Newton's method in optimization
In calculus, Newton's method is an iterative method for finding the roots of a differentiable function F, which are solutions to the equation F (x) = 0. In optimization, Newton's method is applied to the derivative f ′ of a twice-differentiable function f to find the roots of the derivative (solutions to f ′(x) = 0), also known as the stationary points of f. These solutions may be minima, maxima, or saddle points.[1]
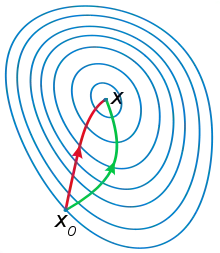
Newton's Method
The central problem of optimization is minimization of functions. Let us first consider the case of univariate functions, i.e., functions of a single real variable. We will later consider the more general and more practically useful multivariate case.
Given a twice differentiable function , we seek to solve the optimization problem


Newton's method attempts to solve this problem by constructing a sequence from an initial guess (starting point) that converges towards a minimizer of by using a sequence of second-order Taylor approximations of around the iterates. The second-order Taylor expansion of f around is






The next iterate is defined so as to minimize this quadratic approximation in , and setting . If the second derivative is positive, the quadratic approximation is a convex function of , and its minimum can be found by setting the derivative to zero. Since




the minimum is achieved for

Putting everything together, Newton's method performs the iteration

Geometric interpretation
The geometric interpretation of Newton's method is that at each iteration, it amounts to the fitting of a paraboloid to the surface of at the trial value , having the same slopes and curvature as the surface at that point, and then proceeding to the maximum or minimum of that paraboloid (in higher dimensions, this may also be a saddle point).[2] Note that if happens to be a quadratic function, then the exact extremum is found in one step.

Higher dimensions
The above iterative scheme can be generalized to dimensions by replacing the derivative with the gradient (different authors use different notation for the gradient, including ), and the reciprocal of the second derivative with the inverse of the Hessian matrix (different authors use different notation for the Hessian, including ). One thus obtains the iterative scheme




Often Newton's method is modified to include a small step size instead of :



This is often done to ensure that the Wolfe conditions are satisfied at each step of the method. For step sizes other than 1, the method is often referred to as the relaxed or damped Newton's method.
Convergence
If f is a strongly convex function with Lipschitz Hessian, then provided that is close enough to , the sequence generated by Newton's method will converge to the (necessarily unique) minimizer of quadratically fast. That is,




Computing the Newton direction
Finding the inverse of the Hessian in high dimensions to compute the Newton direction can be an expensive operation. In such cases, instead of directly inverting the Hessian, it is better to calculate the vector as the solution to the system of linear equations



which may be solved by various factorizations or approximately (but to great accuracy) using iterative methods. Many of these methods are only applicable to certain types of equations, for example the Cholesky factorization and conjugate gradient will only work if is a positive definite matrix. While this may seem like a limitation, it is often a useful indicator of something gone wrong; for example if a minimization problem is being approached and is not positive definite, then the iterations are converging to a saddle point and not a minimum.

On the other hand, if a constrained optimization is done (for example, with Lagrange multipliers), the problem may become one of saddle point finding, in which case the Hessian will be symmetric indefinite and the solution of will need to be done with a method that will work for such, such as the variant of Cholesky factorization or the conjugate residual method.

There also exist various quasi-Newton methods, where an approximation for the Hessian (or its inverse directly) is built up from changes in the gradient.
If the Hessian is close to a non-invertible matrix, the inverted Hessian can be numerically unstable and the solution may diverge. In this case, certain workarounds have been tried in the past, which have varied success with certain problems. One can, for example, modify the Hessian by adding a correction matrix so as to make positive definite. One approach is to diagonalize the Hessian and choose so that has the same eigenvectors as the Hessian, but with each negative eigenvalue replaced by .



An approach exploited in the Levenberg–Marquardt algorithm (which uses an approximate Hessian) is to add a scaled identity matrix to the Hessian, , with the scale adjusted at every iteration as needed. For large and small Hessian, the iterations will behave like gradient descent with step size . This results in slower but more reliable convergence where the Hessian doesn't provide useful information.



Stochastic Newton's Method
Many practical optimization problems, and especially those arising in data science and machine learning, involve a function which arises as an average of a very large number of simpler functions :



In supervised machine learning, represents the loss of model parameterized by vector on data training point , and thus reflects the average loss of the model on the training data set. Problems of this type include linear least squares, logistic regression and deep neural network training.



