Perfect hash function
In computer science, a perfect hash function for a set S is a hash function that maps distinct elements in S to a set of integers, with no collisions. In mathematical terms, it is an injective function.
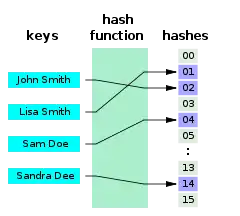
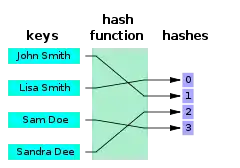
Perfect hash functions may be used to implement a lookup table with constant worst-case access time. A perfect hash function has many of the same applications as other hash functions, but with the advantage that no collision resolution has to be implemented. In addition, if the keys are not the data, the keys do not need to be stored in the lookup table, saving space.
Application
A perfect hash function with values in a limited range can be used for efficient lookup operations, by placing keys from S (or other associated values) in a lookup table indexed by the output of the function. One can then test whether a key is present in S, or look up a value associated with that key, by looking for it at its cell of the table. Each such lookup takes constant time in the worst case.[1]
Construction
A perfect hash function for a specific set S that can be evaluated in constant time, and with values in a small range, can be found by a randomized algorithm in a number of operations that is proportional to the size of S. The original construction of Fredman, Komlós & Szemerédi (1984) uses a two-level scheme to map a set S of n elements to a range of O(n) indices, and then map each index to a range of hash values. The first level of their construction chooses a large prime p (larger than the size of the universe from which S is drawn), and a parameter k, and maps each element x of S to the index

If k is chosen randomly, this step is likely to have collisions, but the number of elements ni that are simultaneously mapped to the same index i is likely to be small. The second level of their construction assigns disjoint ranges of O(ni2) integers to each index i. It uses a second set of linear modular functions, one for each index i, to map each member x of S into the range associated with g(x).[1]
As Fredman, Komlós & Szemerédi (1984) show, there exists a choice of the parameter k such that the sum of the lengths of the ranges for the n different values of g(x) is O(n). Additionally, for each value of g(x), there exists a linear modular function that maps the corresponding subset of S into the range associated with that value. Both k, and the second-level functions for each value of g(x), can be found in polynomial time by choosing values randomly until finding one that works.[1]
The hash function itself requires storage space O(n) to store k, p, and all of the second-level linear modular functions. Computing the hash value of a given key x may be performed in constant time by computing g(x), looking up the second-level function associated with g(x), and applying this function to x. A modified version of this two-level scheme with a larger number of values at the top level can be used to construct a perfect hash function that maps S into a smaller range of length n + o(n).[1]
Space lower bounds
The use of O(n) words of information to store the function of Fredman, Komlós & Szemerédi (1984) is near-optimal: any perfect hash function that can be calculated in constant time requires at least a number of bits that is proportional to the size of S.[2]
Extensions
Dynamic perfect hashing
Using a perfect hash function is best in situations where there is a frequently queried large set, S, which is seldom updated. This is because any modification of the set S may cause the hash function to no longer be perfect for the modified set. Solutions which update the hash function any time the set is modified are known as dynamic perfect hashing,[3] but these methods are relatively complicated to implement.
Minimal perfect hash function
A minimal perfect hash function is a perfect hash function that maps n keys to n consecutive integers – usually the numbers from 0 to n − 1 or from 1 to n. A more formal way of expressing this is: Let j and k be elements of some finite set S. Then F is a minimal perfect hash function if and only if F(j) = F(k) implies j = k (injectivity) and there exists an integer a such that the range of F is a..a + |S| − 1. It has been proven that a general purpose minimal perfect hash scheme requires at least 1.44 bits/key.[4] The best currently known minimal perfect hashing schemes can be represented using less than 1.56 bits/key if given enough time. [5]
Order preservation
A minimal perfect hash function F is order preserving if keys are given in some order a1, a2, ..., an and for any keys aj and ak, j < k implies F(aj) < F(ak).[6] In this case, the function value is just the position of each key in the sorted ordering of all of the keys. A simple implementation of order-preserving minimal perfect hash functions with constant access time is to use an (ordinary) perfect hash function or cuckoo hashing to store a lookup table of the positions of each key. If the keys to be hashed are themselves stored in a sorted array, it is possible to store a small number of additional bits per key in a data structure that can be used to compute hash values quickly.[7] Order-preserving minimal perfect hash functions require necessarily Ω(n log n) bits to be represented.[8]
Related constructions
A simple alternative to perfect hashing, which also allows dynamic updates, is cuckoo hashing. This scheme maps keys to two or more locations within a range (unlike perfect hashing which maps each key to a single location) but does so in such a way that the keys can be assigned one-to-one to locations to which they have been mapped. Lookups with this scheme are slower, because multiple locations must be checked, but nevertheless take constant worst-case time.[9]
References
- Fredman, Michael L.; Komlós, János; Szemerédi, Endre (1984), "Storing a Sparse Table with O(1) Worst Case Access Time", Journal of the ACM, 31 (3): 538, doi:10.1145/828.1884, MR 0819156
- Fredman, Michael L.; Komlós, János (1984), "On the size of separating systems and families of perfect hash functions", SIAM Journal on Algebraic and Discrete Methods, 5 (1): 61–68, doi:10.1137/0605009, MR 0731857.
