Noisy data
Noisy data are data that is corrupted, or distorted, or has a low Signal-to-Noise Ratio. Improper procedures (or improperly-documented procedures) to subtract out the noise in data can lead to a false sense of accuracy or false conclusions.
Data = true signal + noise
Noisy data are data with a large amount of additional meaningless information in it called noise.[1] This includes data corruption and the term is often used as a synonym for corrupt data.[1] It also includes any data that a user system cannot understand and interpret correctly. Many systems, for example, cannot use unstructured text. Noisy data can adversely affect the results of any data analysis and skew conclusions if not handled properly. Statistical analysis is sometimes used to weed the noise out of noisy data.[1]
Sources of noise
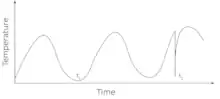
Differences in real-world measured data from the true values come about from by multiple factors affecting the measurement.[2]
Random noise is often a large component of the noise in data.[3] Random noise in a signal is measured as the Signal-to-Noise Ratio. Random noise contains almost equal amounts of a wide range of frequencies, and is also called white noise (as colors of light combine to make white). Random noise is an unavoidable problem. It affects the data collection and data preparation processes, where errors commonly occur. Noise has two main sources: errors introduced by measurement tools and random errors introduced by processing or by experts when the data is gathered.[4]
Improper Filtering can add noise, if the filtered signal is treated as if it were a directly measured signal. As an example, Convolution-type digital filters such a moving average can have side effects such as lags or truncation of peaks. Differentiating digital filters amplify random noise in the original data.
Outlier data are data that appears to not belong in the data set. It can be caused by human error such as transposing numerals, mislabeling, programming bugs, etc. If actual outliers are not removed from the data set, they corrupt the results to a small or large degree depending on circumstances. If valid data is identified as an outlier and is mistakenly removed, that also corrupts results.
Fraud: Individuals may deliberately skew data to influence the results toward a desired conclusion. Data that looks good with few outliers reflects well on the individual collecting it, and so there may be incentive to remove more data as outliers, or make the data look smoother than it is.
References
- "What is noisy data? - Definition from WhatIs.com".
- "Noisy Data in Data Mining - Soft Computing and Intelligent Information Systems". sci2s.ugr.es.
- R.Y. Wang, V.C. Storey, C.P. Firth, A Framework for Analysis of Data Quality Research, IEEE Transactions on Knowledge and Data Engineering 7 (1995) 623-640 doi: 10.1109/69.404034)
- X. Zhu, X. Wu, Class Noise vs. Attribute Noise: A Quantitative Study, Artificial Intelligence Review 22 (2004) 177-210 doi: 10.1007/s10462-004-0751-8