sequencing of biopolymers- specifically, polynucleotides in the form of DNA or RNA.
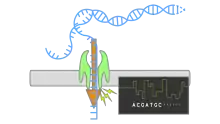
Using nanopore sequencing, a single molecule of DNA or RNA can be sequenced without the need for PCR amplification or chemical labeling of the sample. At least one of these aforementioned steps is necessary in the procedure of any previously developed sequencing approach. Nanopore sequencing has the potential to offer relatively low-cost genotyping, high mobility for testing, and rapid processing of samples with the ability to display results in real-time. Publications on the method outline its use in rapid identification of viral pathogens,[2] monitoring ebola,[3] environmental monitoring,[4] food safety monitoring, human genome sequencing,[5] plant genome sequencing,[6] monitoring of antibiotic resistance,[7] haplotyping[8] and other applications.
Principles for detection
The biological or solid-state membrane, where the nanopore is found, is surrounded by electrolyte solution.[9] The membrane splits the solution into two chambers.[10] A bias voltage is applied across the membrane inducing an electric field that drives charged particles, in this case the ions, into motion. This effect is known as electrophoresis. For high enough concentrations, the electrolyte solution is well distributed and all the voltage drop concentrates near and inside the nanopore. This means charged particles in the solution only feel a force from the electric field when they are near the pore region.[11] This region is often referred as the capture region. Inside the capture region, ions have a directed motion that can be recorded as a steady ionic current by placing electrodes near the membrane. Imagine now a nano-sized polymer such as DNA or protein placed in one of the chambers. This molecule also has a net charge that feels a force from the electric field when it is found in the capture region.[11] The molecule approaches this capture region aided by brownian motion and any attraction it might have to the surface of the membrane.[11] Once inside the nanopore, the molecule translocates through via a combination of electro-phoretic, electro-osmotic and sometimes thermo-phoretic forces.[9] Inside the pore the molecule occupies a volume that partially restricts the flow of ions, observed as an ionic current drop. Based on various factors such as geometry, size and chemical composition, the change in magnitude of the ionic current and the duration of the translocation will vary. Different molecules then can then be sensed and potentially identified based on this modulation in ionic current.[12]
Base identification
The magnitude of the electric current density across a nanopore surface depends on the nanopore's dimensions and the composition of DNA or RNA that is occupying the nanopore. Sequencing was made possible because, passing through the channel of the nanopore, the samples cause characteristic changes in the density of the electric current flowing through the nanopore. The total charge flowing through a nanopore channel is equal to the surface integral of electric current density flux across the nanopore unit normal surfaces between times t1 and t2.
Types
Biological
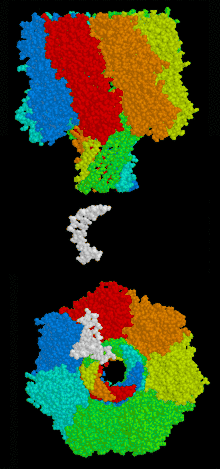
Biological nanopore sequencing relies on the use of transmembrane proteins, called porins, that are embedded in lipid membranes so as to create size dependent porous surfaces- with nanometer scale "holes" distributed across the membranes. Sufficiently low translocation velocity can be attained through the incorporation of various proteins that facilitate the movement of DNA or RNA through the pores of the lipid membranes.[13]
Alpha hemolysin
Alpha hemolysin (αHL), a nanopore from bacteria that causes lysis of red blood cells, has been studied for over 15 years.[14] To this point, studies have shown that all four bases can be identified using ionic current measured across the αHL pore.[15][16] The structure of αHL is advantageous to identify specific bases moving through the pore. The αHL pore is ~10 nm long, with two distinct 5 nm sections. The upper section consists of a larger, vestibule-like structure and the lower section consists of three possible recognition sites (R1, R2, R3), and is able to discriminate between each base.[15][16]
Sequencing using αHL has been developed through basic study and structural mutations, moving towards the sequencing of very long reads. Protein mutation of αHL has improved the detection abilities of the pore.[17] The next proposed step is to bind an exonuclease onto the αHL pore. The enzyme would periodically cleave single bases, enabling the pore to identify successive bases. Coupling an exonuclease to the biological pore would slow the translocation of the DNA through the pore, and increase the accuracy of data acquisition.
