Consistent hashing
In computer science, consistent hashing[1][2] is a special kind of hashing such that when a hash table is resized, only keys need to be remapped on average where is the number of keys and is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped because the mapping between the keys and the slots is defined by a modular operation. Consistent hashing is a particular case of rendezvous hashing, which has a conceptually simpler algorithm, and was first described in 1996. Consistent hashing first appeared in 1997, and uses a different algorithm.[1]



History
The term "consistent hashing" was introduced by David Karger et al. at MIT for use in distributed caching. This academic paper from 1997 introduced the term "consistent hashing" as a way of distributing requests among a changing population of web servers. Each slot is then represented by a server in a distributed system. The addition of a server and the removal of server (say, due to failure) requires only items to be re-shuffled when the number of slots (i.e., servers) change. The authors mention linear hashing and its ability to handle sequential server addition and removal, while consistent hashing allows servers to be added and removed in arbitrary order. [1]

Teradata used this technique in their distributed database, released in 1986, although they did not use this term. Teradata still uses the concept of a hash table to fulfill exactly this purpose. Akamai Technologies was founded in 1998 by the scientists Daniel Lewin and F. Thomson Leighton (co-authors of the article coining "consistent hashing"). In Akamai's content delivery network,[3] consistent hashing is used to balance the load within a cluster of servers, while a stable marriage algorithm is used to balance load across clusters.[2]
Consistent hashing has also been used to reduce the impact of partial system failures in large web applications to provide robust caching without incurring the system-wide fallout of a failure.[4] Consistent hashing is also the cornerstone of distributed hash tables (DHTs), which employ hash values to partition a keyspace across a distributed set of nodes, then construct an overlay network of connected nodes that provide efficient node retrieval by key. Rendezvous hashing, designed in 1996, is a simpler and more general technique. It achieves the goals of consistent hashing using the very different highest random weight (HRW) algorithm.
Basic Technique
Consider the problem of load balancing where a set of objects (say, web pages or video segments) need to be assigned to a set of servers. One way of distributing objects evenly across the servers is to use a standard hash function and place object in server with id , However, if a server is added or removed (i.e., changes), the server assignment of nearly every object in the system may change. This is problematic since servers often go up or down and each such event would require nearly all objects to be reassigned and moved to new servers.


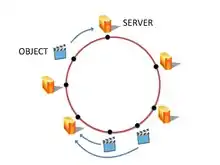
Consistent hashing was designed to avoid the problem of having to change the server assignment of every object when a server is added or removed. The main idea is to use a hash function to randomly map both the objects and the servers to a unit circle. Each object is then assigned to the next server that appears on the circle in clockwise order. This provides an even distribution of objects to servers. But, more importantly, if a server fails and is removed from the circle, only the objects that were mapped to the failed server need to be reassigned to the next server in clockwise order. Likewise, if a new server is added, it is added to the unit circle, and only the objects mapped to that server need to be reassigned. Importantly, when a server is added or removed, the vast majority of the objects maintain their prior server assignments.
Practical Extensions
A number of extensions to the basic technique are needed for effectively using consistent hashing for load balancing in practice.[2] In the basic scheme above, if a server fails, all its objects are reassigned to the next server in clockwise order, potentially doubling the load of that server. This may not be desirable. To ensure a more even re-distribution objects on server failure, each server can be hashed to multiple locations on the unit circle.[2] When a server fails, the objects assigned to each of its replicas on the unit circle will get reassigned to a different server in clockwise order, thus redistributing the objects more evenly. Another extension concerns a flash crowd situation where a single object gets "hot" and is accessed a large number of times and will have to be hosted in multiple servers. In this situation, the object may be assigned to multiple contiguous servers by traversing the unit circle in clockwise order.[2] A more complex practical consideration arises when two objects that are hashed near each other in the unit circle and both get "hot" at the same time. In this case, both objects will use the same set of contiguous servers in the unit circle. This situation can be ameliorated by each object choosing a different hash function for mapping servers to the unit circle.[2]
Comparison with Rendezvous Hashing and other alternatives
Rendezvous hashing, designed in 1996, is a simpler and more general technique, and permits fully distributed agreement on a set of options out of a possible set of options. It can in fact be shown that consistent hashing is a special case of rendezvous hashing. Because of its simplicity and generality, Rendezvous Hashing is now being used in place of Consistent Hashing in many applications.

If key values will always increase monotonically, an alternative approach using a hash table with monotonic keys may be more suitable than consistent hashing.
Complexity
| Classic hash table | Consistent hashing | |
|---|---|---|
| add a node | ||
| remove a node | ||
| add a key | ||
| remove a key |






The is an average cost for redistribution of keys and the complexity for consistent hashing comes from the fact that a binary search among nodes angles is required to find the next node on the ring.

