Array DBMS
Array database management systems (array DBMSs) provide database services specifically for arrays (also called raster data), that is: homogeneous collections of data items (often called pixels, voxels, etc.), sitting on a regular grid of one, two, or more dimensions. Often arrays are used to represent sensor, simulation, image, or statistics data. Such arrays tend to be Big Data, with single objects frequently ranging into Terabyte and soon Petabyte sizes; for example, today’s earth and space observation archives typically grow by Terabytes a day. Array databases aim at offering flexible, scalable storage and retrieval on this information category.
Overview
In the same style as standard database systems do on sets, Array DBMSs offer scalable, flexible storage and flexible retrieval/manipulation on arrays of (conceptually) unlimited size. As in practice arrays never appear standalone, such an array model normally is embedded into some overall data model, such as the relational model. Some systems implement arrays as an analogy to tables, some introduce arrays as an additional attribute type.
Management of arrays requires novel techniques, particularly due to the fact that traditional database tuples and objects tend to fit well into a single database page – a unit of disk access on server, typically 4 KB – while array objects easily can span several media. The prime task of the array storage manager is to give fast access to large arrays and sub-arrays. To this end, arrays get partitioned, during insertion, into so-called tiles or chunks of convenient size which then act as units of access during query evaluation.
Array DBMSs offer query languages giving declarative access to such arrays, allowing to create, manipulate, search, and delete them. Like with, e.g., SQL, expressions of arbitrary complexity can be built on top of a set of core array operations. Due to the extensions made in the data and query model, Array DBMSs sometimes are subsumed under the NoSQL category, in the sense of "not only SQL". Query optimization and parallelization are important for achieving scalability; actually, many array operators lend themselves well towards parallel evaluation, by processing each tile on separate nodes or cores.
Important application domains of Array DBMSs include Earth, Space, Life, and Social sciences, as well as the related commercial applications (such as hydrocarbon exploration in industry and OLAP in business). The variety occurring can be observed, e.g., in geo data where 1-D environmental sensor time series, 2-D satellite images, 3-D x/y/t image time series and x/y/z geophysics data, as well as 4-D x/y/z/t climate and ocean data can be found.
History and status
The relational data model, which is prevailing today, does not directly support the array paradigm to the same extent as sets and tuples. ISO SQL lists an array-valued attribute type, but this is only one-dimensional, with almost no operational support, and not usable for the application domains of Array DBMSs. Another option is to resort to BLOBs ("binary large objects") which are the equivalent to files: byte strings of (conceptually) unlimited length, but again without any query language functionality, such as multi-dimensional subsetting.
First significant work in going beyond BLOBs has been established with PICDMS.[1] This system offers the precursor of a 2-D array query language, albeit still procedural and without suitable storage support.
A first declarative query language suitable for multiple dimensions and with an algebra-based semantics has been published by Baumann, together with a scalable architecture.[2][3] Another array database language, constrained to 2-D, has been presented by Marathe and Salem.[4] Seminal theoretical work has been accomplished by Libkin et al.;[5] in their model, called NCRA, they extend a nested relational calculus with multidimensional arrays; among the results are important contributions on array query complexity analysis. A map algebra, suitable for 2-D and 3-D spatial raster data, has been published by Mennis et al.[6]
In terms of Array DBMS implementations, the rasdaman system has the longest implementation track record of n-D arrays with full query support. Oracle GeoRaster offers chunked storage of 2-D raster maps, albeit without SQL integration. TerraLib is an open-source GIS software that extends object-relational DBMS technology to handle spatio-temporal data types; while main focus is on vector data, there is also some support for rasters. Starting with version 2.0, PostGIS embeds raster support for 2-D rasters; a special function offers declarative raster query functionality. SciQL is an array query language being added to the MonetDB DBMS. SciDB is a more recent initiative to establish array database support. Like SciQL, arrays are seen as an equivalent to tables, rather than a new attribute type as in rasdaman and PostGIS.
For the special case of sparse data, OLAP data cubes are well established; they store cell values together with their location – an adequate compression technique in face of the few locations carrying valid information at all – and operate with SQL on them. As this technique does not scale in density, standard databases are not used today for dense data, like satellite images, where most cells carry meaningful information; rather, proprietary ad-hoc implementations prevail in scientific data management and similar situations. Hence, this is where Array DBMSs can make a particular contribution.
Generally, Array DBMSs are an emerging technology. While operationally deployed systems exist, like Oracle GeoRaster, PostGIS 2.0 and rasdaman, there are still many open research questions, including query language design and formalization, query optimization, parallelization and distributed processing, and scalability issues in general. Besides, scientific communities still appear reluctant in taking up array database technology and tend to favor specialized, proprietary technology.
Concepts
When adding arrays to databases, all facets of database design need to be reconsidered – ranging from conceptual modeling (such as suitable operators) over storage management (such as management of arrays spanning multiple media) to query processing (such as efficient processing strategies).