- Dietzfelbinger, Martin; Karlin, Anna; Mehlhorn, Kurt; Meyer auf der Heide, Friedhelm; Rohnert, Hans; Tarjan, Robert E. (1994), "Dynamic perfect hashing: upper and lower bounds", SIAM Journal on Computing, 23 (4): 738–761, doi:10.1137/S0097539791194094, MR 1283572.
- Belazzougui, Djamal; Botelho, Fabiano C.; Dietzfelbinger, Martin (2009), "Hash, displace, and compress" (PDF), Algorithms—ESA 2009: 17th Annual European Symposium, Copenhagen, Denmark, September 7-9, 2009, Proceedings (PDF), Lecture Notes in Computer Science, 5757, Berlin: Springer, pp. 682–693, CiteSeerX 10.1.1.568.130, doi:10.1007/978-3-642-04128-0_61, MR 2557794.
- Esposito, Emmanuel; Mueller Graf, Thomas; Vigna, Sebastiano (2020), "RecSplit: Minimal Perfect Hashing via Recursive Splitting", 2020 Proceedings of the Symposium on Algorithm Engineering and Experiments (ALENEX), Proceedings, pp. 175–185, arXiv:1910.06416, doi:10.1137/1.9781611976007.14.
- Jenkins, Bob (14 April 2009), "order-preserving minimal perfect hashing", in Black, Paul E. (ed.), Dictionary of Algorithms and Data Structures, U.S. National Institute of Standards and Technology, retrieved 2013-03-05
- Belazzougui, Djamal; Boldi, Paolo; Pagh, Rasmus; Vigna, Sebastiano (November 2008), "Theory and practice of monotone minimal perfect hashing", Journal of Experimental Algorithmics, 16, Art. no. 3.2, 26pp, doi:10.1145/1963190.2025378.
- Fox, Edward A.; Chen, Qi Fan; Daoud, Amjad M.; Heath, Lenwood S. (July 1991), "Order-preserving minimal perfect hash functions and information retrieval" (PDF), ACM Transactions on Information Systems, New York, NY, USA: ACM, 9 (3): 281–308, doi:10.1145/125187.125200.
- Pagh, Rasmus; Rodler, Flemming Friche (2004), "Cuckoo hashing", Journal of Algorithms, 51 (2): 122–144, doi:10.1016/j.jalgor.2003.12.002, MR 2050140.
Further reading
- Richard J. Cichelli. Minimal Perfect Hash Functions Made Simple, Communications of the ACM, Vol. 23, Number 1, January 1980.
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Third Edition. MIT Press, 2009. ISBN 978-0262033848. Section 11.5: Perfect hashing, pp.267, 277–282.
- Fabiano C. Botelho, Rasmus Pagh and Nivio Ziviani. "Perfect Hashing for Data Management Applications".
- Fabiano C. Botelho and Nivio Ziviani. "External perfect hashing for very large key sets". 16th ACM Conference on Information and Knowledge Management (CIKM07), Lisbon, Portugal, November 2007.
- Djamal Belazzougui, Paolo Boldi, Rasmus Pagh, and Sebastiano Vigna. "Monotone minimal perfect hashing: Searching a sorted table with O(1) accesses". In Proceedings of the 20th Annual ACM-SIAM Symposium On Discrete Mathematics (SODA), New York, 2009. ACM Press.
- Douglas C. Schmidt, GPERF: A Perfect Hash Function Generator, C++ Report, SIGS, Vol. 10, No. 10, November/December, 1998.
External links
- gperf is an Open Source C and C++ perfect hash generator (very fast, but only works for small sets)
- Minimal Perfect Hashing (bob algorithm) by Bob Jenkins
- cmph: C Minimal Perfect Hashing Library, open source implementations for many (minimal) perfect hashes (works for big sets)
- Sux4J: open source monotone minimal perfect hashing in Java
- MPHSharp: perfect hashing methods in C#
- BBHash: minimal perfect hash function in header-only C++
- Perfect::Hash, perfect hash generator in Perl that makes C code. Has a "prior art" section worth looking at.