Examples
Known examples of consistent hashing use include:
- Couchbase automated data partitioning [5]
- OpenStack's Object Storage Service Swift[6]
- Partitioning component of Amazon's storage system Dynamo[7]
- Data partitioning in Apache Cassandra[8]
- Data partitioning in Voldemort[9]
- Akka's consistent hashing router[10]
- Riak, a distributed key-value database[11]
- Gluster, a network-attached storage file system[12]
- Akamai content delivery network[13]
- Discord chat application[14]
- Maglev network load balancer[15]
- Data partitioning in Azure Cosmos DB
References
- Karger, D.; Lehman, E.; Leighton, T.; Panigrahy, R.; Levine, M.; Lewin, D. (1997). Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web. Proceedings of the Twenty-ninth Annual ACM Symposium on Theory of Computing. ACM Press New York, NY, USA. pp. 654–663. doi:10.1145/258533.258660.
- Bruce Maggs and Ramesh Sitaraman (2015). "Algorithmic nuggets in content delivery" (PDF). ACM SIGCOMM Computer Communication Review. 45 (3).
- Nygren., E.; Sitaraman R. K.; Sun, J. (2010). "The Akamai Network: A Platform for High-Performance Internet Applications" (PDF). ACM SIGOPS Operating Systems Review. 44 (3): 2–19. doi:10.1145/1842733.1842736. S2CID 207181702. Archived (PDF) from the original on September 13, 2012. Retrieved November 19, 2012.
- Karger, D.; Sherman, A.; Berkheimer, A.; Bogstad, B.; Dhanidina, R.; Iwamoto, K.; Kim, B.; Matkins, L.; Yerushalmi, Y. (1999). "Web Caching with Consistent Hashing". Computer Networks. 31 (11): 1203–1213. doi:10.1016/S1389-1286(99)00055-9. Archived from the original on 2008-07-21. Retrieved 2008-02-05.
- "What Exactly Is Membase?". Retrieved 2020-10-29.
- Holt, Greg (February 2011). "Building a Consistent Hashing Ring". openstack.org. Retrieved 2019-11-17.
- DeCandia, G.; Hastorun, D.; Jampani, M.; Kakulapati, G.; Lakshman, A.; Pilchin, A.; Sivasubramanian, S.; Vosshall, P.; Vogels, Werner (2007). "Dynamo: Amazon's Highly Available Key-Value Store" (PDF). Proceedings of the 21st ACM Symposium on Operating Systems Principles. 41 (6): 205–220. doi:10.1145/1323293.1294281. Retrieved 2018-06-07.
- Lakshman, Avinash; Malik, Prashant (2010). "Cassandra: a decentralized structured storage system". ACM SIGOPS Operating Systems Review. 44 (2): 35–40. doi:10.1145/1773912.1773922.
- "Design -- Voldemort". www.project-voldemort.com/. Archived from the original on 9 February 2015. Retrieved 9 February 2015.
Consistent hashing is a technique that avoids these problems, and we use it to compute the location of each key on the cluster.
- "Akka Routing". akka.io. Retrieved 2019-11-16.
- "Riak Concepts". Archived from the original on 2015-09-19. Retrieved 2016-12-06.
- "GlusterFS Algorithms: Distribution". gluster.org. 2012-03-01. Retrieved 2019-11-16.
- Roughgarden, Tim; Valiant, Gregory (2016-03-28). "Modern Algorithmic Toolbox" (PDF). stanford.edu. Retrieved 2019-11-17.
- Vishnevskiy, Stanislav (2017-07-06). "How Discord Scaled Elixir to 5,000,000 Concurrent Users". Retrieved 2019-11-17.
- Eisenbud, Daniel E.; Yi, Cheng; Contavalli, Carlo; Smith, Cody; Kononov, Roman; Mann-Hielscher, Eric; Cilingiroglu, Ardas; Cheyney, Bin; Shang, Wentao; Hosein, Jinnah Dylan. "Maglev: A Fast and Reliable Software Network Load Balancer" (PDF). Retrieved 2019-11-17.
External links
- Understanding Consistent hashing
- Consistent hashing by Michael Nielsen on June 3, 2009
- Consistent Hashing, Danny Lewin, and the Creation of Akamai
- Jump Consistent Hashing: A Fast, Minimal Memory, Consistent Hash Algorithm
- Rendezvous Hashing: an alternative to Consistent Hashing
- Implementations in various languages:
