Database normalization
Database normalization is the process of structuring a database, usually a relational database, in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by Edgar F. Codd as part of his relational model.
Normalization entails organizing the columns (attributes) and tables (relations) of a database to ensure that their dependencies are properly enforced by database integrity constraints. It is accomplished by applying some formal rules either by a process of synthesis (creating a new database design) or decomposition (improving an existing database design).
Objectives
A basic objective of the first normal form defined by Codd in 1970 was to permit data to be queried and manipulated using a "universal data sub-language" grounded in first-order logic.[1] (SQL is an example of such a data sub-language, albeit one that Codd regarded as seriously flawed.[2])
The objectives of normalization beyond 1NF (first normal form) were stated as follows by Codd:
- To free the collection of relations from undesirable insertion, update and deletion dependencies.
- To reduce the need for restructuring the collection of relations, as new types of data are introduced, and thus increase the life span of application programs.
- To make the relational model more informative to users.
- To make the collection of relations neutral to the query statistics, where these statistics are liable to change as time goes by.
— E.F. Codd, "Further Normalization of the Data Base Relational Model"[3]

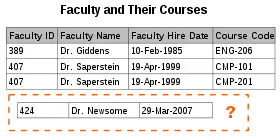
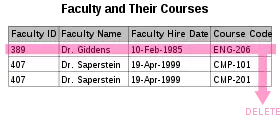
When an attempt is made to modify (update, insert into, or delete from) a relation, the following undesirable side-effects may arise in relations that have not been sufficiently normalized:
- Update anomaly. The same information can be expressed on multiple rows; therefore updates to the relation may result in logical inconsistencies. For example, each record in an "Employees' Skills" relation might contain an Employee ID, Employee Address, and Skill; thus a change of address for a particular employee may need to be applied to multiple records (one for each skill). If the update is only partially successful – the employee's address is updated on some records but not others – then the relation is left in an inconsistent state. Specifically, the relation provides conflicting answers to the question of what this particular employee's address is. This phenomenon is known as an update anomaly.
- Insertion anomaly. There are circumstances in which certain facts cannot be recorded at all. For example, each record in a "Faculty and Their Courses" relation might contain a Faculty ID, Faculty Name, Faculty Hire Date, and Course Code. Therefore, we can record the details of any faculty member who teaches at least one course, but we cannot record a newly hired faculty member who has not yet been assigned to teach any courses, except by setting the Course Code to null. This phenomenon is known as an insertion anomaly.
- Deletion anomaly. Under certain circumstances, deletion of data representing certain facts necessitates deletion of data representing completely different facts. The "Faculty and Their Courses" relation described in the previous example suffers from this type of anomaly, for if a faculty member temporarily ceases to be assigned to any courses, we must delete the last of the records on which that faculty member appears, effectively also deleting the faculty member, unless we set the Course Code to null. This phenomenon is known as a deletion anomaly.
Minimize redesign when extending the database structure
A fully normalized database allows its structure to be extended to accommodate new types of data without changing existing structure too much. As a result, applications interacting with the database are minimally affected.
Normalized relations, and the relationship between one normalized relation and another, mirror real-world concepts and their interrelationships.
Example
Querying and manipulating the data within a data structure that is not normalized, such as the following non-1NF representation of customers' credit card transactions, involves more complexity than is really necessary:
| Customer | Cust. ID | Transactions | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Abraham | 1 |
| ||||||||||||
| Isaac | 2 |
| ||||||||||||
| Jacob | 3 |
|
To each customer corresponds a 'repeating group' of transactions. The automated evaluation of any query relating to customers' transactions, therefore, would broadly involve two stages:
- Unpacking one or more customers' groups of transactions allowing the individual transactions in a group to be examined, and
- Deriving a query result based on the results of the first stage
For example, in order to find out the monetary sum of all transactions that occurred in October 2003 for all customers, the system would have to know that it must first unpack the Transactions group of each customer, then sum the Amounts of all transactions thus obtained where the Date of the transaction falls in October 2003.
One of Codd's important insights was that structural complexity can be reduced. Reduced structural complexity gives users, applications, and DBMSs more power and flexibility to formulate and evaluate the queries. A more normalized equivalent of the structure above might look like this:
| Customer | Cust. ID |
|---|---|
| Abraham | 1 |
| Isaac | 2 |
| Jacob | 3 |
| Cust. ID | Tr. ID | Date | Amount |
|---|---|---|---|
| 1 | 12890 | 14-Oct-2003 | −87 |
| 1 | 12904 | 15-Oct-2003 | −50 |
| 2 | 12898 | 14-Oct-2003 | −21 |
| 3 | 12907 | 15-Oct-2003 | −18 |
| 3 | 14920 | 20-Nov-2003 | −70 |
| 3 | 15003 | 27-Nov-2003 | −60 |
In the modified structure, the primary key is {Cust. ID} in the first relation, {Cust. ID, Tr. ID} in the second relation.
Now each row represents an individual credit card transaction, and the DBMS can obtain the answer of interest, simply by finding all rows with a Date falling in October, and summing their Amounts. The data structure places all of the values on an equal footing, exposing each to the DBMS directly, so each can potentially participate directly in queries; whereas in the previous situation some values were embedded in lower-level structures that had to be handled specially. Accordingly, the normalized design lends itself to general-purpose query processing, whereas the unnormalized design does not. The normalized version also allows the user to change the customer name in one place and guards against errors that arise if the customer name is misspelled on some records.
Normal forms
Codd introduced the concept of normalization and what is now known as the first normal form (1NF) in 1970.[4] Codd went on to define the second normal form (2NF) and third normal form (3NF) in 1971,[5] and Codd and Raymond F. Boyce defined the Boyce-Codd normal form (BCNF) in 1974.[6]
Informally, a relational database relation is often described as "normalized" if it meets third normal form.[7] Most 3NF relations are free of insertion, update, and deletion anomalies.
The normal forms (from least normalized to most normalized) are:
- UNF: Unnormalized form
- 1NF: First normal form
- 2NF: Second normal form
- 3NF: Third normal form
- EKNF: Elementary key normal form
- BCNF: Boyce–Codd normal form
- 4NF: Fourth normal form
- ETNF: Essential tuple normal form
- 5NF: Fifth normal form
- DKNF: Domain-key normal form
- 6NF: Sixth normal form
| UNF (1970) |
1NF (1970) |
2NF (1971) |
3NF (1971) |
EKNF (1982) |
BCNF (1974) |
4NF (1977) |
ETNF (2012) |
5NF (1979) |
DKNF (1981) |
6NF (2003) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Primary key (no duplicate tuples) | |||||||||||
| No repeating groups | |||||||||||
| Atomic columns (cells have single value)[8] | |||||||||||
| Every non-trivial functional dependency either does not begin with a proper subset of a candidate key or ends with a prime attribute (no partial functional dependencies of non-prime attributes on candidate keys)[8] | |||||||||||
| Every non-trivial functional dependency either begins with a superkey or ends with a prime attribute (no transitive functional dependencies of non-prime attributes on candidate keys)[8] | |||||||||||
| Every non-trivial functional dependency either begins with a superkey or ends with an elementary prime attribute[8] | N/A | ||||||||||
| Every non-trivial functional dependency begins with a superkey[8] | N/A | ||||||||||
| Every non-trivial multivalued dependency begins with a superkey[8] | N/A | ||||||||||
| Every join dependency has a superkey component[9] | N/A | ||||||||||
| Every join dependency has only superkey components[8] | N/A | ||||||||||
| Every constraint is a consequence of domain constraints and key constraints[8] | N/A | ||||||||||
| Every join dependency is trivial[8] |
Example of a step by step normalization
Normalization is a database design technique, which is used to design a relational database table up to higher normal form.[10] The process is progressive, and a higher level of database normalization cannot be achieved unless the previous levels have been satisfied.[11]
That means that, having data in unnormalized form (the least normalized) and aiming to achieve the highest level of normalization, the first step would be to ensure compliance to first normal form, the second step would be to ensure second normal form is satisfied, and so forth in order mentioned above, until the data conform to sixth normal form.
However, it is worth noting that normal forms beyond 4NF are mainly of academic interest, as the problems they exist to solve rarely appear in practice.[12]
Please note that the data in the following example were intentionally designed to contradict most of the normal forms. In real life, it's quite possible to be able to skip some of the normalization steps because the table doesn't contain anything contradicting the given normal form. It also commonly occurs that fixing a violation of one normal form also fixes a violation of a higher normal form in the process. Also one table has been chosen for normalization at each step, meaning that at the end of this example process, there might still be some tables not satisfying the highest normal form.
Initial data
Let a database table with the following structure:[11]
| Title | Author | Author Nationality | Format | Price | Subject | Pages | Thickness | Publisher | Publisher Country | Publication Type | Genre ID | Genre Name |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | Chad Russell | American | Hardcover | 49.99 | MySQL,
Database, Design |
520 | Thick | Apress | USA | E-book | 1 | Tutorial |
We assume in this example that each book has only one author.
Satisfying 1NF
To satisfy 1NF, the values in each column of a table must be atomic. In the initial table, Subject contains a set of subject values, meaning it does not comply.
One way to achieve the 1NF would be to separate the duplicities into multiple columns using repeating groups Subject:
| Title | Format | Author | Author Nationality | Price | Subject 1 | Subject 2 | Subject 3 | Pages | Thickness | Publisher | Publisher country | Genre ID | Genre Name |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | Hardcover | Chad Russell | American | 49.99 | MySQL | Database | Design | 520 | Thick | Apress | USA | 1 | Tutorial |
Although now the table formally complies to the 1NF (is atomic), the problem with this solution is obvious - if a book has more than three subjects, it cannot be added to the database without altering its structure.
To solve the problem in a more elegant way, it is necessary to identify entities represented in the table and separate them into their own respective tables. In this case, it would result in Book, Subject and Publisher tables:[11]
| Title | Format | Author | Author Nationality | Price | Pages | Thickness | Genre ID | Genre Name | Publisher ID |
|---|---|---|---|---|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | Hardcover | Chad Russell | American | 49.99 | 520 | Thick | 1 | Tutorial | 1 |
|
|
Simply separating the initial data into multiple tables would break the connection between the data. That means the relationships between the newly introduced tables need to be determined. Notice that the Publisher ID column in the Book's table is a foreign key realizing many-to-one relation between a book and a publisher.
A book can fit many subjects, as well as a subject may correspond to many books. That means also a many-to-many relationship needs to be defined, achieved by creating a link table:[11]
|
Instead of one table in unnormalized form, there are now 4 tables conforming to the 1NF.
Satisfying 2NF
The Book table has one candidate key (which is therefore the primary key), the compound key {Title, Format}.[13] Consider the following table fragment:
| Title | Format | Author | Author Nationality | Price | Pages | Thickness | Genre ID | Genre Name | Publisher ID |
|---|---|---|---|---|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | Hardcover | Chad Russell | American | 49.99 | 520 | Thick | 1 | Tutorial | 1 |
| Beginning MySQL Database Design and Optimization | E-book | Chad Russell | American | 22.34 | 520 | Thick | 1 | Tutorial | 1 |
| The Relational Model for Database Management: Version 2 | E-book | E.F.Codd | British | 13.88 | 538 | Thick | 2 | Popular science | 2 |
| The Relational Model for Database Management: Version 2 | Paperback | E.F.Codd | British | 39.99 | 538 | Thick | 2 | Popular science | 2 |
All of the attributes that are not part of the candidate key depend on Title, but only Price also depends on Format. To conform to 2NF and remove duplicities, every non candidate-key attribute must depend on the whole candidate key, not just part of it.
To normalize this table, make {Title} a (simple) candidate key (the primary key) so that every non candidate-key attribute depends on the whole candidate key, and remove Price into a separate table so that its dependency on Format can be preserved:
|
|
Now, the Book table conforms to 2NF.
Satisfying 3NF
The Book table still has a transitive functional dependency ({Author Nationality} is dependent on {Author}, which is dependent on {Title}). A similar violation exists for genre ({Genre Name} is dependent on {Genre ID}, which is dependent on {Title}). Hence, the Book table is not in 3NF. To make it in 3NF, let's use the following table structure, thereby eliminating the transitive functional dependencies by placing {Author Nationality} and {Genre Name} in their own respective tables:
| Title | Author | Pages | Thickness | Genre ID | Publisher ID |
|---|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | Chad Russell | 520 | Thick | 1 | 1 |
| The Relational Model for Database Management: Version 2 | E.F.Codd | 538 | Thick | 2 | 2 |
|
| Author | Author Nationality |
|---|---|
| Chad Russell | American |
| E.F.Codd | British |
| Genre ID | Genre Name |
|---|---|
| 1 | Tutorial |
| 2 | Popular science |
Satisfying EKNF
The elementary key normal form (EKNF) falls strictly between 3NF and BCNF and is not much discussed in the literature. It is intended “to capture the salient qualities of both 3NF and BCNF” while avoiding the problems of both (namely, that 3NF is “too forgiving” and BCNF is “prone to computational complexity”). Since it is rarely mentioned in literature, it is not included in this example.[14]
Satisfying 4NF
Assume the database is owned by a book retailer franchise that has several franchisees that own shops in different locations. And therefore the retailer decided to add a table that contains data about availability of the books at different locations:
| Franchisee ID | Title | Location |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | California |
| 1 | Beginning MySQL Database Design and Optimization | Florida |
| 1 | Beginning MySQL Database Design and Optimization | Texas |
| 1 | The Relational Model for Database Management: Version 2 | California |
| 1 | The Relational Model for Database Management: Version 2 | Florida |
| 1 | The Relational Model for Database Management: Version 2 | Texas |
| 2 | Beginning MySQL Database Design and Optimization | California |
| 2 | Beginning MySQL Database Design and Optimization | Florida |
| 2 | Beginning MySQL Database Design and Optimization | Texas |
| 2 | The Relational Model for Database Management: Version 2 | California |
| 2 | The Relational Model for Database Management: Version 2 | Florida |
| 2 | The Relational Model for Database Management: Version 2 | Texas |
| 3 | Beginning MySQL Database Design and Optimization | Texas |
As this table structure consists of a compound primary key, it doesn't contain any non-key attributes and it's already in BCNF (and therefore also satisfies all the previous normal forms). However, if we assume that all available books are offered in each area, we might notice that the Title is not unambiguously bound to a certain Location and therefore the table doesn't satisfy 4NF.
That means that, to satisfy the fourth normal form, this table needs to be decomposed as well:
|
|
Now, every record is unambiguously identified by a superkey, therefore 4NF is satisfied.[15]
Satisfying ETNF
Suppose the franchisees can also order books from different suppliers. Let the relation also be subject to the following constraint:
- If a certain supplier supplies a certain title
- and the title is supplied to the franchisee
- and the franchisee is being supplied by the supplier,
- then the supplier supplies the title to the franchisee.[16]
| Supplier ID | Title | Franchisee ID |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | 1 |
| 2 | The Relational Model for Database Management: Version 2 | 2 |
| 3 | Learning SQL | 3 |
This table is in 4NF, but the Supplier ID is equal to the join of its projections: {{Supplier ID, Book}, {Book, Franchisee ID}, {Franchisee ID, Supplier ID}}. No component of that join dependency is a superkey (the sole superkey being the entire heading), so the table does not satisfy the ETNF and can be further decomposed:[16]
|
|
|
The decomposition produces ETNF compliance.
Satisfying 5NF
To spot a table not satisfying the 5NF, it is usually necessary to examine the data thoroughly. Suppose the table from 4NF example with a little modification in data and let's examine if it satisfies 5NF:
| Franchisee ID | Title | Location |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | California |
| 1 | Learning SQL | California |
| 1 | The Relational Model for Database Management: Version 2 | Texas |
| 2 | The Relational Model for Database Management: Version 2 | California |
If we decompose this table, we lower redundancies and get the following two tables:
|
|
What happens if we try to join these tables? The query would return the following data:
| Franchisee ID | Title | Location |
|---|---|---|
| 1 | Beginning MySQL Database Design and Optimization | California |
| 1 | Learning SQL | California |
| 1 | The Relational Model for Database Management: Version 2 | California |
| 1 | The Relational Model for Database Management: Version 2 | Texas |
| 1 | Learning SQL | Texas |
| 1 | Beginning MySQL Database Design and Optimization | Texas |
| 2 | The Relational Model for Database Management: Version 2 | California |
Apparently, the JOIN returns three more rows than it should - let's try to add another table to clarify the relation. We end up with three separate tables:
|
|
|
What will the JOIN return now? It actually is not possible to join these three tables. That means it wasn't possible to decompose the Franchisee - Book Location without data loss, therefore the table already satisfies 5NF.[15]
C.J. Date has argued that only a database in 5NF is truly "normalized".[17]
Satisfying DKNF
Let's have a look at the Book table from previous examples and see if it satisfies the Domain-key normal form:
| Title | Pages | Thickness | Genre ID | Publisher ID |
|---|---|---|---|---|
| Beginning MySQL Database Design and Optimization | 520 | Thick | 1 | 1 |
| The Relational Model for Database Management: Version 2 | 538 | Thick | 2 | 2 |
| Learning SQL | 338 | Slim | 1 | 3 |
| SQL Cookbook | 636 | Thick | 1 | 3 |
Logically, Thickness is determined by number of pages. That means it depends on Pages which is not a key. Let's set an example convention saying a book up to 350 pages is considered "slim" and a book over 350 pages is considered "thick".
This convention is technically a constraint but it is neither a domain constraint nor a key constraint; therefore we cannot rely on domain constraints and key constraints to keep the data integrity.
In other words - nothing prevents us from putting, for example, "Thick" for a book with only 50 pages - and this makes the table violate DKNF.
To solve this, we can create a table holding enumeration that defines the Thickness and remove that column from the original table:
|
|
That way, the domain integrity violation has been eliminated, and the table is in DKNF.
Satisfying 6NF
A simple and intuitive definition of the sixth normal form is that "a table is in 6NF when the row contains the Primary Key, and at most one other attribute".[18]
That means, for example, the Publisher table designed while creating the 1NF
| Publisher_ID | Name | Country |
|---|---|---|
| 1 | Apress | USA |
needs to be further decomposed into two tables:
|
|
The obvious drawback of 6NF is the proliferation of tables required to represent the information on a single entity. If a table in 5NF has one primary key column and N attributes, representing the same information in 6NF will require N tables; multi-field updates to a single conceptual record will require updates to multiple tables; and inserts and deletes will similarly require operations across multiple tables. For this reason, in databases intended to serve Online Transaction Processing needs, 6NF should not be used.
However, in data warehouses, which do not permit interactive updates and which are specialized for fast query on large data volumes, certain DBMSs use an internal 6NF representation - known as a Columnar data store. In situations where the number of unique values of a column is far less than the number of rows in the table, column-oriented storage allow significant savings in space through data compression. Columnar storage also allows fast execution of range queries (e.g., show all records where a particular column is between X and Y, or less than X.)
In all these cases, however, the database designer does not have to perform 6NF normalization manually by creating separate tables. Some DBMSs that are specialized for warehousing, such as Sybase IQ, use columnar storage by default, but the designer still sees only a single multi-column table. Other DBMSs, such as Microsoft SQL Server 2012 and later, let you specify a "columnstore index" for a particular table.[19]
Notes and references
- "The adoption of a relational model of data ... permits the development of a universal data sub-language based on an applied predicate calculus. A first-order predicate calculus suffices if the collection of relations is in first normal form. Such a language would provide a yardstick of linguistic power for all other proposed data languages, and would itself be a strong candidate for embedding (with appropriate syntactic modification) in a variety of host languages (programming, command- or problem-oriented)." Codd, "A Relational Model of Data for Large Shared Data Banks" Archived June 12, 2007, at the Wayback Machine, p. 381
- Codd, E.F. Chapter 23, "Serious Flaws in SQL", in The Relational Model for Database Management: Version 2. Addison-Wesley (1990), pp. 371–389
- Codd, E.F. "Further Normalization of the Data Base Relational Model", p. 34
- Codd, E. F. (June 1970). "A Relational Model of Data for Large Shared Data Banks". Communications of the ACM. 13 (6): 377–387. doi:10.1145/362384.362685. S2CID 207549016. Archived from the original on June 12, 2007. Retrieved August 25, 2005.
- Codd, E. F. "Further Normalization of the Data Base Relational Model". (Presented at Courant Computer Science Symposia Series 6, "Data Base Systems", New York City, May 24–25, 1971.) IBM Research Report RJ909 (August 31, 1971). Republished in Randall J. Rustin (ed.), Data Base Systems: Courant Computer Science Symposia Series 6. Prentice-Hall, 1972.
- Codd, E. F. "Recent Investigations into Relational Data Base Systems". IBM Research Report RJ1385 (April 23, 1974). Republished in Proc. 1974 Congress (Stockholm, Sweden, 1974), N.Y.: North-Holland (1974).
- Date, C. J. (1999). An Introduction to Database Systems. Addison-Wesley. p. 290.
- Bhattacharyya, Malay (February 2020). "Database Management Systems, Database Normalization" (PDF). Indian Statistical Institute. Retrieved June 22, 2020.
- Darwen, Hugh; Date, C. J.; Fagin, Ronald (2012). "A Normal Form for Preventing Redundant Tuples in Relational Databases" (PDF). Proceedings of the 15th International Conference on Database Theory. EDBT/ICDT 2012 Joint Conference. ACM International Conference Proceeding Series. Association for Computing Machinery. p. 114. doi:10.1145/2274576.2274589. ISBN 978-1-4503-0791-8. OCLC 802369023. Retrieved May 22, 2018.
- Kumar, Kunal; Azad, S. K. (October 2017). Database normalization design pattern. 2017 4th IEEE Uttar Pradesh Section International Conference on Electrical, Computer and Electronics (UPCON). IEEE. doi:10.1109/upcon.2017.8251067. ISBN 9781538630044. S2CID 24491594.
- "Database normalization in MySQL: Four quick and easy steps". ComputerWeekly.com. Retrieved January 21, 2019.
- "Database Normalization: 5th Normal Form and Beyond". MariaDB KnowledgeBase. Retrieved January 23, 2019.
- The table fragment itself has several candidate keys (simple key {Price}, and compound keys of Format together with any column except Price or Thickness), but we assume that in the complete table only {Title, Format} will be unique.
- "Additional Normal Forms - Database Design and Relational Theory - page 151". what-when-how.com. Retrieved January 22, 2019.
- "Normalizace databáze", Wikipedie (in Czech), November 7, 2018, retrieved January 22, 2019
- Date, C. J. (December 21, 2015). The New Relational Database Dictionary: Terms, Concepts, and Examples. "O'Reilly Media, Inc.". p. 138. ISBN 9781491951699.
- Date, C. J. (December 21, 2015). The New Relational Database Dictionary: Terms, Concepts, and Examples. "O'Reilly Media, Inc.". p. 163. ISBN 9781491951699.
- "normalization - Would like to Understand 6NF with an Example". Stack Overflow. Retrieved January 23, 2019.
- Microsoft Corporation. Columnstore Indexes: Overview. https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview . Accessed Mar 23, 2020.
Further reading
- Date, C. J. (1999), An Introduction to Database Systems (8th ed.). Addison-Wesley Longman. ISBN 0-321-19784-4.
- Kent, W. (1983) A Simple Guide to Five Normal Forms in Relational Database Theory, Communications of the ACM, vol. 26, pp. 120–125
- H.-J. Schek, P. Pistor Data Structures for an Integrated Data Base Management and Information Retrieval System
External links
- Kent, William (February 1983). "A Simple Guide to Five Normal Forms in Relational Database Theory". Communications of the ACM. 26 (2): 120–125. doi:10.1145/358024.358054. S2CID 9195704.
- Database Normalization Basics by Mike Chapple (About.com)
- Database Normalization Intro, Part 2
- An Introduction to Database Normalization by Mike Hillyer.
- A tutorial on the first 3 normal forms by Fred Coulson
- Description of the database normalization basics by Microsoft
- Normalization in DBMS by Chaitanya (beginnersbook.com)
- A Step-by-Step Guide to Database Normalization
- ETNF – Essential tuple normal form
| Main | |
|---|---|
| Languages | |
| Security | |
| Design |
|
| Programming | |
| Management |
|
| See also | |
| |
| Types | |
|---|---|
| Concepts | |
| Objects | |
| Components | |
| Functions | |
| Related topics | |
| |