In this situation, Newton's method for minimizing takes the form

Recall that the key difficulty of standard Newton's method is the computation of Newton's step which is typically much more computationally demanding than the computation of the Hessian and the gradient . However, in the setting considered here with being the sum of a very large number of functions, the situation reverses and the computation of and by averaging the Hessians and gradients of the individual functions becomes the bottleneck.

In this big regime, the above issue can be resolved by considering the stochastic Newton (SN) method developed and analyzed by Kovalev, Mishchenko and Richtárik.[3] SN is a generalization of Newton's method which allows for a flexible choice of the set of functions for which the computation of the Hessian and gradient is necessary. This set can be chosen to be , in which case SN reduces to Newton's method. However, one can also choose , where is a random element of .





The Method. In general, SN is a parametric family of methods with parameter controlling the batch size. Given , in iteration we let be a random subset of chosen uniformly from all subsets of cardinality . That is, all subsets of cardinality are chosen with probability . The two cases described above are special cases of this for and , respectively.






The Stochastic Newton method maintains a sequence of vectors for . At the beginning, i.e., for , these vectors are initialized arbitrarily. A sensible choice is to set them to be equal. The method then performs the following steps:






Note that if and , SN reduces to Newton's method described above. However, in contrast with Newton's method, in iteration , SN needs to compute the gradients and Hessians of functions for only. In particular, the batch size can be chosen to be a constant, in which case the cost of each iteration of SN is independent of .


Convergence. For , SN has local quadratic convergence rate identical to Newton's method. For , SN has a local linear convergence rate independent of the condition number. In particular, it was shown by Kovalev, Mishchenko and Richtárik that if is strongly convex and has Lipschitz Hessian, then as long as the initial iterates are sufficiently close to the (necessarily) unique minimizer of , then



where refers to mathematical expectation with respect to the randomness inherent in the algorithm.

This is a much better rate than what is obtainable by any stochastic first order method, such as stochastic gradient descent. Indeed, the convergence rate of all first order method depends on the condition number of , which is typically defined as , where are constants such that



There are various techniques which can to some extent reduce but which can't completely eliminate the effect of the conditioning on the convergence rate of first order methods. These techniques include adaptive stepsizes, minibatching, importance sampling, Polyak momentum, Nesterov's momentum and variance reduction. In contrast to all of these techniques, SN completely removes the effect of conditioning. However, as Newton's method, SN suffers from reliance on local convergence guarantees only.

See also
Notes
- "Relative Extrema". Lamar University. Retrieved 28 August 2019.
- Edwards, A. W. F. (1992). Likelihood (Expanded ed.). Baltimore: Johns Hopkins University Press. p. 129. ISBN 0-8018-4443-6.
- Kovalev, Dmitry; Mishchenko, Konstantin; Richtárik, Peter (2019). "Stochastic Newton and cubic Newton methods with simple local linear-quadratic rates". arXiv:1912.01597.
References
- Avriel, Mordecai (2003). Nonlinear Programming: Analysis and Methods. Dover Publishing. ISBN 0-486-43227-0.
- Bonnans, J. Frédéric; Gilbert, J. Charles; Lemaréchal, Claude; Sagastizábal, Claudia A. (2006). Numerical optimization: Theoretical and practical aspects. Universitext (Second revised ed. of translation of 1997 French ed.). Berlin: Springer-Verlag. doi:10.1007/978-3-540-35447-5. ISBN 3-540-35445-X. MR 2265882.
- Fletcher, Roger (1987). Practical Methods of Optimization (2nd ed.). New York: John Wiley & Sons. ISBN 978-0-471-91547-8.
- Givens, Geof H.; Hoeting, Jennifer A. (2013). Computational Statistics. Hoboken, New Jersey: John Wiley & Sons. pp. 24–58. ISBN 978-0-470-53331-4.
- Nocedal, Jorge; Wright, Stephen J. (1999). Numerical Optimization. Springer-Verlag. ISBN 0-387-98793-2.
- Kovalev, Dmitry; Mishchenko, Konstantin; Richtárik, Peter (2019). "Stochastic Newton and cubic Newton methods with simple local linear-quadratic rates". arXiv:1912.01597 [cs.LG].
External links
- Korenblum, Daniel (Aug 29, 2015). "Newton-Raphson visualization (1D)". Bl.ocks. ffe9653768cb80dfc0da.
|  Optimization computes maxima and minima. | |||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