Conceptual modeling
Formally, an array A is given by a (total or partial) function A: X → V where X, the domain is a d-dimensional integer interval for some d>0 and V, called range, is some (non-empty) value set; in set notation, this can be rewritten as { (p,v) | p in X, v in V }. Each (p,v) in A denotes an array element or cell, and following common notation we write A[p] = v. Examples for X include {0..767} × {0..1023} (for XGA sized images), examples for V include {0..255} for 8-bit greyscale images and {0..255} × {0..255} × {0..255} for standard RGB imagery.
Following established database practice, an array query language should be declarative and safe in evaluation. As iteration over an array is at the heart of array processing, declarativeness very much centers on this aspect. The requirement, then, is that conceptually all cells should be inspected simultaneously – in other words, the query does not enforce any explicit iteration sequence over the array cells during evaluation. Evaluation safety is achieved when every query terminates after a finite number of (finite-time) steps; again, avoiding general loops and recursion is a way of achieving this. At the same time, avoiding explicit loop sequences opens up manifold optimization opportunities.
Array querying
As an example for array query operators the rasdaman algebra and query language can serve, which establish an expression language over a minimal set of array primitives. We begin with the generic core operators and then present common special cases and shorthands.
The marray operator creates an array over some given domain extent and initializes its cells:
marray index-range-specification
values cell-value-expression
where index-range-specification defines the result domain and binds an iteration variable to it, without specifying iteration sequence. The cell-value-expression is evaluated at each location of the domain.
Example: “A cutout of array A given by the corner points (10,20) and (40,50).”
marray p in [10:20,40:50]
values A[p]
This special case, pure subsetting, can be abbreviated as
A[10:20,40:50]
This subsetting keeps the dimension of the array; to reduce dimension by extracting slices, a single slicepoint value is indicated in the slicing dimension.
Example: “A slice through an x/y/t timeseries at position t=100, retrieving all available data in x and y.”
A[*:*,*:*,100]
The wildcard operator * indicates that the current boundary of the array is to be used; note that arrays where dimension boundaries are left open at definition time may change size in that dimensions over the array's lifetime.
The above examples have simply copied the original values; instead, these values may be manipulated.
Example: “Array A, with a log() applied to each cell value.”
marray p in domain(A)
values log( A[p] )
This can be abbreviated as:
log( A )
Through a principle called induced operations,[7] the query language offers all operations the cell type offers on array level, too. Hence, on numeric values all the usual unary and binary arithmetic, exponential, and trigonometric operations are available in a straightforward manner, plus the standard set of Boolean operators.
The condense operator aggregates cell values into one scalar result, similar to SQL aggregates. Its application has the general form:
condense condense-op
over index-range-specification
using cell-value-expression
As with marray before, the index-range-specification specifies the domain to be iterated over and binds an iteration variable to it – again, without specifying iteration sequence. Likewise, cell-value-expression is evaluated at each domain location. The condense-op clause specifies the aggregating operation used to combine the cell value expressions into one single value.
Example: "The sum over all values in A."
condense +
over p in sdom(A)
using A[p]
A shorthand for this operation is:
add_cells( A )
In the same manner and in analogy to SQL aggregates, a number of further shorthands are provided, including counting, average, minimum, maximum, and Boolean quantifiers.
The next example demonstrates combination of marray and condense operators by deriving a histogram.
Example: "A histogram over 8-bit greyscale image A."
marray bucket in [0:255]
values count_cells( A = bucket )
The induced comparison, A=bucket, establishes a Boolean array of the same extent as A. The aggregation operator counts the occurrences of true for each value of bucket, which subsequently is put into the proper array cell of the 1-D histogram array.
Such languages allow formulating statistical and imaging operations which can be expressed analytically without using loops. It has been proven[8] that the expressive power of such array languages in principle is equivalent to relational query languages with ranking.
Array storage
Array storage has to accommodate arrays of different dimensions and typically large sizes. A core task is to maintain spatial proximity on disk so as to reduce the number of disk accesses during subsetting. Note that an emulation of multi-dimensional arrays as nested lists (or 1-D arrays) will not per se accomplish this and, therefore, in general will not lead to scalable architectures.
Commonly arrays are partitioned into sub-arrays which form the unit of access. Regular partitioning where all partitions have the same size (except possibly for boundaries) is referred to as chunking.[9] A generalization which removes the restriction to equally sized partitions by supporting any kind of partitioning is tiling.[10] Array partitioning can improve access to array subsets significantly: by adjusting tiling to the access pattern, the server ideally can fetch all required data with only one disk access.
Compression of tiles can sometimes reduce substantially the amount of storage needed. Also for transmission of results compression is useful, as for the large amounts of data under consideration networks bandwidth often constitutes a limiting factor.
Query processing
A tile-based storage structure suggests a tile-by-tile processing strategy (in rasdaman called tile streaming). A large class of practically relevant queries can be evaluated by loading tile after tile, thereby allowing servers to process arrays orders of magnitude beyond their main memory.
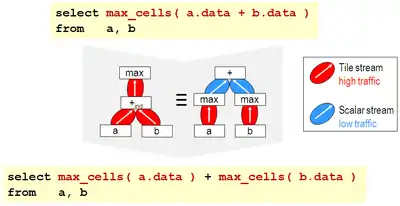
Due to the massive sizes of arrays in scientific/technical applications in combination with often complex queries, optimization plays a central role in making array queries efficient. Both hardware and software parallelization can be applied. An example for heuristic optimization is the rule "maximum value of an array resulting from the cell-wise addition of two input images is equivalent to adding the maximum values of each input array". By replacing the left-hand variant by the right-hand expression, costs shrink from three (costly) array traversals to two array traversals plus one (cheap) scalar operation (see Figure, which uses the SQL/MDA query standard).
Application domains
In many – if not most – cases where some phenomenon is sampled or simulated the result is a rasterized data set which can conveniently be stored, retrieved, and forwarded as an array. Typically, the array data are ornamented with metadata describing them further; for example, geographically referenced imagery will carry its geographic position and the coordinate reference system in which it is expressed.
The following are representative domains in which large-scale multi-dimensional array data are handled:
- Earth sciences: geodesy / mapping, remote sensing, geology, oceanography, hydrology, atmospheric sciences, cryospheric sciences
- Space sciences: Planetary sciences, astrophysics (optical and radio telescope observations, cosmological simulations)
- Life sciences: gene data, confocal microscopy, CAT scans
- Social sciences: statistical data cubes
- Business: OLAP, data warehousing
These are but examples; generally, arrays frequently represent sensor, simulation, image, and statistics data. More and more spatial and time dimensions are combined with abstract axes, such as sales and products; one example where such abstract axes are explicitly foreseen is the [Open_Geospatial_Consortium |Open Geospatial Consortium] (OGC) coverage model.
Standardization
Many communities have established data exchange formats, such as HDF, NetCDF, and TIFF. A de facto standard in the Earth Science communities is OPeNDAP, a data transport architecture and protocol. While this is not a database specification, it offers important components that characterize a database system, such as a conceptual model and client/server implementations.
A declarative geo raster query language, Web Coverage Processing Service (WCPS), has been standardized by the Open Geospatial Consortium (OGC).
In June 2014, ISO/IEC JTC1 SC32 WG3, which maintains the SQL database standard, has decided to add multi-dimensional array support to SQL as a new column type,[11] based on the initial array support available since the 2003 version of SQL. The new standard, adopted in Fall 2018, is named ISO 9075 SQL Part 15: MDA (Multi-Dimensional Arrays).
List of array DBMSs
See also
References
- Chock, M., Cardenas, A., Klinger, A.: Database structure and manipulation capabilities of a picture database management system (PICDMS). IEEE ToPAMI, 6(4):484–492, 1984
- Baumann, P.: On the Management of Multidimensional Discrete Data. VLDB Journal 4(3)1994, Special Issue on Spatial Database Systems, pp. 401–444
- Baumann, P.: A Database Array Algebra for Spatio-Temporal Data and Beyond. Proc. NGITS’99, LNCS 1649, Springer 1999, pp.76-93
- Marathe, A., Salem, K.: A language for manipulating arrays. Proc. VLDB’97, Athens, Greece, August 1997, pp. 46–55
- Libkin, L., Machlin, R., Wong, L.: A query language for multidimensional arrays: design, implementation and optimization techniques. Proc. ACM SIGMOD’96, Montreal, Canada, pp. 228–239
- Mennis, J., Viger, R., Tomlin, C.D.: Cubic Map Algebra Functions for Spatio-Temporal Analysis. Cartography and Geographic Information Science 32(1)2005, pp. 17–32
- Ritter, G. and Wilson, J. and Davidson, J.: Image Algebra: An Overview. Computer Vision, Graphics, and Image Processing, 49(1)1994, 297-336
- Machlin, R.: Index-Based Multidimensional Array Queries: Safety and Equivalence. Proc. ACM PODS'07, Beijing, China, June 2007, pp. 175–184
- Sarawagi, S., Stonebraker, M.: Efficient Organization of Large Multidimensional Arrays. Proc. ICDE'94, Houston, USA, 1994, pp. 328-336
- Furtado, P., Baumann, P.: Storage of Multidimensional Arrays based on Arbitrary Tiling. Proc. ICDE'99, March 23–26, 1999, Sydney, Australia, pp. 328–336
- Chirgwin, R.: SQL fights back against NoSQL's big data cred with SQL/MDA spec, The Register, 26 Jun 2014
| Types | |
|---|---|
| Concepts | |
| Objects | |
| Components | |
| Functions | |
| Related topics | |
| |