Notably, theorists have shown that sequencing via exonuclease enzymes as described here is not feasible.[18] This is mainly due to diffusion related effects imposing a limit on the capture probability of each nucleotide as it is cleaved. This results in a significant probability that a nucleotide is either not captured before it diffuses into the bulk or captured out of order, and therefore is not properly sequenced by the nanopore, leading to insertion and deletion errors. Therefore, major changes are needed to this method before it can be considered a viable strategy.
A recent study has pointed to the ability of αHL to detect nucleotides at two separate sites in the lower half of the pore.[19] The R1 and R2 sites enable each base to be monitored twice as it moves through the pore, creating 16 different measurable ionic current values instead of 4. This method improves upon the single read through the nanopore by doubling the sites that the sequence is read per nanopore.
MspA
Mycobacterium smegmatis porin A (MspA) is the second biological nanopore currently being investigated for DNA sequencing. The MspA pore has been identified as a potential improvement over αHL due to a more favorable structure.[20] The pore is described as a goblet with a thick rim and a diameter of 1.2 nm at the bottom of the pore.[21] A natural MspA, while favorable for DNA sequencing because of shape and diameter, has a negative core that prohibited single stranded DNA(ssDNA) translocation. The natural nanopore was modified to improve translocation by replacing three negatively charged aspartic acids with neutral asparagines.[22]
The electric current detection of nucleotides across the membrane has been shown to be tenfold more specific than αHL for identifying bases.[20] Utilizing this improved specificity, a group at the University of Washington has proposed using double stranded DNA (dsDNA) between each single stranded molecule to hold the base in the reading section of the pore.[20][22] The dsDNA would halt the base in the correct section of the pore and enable identification of the nucleotide. A recent grant has been awarded to a collaboration from UC Santa Cruz, the University of Washington, and Northeastern University to improve the base recognition of MspA using phi29 polymerase in conjunction with the pore.[23]
Solid state
Solid state nanopore sequencing approaches, unlike biological nanopore sequencing, do not incorporate proteins into their systems. Instead, solid state nanopore technology uses various metal or metal alloy substrates with nanometer sized pores that allow DNA or RNA to pass through. These substrates most often serve integral roles in the sequence recognition of nucleic acids as they translocate through the channels along the substrates.[24]
Tunneling current
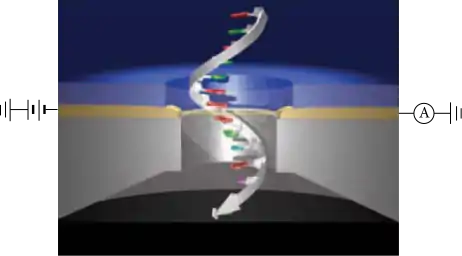
Measurement of electron tunneling through bases as ssDNA translocates through the nanopore is an improved solid state nanopore sequencing method. Most research has focused on proving bases could be determined using electron tunneling. These studies were conducted using a scanning probe microscope as the sensing electrode, and have proved that bases can be identified by specific tunneling currents.[25] After the proof of principle research, a functional system must be created to couple the solid state pore and sensing devices.
Researchers at the Harvard Nanopore group have engineered solid state pores with single walled carbon nanotubes across the diameter of the pore.[26] Arrays of pores are created and chemical vapor deposition is used to create nanotubes that grow across the array. Once a nanotube has grown across a pore, the diameter of the pore is adjusted to the desired size. Successful creation of a nanotube coupled with a pore is an important step towards identifying bases as the ssDNA translocates through the solid state pore.
Another method is the use of nanoelectrodes on either side of a pore.[27][28] The electrodes are specifically created to enable a solid state nanopore's formation between the two electrodes. This technology could be used to not only sense the bases but to help control base translocation speed and orientation.
Fluorescence
An effective technique to determine a DNA sequence has been developed using solid state nanopores and fluorescence.[29] This fluorescence sequencing method converts each base into a characteristic representation of multiple nucleotides which bind to a fluorescent probe strand-forming dsDNA. With the two color system proposed, each base is identified by two separate fluorescences, and will therefore be converted into two specific sequences. Probes consist of a fluorophore and quencher at the start and end of each sequence, respectively. Each fluorophore will be extinguished by the quencher at the end of the preceding sequence. When the dsDNA is translocating through a solid state nanopore, the probe strand will be stripped off, and the upstream fluorophore will fluoresce.[29][30]
This sequencing method has a capacity of 50-250 bases per second per pore, and a four color fluorophore system (each base could be converted to one sequence instead of two), will sequence over 500 bases per second.[29] Advantages of this method are based on the clear sequencing readout—using a camera instead of noisy current methods. However, the method does require sample preparation to convert each base into an expanded binary code before sequencing. Instead of one base being identified as it translocates through the pore, ~12 bases are required to find the sequence of one base.[29]
Comparison between types
| Biological | Solid State | |
| Low Translocation Velocity | ✓ | |
| Dimensional Reproducibility | ✓ | |
| Stress Tolerance | ✓ | |
| Longevity | ✓ | |
| Ease of Fabrication | ✓ |
Major constraints
- Low Translocation Velocity: The speed at which a sample passes through a unit's pore slow enough to be measured
- Dimensional Reproducibility: The likelihood of a unit's pore to be made the proper size
- Stress Tolerance: The sensitivity of a unit to internal environmental conditions
- Longevity: The length of time that a unit is expected to remain functioning
- Ease of Fabrication: The ability to produce a unit- usually in regards to mass-production
Biological: advantages and disadvantages
Biological nanopore sequencing systems have several fundamental characteristics that make them advantageous as compared with solid state systems- with each advantageous characteristic of this design approach stemming from the incorporation of proteins into their technology. Uniform pore structure, the precise control of sample translocation through pore channels, and even the detection of individual nucleotides in samples can be facilitated by unique proteins from a variety of organism types.
The use of proteins in biological nanopore sequencing systems, despite the various benefits, also brings with it some negative characteristics. The sensitivity of the proteins in these systems to local environmental stress has a large impact on the longevity of the units, overall. One example is that a motor protein may only unzip samples with sufficient speed at a certain pH range while not operating fast enough outside of the range- this constraint impacts the functionality of the whole sequencing unit. Another example is that a transmembrane porin may only operate reliably for a certain number of runs before it breaks down. Both of these examples would have to be controlled for in the design of any viable biological nanopore system- something that may be difficult to achieve while keeping the costs of such a technology as low and as competitive, to other systems, as possible.[13]
Challenges
One challenge for the 'strand sequencing' method was in refining the method to improve its resolution to be able to detect single bases. In the early papers methods, a nucleotide needed to be repeated in a sequence about 100 times successively in order to produce a measurable characteristic change. This low resolution is because the DNA strand moves rapidly at the rate of 1 to 5μs per base through the nanopore. This makes recording difficult and prone to background noise, failing in obtaining single-nucleotide resolution. The problem is being tackled by either improving the recording technology or by controlling the speed of DNA strand by various protein engineering strategies and Oxford Nanopore employs a 'kmer approach', analyzing more than one base at any one time so that stretches of DNA are subject to repeat interrogation as the strand moves through the nanopore one base at a time.[31] Various techniques including algorithmic have been used to improve the performance of the MinION technology since it was first made available to users.[32] More recently effects of single bases due to secondary structure or released mononucleotides have been shown.[33][34]
Professor Hagan Bayley proposed in 2010 that creating two recognition sites within an alpha-hemolysin pore may confer advantages in base recognition.[35]
One challenge for the 'exonuclease approach',[36] where a processive enzyme feeds individual bases, in the correct order, into the nanopore, is to integrate the exonuclease and the nanopore detection systems. In particular,[37] the problem is that when an exonuclease hydrolyzes the phosphodiester bonds between nucleotides in DNA, the subsequently released nucleotide is not necessarily guaranteed to directly move into, say, a nearby alpha-hemolysin nanopore. One idea is to attach the exonuclease to the nanopore, perhaps through biotinylation to the beta barrel hemolysin.[37] The central pore of the protein may be lined with charged residues arranged so that the positive and negative charges appear on opposite sides of the pore. However, this mechanism is primarily discriminatory and does not constitute a mechanism to guide nucleotides down some particular path.
References
- Niedringhaus TP, Milanova D, Kerby MB, Snyder MP, Barron AE (June 2011). "Landscape of next-generation sequencing technologies". Analytical Chemistry. 83 (12): 4327–41. doi:10.1021/ac2010857. PMC 3437308. PMID 21612267.
- Greninger AL, Naccache SN, Federman S, Yu G, Mbala P, Bres V, et al. (September 2015). "Rapid metagenomic identification of viral pathogens in clinical samples by real-time nanopore sequencing analysis". Genome Medicine. 7 (1): 99. bioRxiv 10.1101/020420. doi:10.1186/s13073-015-0220-9. PMC 4587849. PMID 26416663.
- Nick Loman (15 May 2015). "How a small backpack for fast genomic sequencing is helping combat Ebola". The Conversation.
- "TGAC's take on the first portable DNA sequencing 'laboratory'". EurekAlert!. 19 March 2015.
- "nanopore-wgs-consortium/NA12878". GitHub. Retrieved 2017-01-10.
- "Solanum pennellii (new cultivar) - PlabiPD". www.plabipd.de. Retrieved 2017-01-10.
- Cao MD, Ganesamoorthy D, Elliott AG, Zhang H, Cooper MA, Coin LJ (July 2016). "Streaming algorithms for identification of pathogens and antibiotic resistance potential from real-time MinION(TM) sequencing". GigaScience. 5 (1): 32. bioRxiv 10.1101/019356. doi:10.1186/s13742-016-0137-2. PMC 4960868. PMID 27457073.
- Ammar R, Paton TA, Torti D, Shlien A, Bader GD (2015). "CYP2D6 variants and haplotypes". F1000Research. 4: 17. doi:10.12688/f1000research.6037.2. PMC 4392832. PMID 25901276.
- Varongchayakul N, Song J, Meller A, Grinstaff MW (November 2018). "Single-molecule protein sensing in a nanopore: a tutorial". Chemical Society Reviews. 47 (23): 8512–8524. doi:10.1039/C8CS00106E. PMC 6309966. PMID 30328860.
- Talaga DS, Li J (July 2009). "Single-molecule protein unfolding in solid state nanopores". Journal of the American Chemical Society. 131 (26): 9287–97. doi:10.1021/ja901088b. PMC 2717167. PMID 19530678.
- Chen P, Gu J, Brandin E, Kim YR, Wang Q, Branton D (November 2004). "Probing Single DNA Molecule Transport Using Fabricated Nanopores". Nano Letters. 4 (11): 2293–2298. Bibcode:2004NanoL...4.2293C. doi:10.1021/nl048654j. PMC 4160839. PMID 25221441.
- Si W, Aksimentiev A (July 2017). "Nanopore Sensing of Protein Folding". ACS Nano. 11 (7): 7091–7100. doi:10.1021/acsnano.7b02718. PMC 5564329. PMID 28693322.
- Liu Z, Wang Y, Deng T, Chen Q (2016-05-30). "Solid-State Nanopore-Based DNA Sequencing Technology". Journal of Nanomaterials. 2016: 1–13. doi:10.1155/2016/5284786.
- Kasianowicz JJ, Brandin E, Branton D, Deamer DW (November 1996). "Characterization of individual polynucleotide molecules using a membrane channel". Proceedings of the National Academy of Sciences of the United States of America. 93 (24): 13770–3. Bibcode:1996PNAS...9313770K. doi:10.1073/pnas.93.24.13770. PMC 19421. PMID 8943010.
- Stoddart D, Heron AJ, Mikhailova E, Maglia G, Bayley H (May 2009). "Single-nucleotide discrimination in immobilized DNA oligonucleotides with a biological nanopore". Proceedings of the National Academy of Sciences of the United States of America. 106 (19): 7702–7. Bibcode:2009PNAS..106.7702S. doi:10.1073/pnas.0901054106. PMC 2683137. PMID 19380741.
- Purnell RF, Mehta KK, Schmidt JJ (September 2008). "Nucleotide identification and orientation discrimination of DNA homopolymers immobilized in a protein nanopore". Nano Letters. 8 (9): 3029–34. Bibcode:2008NanoL...8.3029P. doi:10.1021/nl802312f. PMID 18698831.
- Clarke J, Wu HC, Jayasinghe L, Patel A, Reid S, Bayley H (April 2009). "Continuous base identification for single-molecule nanopore DNA sequencing". Nature Nanotechnology. 4 (4): 265–70. Bibcode:2009NatNa...4..265C. doi:10.1038/nnano.2009.12. PMID 19350039.
- Reiner JE, Balijepalli A, Robertson JW, Drown BS, Burden DL, Kasianowicz JJ (December 2012). "The effects of diffusion on an exonuclease/nanopore-based DNA sequencing engine". The Journal of Chemical Physics. 137 (21): 214903. Bibcode:2012JChPh.137u4903R. doi:10.1063/1.4766363. PMC 4108639. PMID 23231259.
- Stoddart D, Maglia G, Mikhailova E, Heron AJ, Bayley H (2010). "Multiple base-recognition sites in a biological nanopore: two heads are better than one". Angewandte Chemie. 49 (3): 556–9. doi:10.1002/anie.200905483. PMC 3128935. PMID 20014084.
- Manrao EA, Derrington IM, Pavlenok M, Niederweis M, Gundlach JH (2011). "Nucleotide discrimination with DNA immobilized in the MspA nanopore". PLOS ONE. 6 (10): e25723. Bibcode:2011PLoSO...625723M. doi:10.1371/journal.pone.0025723. PMC 3186796. PMID 21991340.
- Faller M, Niederweis M, Schulz GE (February 2004). "The structure of a mycobacterial outer-membrane channel". Science. 303 (5661): 1189–92. Bibcode:2004Sci...303.1189F. doi:10.1126/science.1094114. PMID 14976314. S2CID 30437731.
- Butler TZ, Pavlenok M, Derrington IM, Niederweis M, Gundlach JH (December 2008). "Single-molecule DNA detection with an engineered MspA protein nanopore". Proceedings of the National Academy of Sciences of the United States of America. 105 (52): 20647–52. Bibcode:2008PNAS..10520647B. doi:10.1073/pnas.0807514106. PMC 2634888. PMID 19098105.
- "Advanced Sequencing Technology Awards 2011".
- Carson S, Wanunu M (February 2015). "Challenges in DNA motion control and sequence readout using nanopore devices". Nanotechnology. 26 (7): 074004. Bibcode:2015Nanot..26g4004C. doi:10.1088/0957-4484/26/7/074004. PMC 4710574. PMID 25642629.
- Chang S, Huang S, He J, Liang F, Zhang P, Li S, et al. (March 2010). "Electronic signatures of all four DNA nucleosides in a tunneling gap". Nano Letters. 10 (3): 1070–5. Bibcode:2010NanoL..10.1070C. doi:10.1021/nl1001185. PMC 2836180. PMID 20141183.
- Sadki ES, Garaj S, Vlassarev D, Golovchenko JA, Branton D (2011). "Embedding a carbon nanotube across the diameter of a solid state nanopore". J. Vac. Sci. Technol. 29 (5): 5. arXiv:1308.1128. Bibcode:2011JVSTB..29e3001S. doi:10.1116/1.3628602. S2CID 32097081.
- Ivanov AP, Instuli E, McGilvery CM, Baldwin G, McComb DW, Albrecht T, Edel JB (January 2011). "DNA tunneling detector embedded in a nanopore". Nano Letters. 11 (1): 279–85. Bibcode:2011NanoL..11..279I. doi:10.1021/nl103873a. PMC 3020087. PMID 21133389.
- "Drndić Laboratory – University of Pennsylvania". Archived from the original on November 29, 2011. Retrieved December 17, 2011.
- McNally B, Singer A, Yu Z, Sun Y, Weng Z, Meller A (June 2010). "Optical recognition of converted DNA nucleotides for single-molecule DNA sequencing using nanopore arrays". Nano Letters. 10 (6): 2237–44. Bibcode:2010NanoL..10.2237M. doi:10.1021/nl1012147. PMC 2883017. PMID 20459065.
- Soni GV, Singer A, Yu Z, Sun Y, McNally B, Meller A (January 2010). "Synchronous optical and electrical detection of biomolecules traversing through solid-state nanopores". The Review of Scientific Instruments. 81 (1): 014301–014301–7. Bibcode:2010RScI...81a4301S. doi:10.1063/1.3277116. PMC 2821415. PMID 20113116.
- Bayley H (December 2006). "Sequencing single molecules of DNA". Current Opinion in Chemical Biology. 10 (6): 628–37. doi:10.1016/j.cbpa.2006.10.040. PMID 17113816.
- Loman NJ, Watson M (April 2015). "Successful test launch for nanopore sequencing". Nature Methods. 12 (4): 303–4. doi:10.1038/nmeth.3327. PMID 25825834. S2CID 5604121.
- Ashkenasy N, Sánchez-Quesada J, Bayley H, Ghadiri MR (February 2005). "Recognizing a single base in an individual DNA strand: a step toward DNA sequencing in nanopores". Angewandte Chemie. 44 (9): 1401–4. doi:10.1002/anie.200462114. PMC 1828035. PMID 15666419.
- Winters-Hilt S, Vercoutere W, DeGuzman VS, Deamer D, Akeson M, Haussler D (February 2003). "Highly accurate classification of Watson-Crick basepairs on termini of single DNA molecules". Biophysical Journal. 84 (2 Pt 1): 967–76. Bibcode:2003BpJ....84..967W. doi:10.1016/S0006-3495(03)74913-3. PMC 1302674. PMID 12547778.
- Stoddart D, Maglia G, Mikhailova E, Heron AJ, Bayley H (2010). "Multiple base-recognition sites in a biological nanopore: two heads are better than one". Angewandte Chemie. 49 (3): 556–9. doi:10.1002/anie.200905483. PMC 3128935. PMID 20014084. Archived from the original on 2013-01-05.
- Astier Y, Braha O, Bayley H (February 2006). "Toward single molecule DNA sequencing: direct identification of ribonucleoside and deoxyribonucleoside 5'-monophosphates by using an engineered protein nanopore equipped with a molecular adapter". Journal of the American Chemical Society. 128 (5): 1705–10. doi:10.1021/ja057123+. PMID 16448145.
- Rusk N (2009-04-01). "Cheap Third-Generation Sequencing". Nature Methods. 6 (4): 244–245. doi:10.1038/nmeth0409-244a. S2CID 18893754.
Reviews
- Zwolak M, Di Ventra M (2008). "Colloquium: Physical approaches to DNA sequencing and detection". Reviews of Modern Physics. 80 (1): 141–165. arXiv:0708.2724. Bibcode:2008RvMP...80..141Z. doi:10.1103/revmodphys.80.141. S2CID 1928204.
- Astier Y, Braha O, Bayley H (February 2006). "Toward single molecule DNA sequencing: direct identification of ribonucleoside and deoxyribonucleoside 5'-monophosphates by using an engineered protein nanopore equipped with a molecular adapter". Journal of the American Chemical Society. 128 (5): 1705–10. doi:10.1021/ja057123+. PMID 16448145.
- Fologea D, Gershow M, Ledden B, McNabb DS, Golovchenko JA, Li J (October 2005). "Detecting single stranded DNA with a solid state nanopore". Nano Letters. 5 (10): 1905–9. Bibcode:2005NanoL...5.1905F. doi:10.1021/nl051199m. PMC 2543124. PMID 16218707.
- Deamer DW, Akeson M (April 2000). "Nanopores and nucleic acids: prospects for ultrarapid sequencing". Trends in Biotechnology. 18 (4): 147–51. doi:10.1016/S0167-7799(00)01426-8. PMID 10740260.
- Church GM (January 2006). "Genomes for all". Scientific American. 294 (1): 46–54. Bibcode:2006SciAm.294a..46C. doi:10.1038/scientificamerican0106-46. PMID 16468433.
- Xu M, Fujita D, Hanagata N (December 2009). "Perspectives and challenges of emerging single-molecule DNA sequencing technologies". Small. 5 (23): 2638–49. doi:10.1002/smll.200900976. PMID 19904762.