Interval tree
In computer science, an interval tree is a tree data structure to hold intervals. Specifically, it allows one to efficiently find all intervals that overlap with any given interval or point. It is often used for windowing queries, for instance, to find all roads on a computerized map inside a rectangular viewport, or to find all visible elements inside a three-dimensional scene. A similar data structure is the segment tree.
The trivial solution is to visit each interval and test whether it intersects the given point or interval, which requires time, where is the number of intervals in the collection. Since a query may return all intervals, for example if the query is a large interval intersecting all intervals in the collection, this is asymptotically optimal; however, we can do better by considering output-sensitive algorithms, where the runtime is expressed in terms of , the number of intervals produced by the query. Interval trees have a query time of and an initial creation time of , while limiting memory consumption to . After creation, interval trees may be dynamic, allowing efficient insertion and deletion of an interval in time. If the endpoints of intervals are within a small integer range (e.g., in the range ), faster and in fact optimal data structures exist[1][2] with preprocessing time and query time for reporting intervals containing a given query point (see[1] for a very simple one).








Naive approach
In a simple case, the intervals do not overlap and they can be inserted into a simple binary search tree and queried in time. However, with arbitrarily overlapping intervals, there is no way to compare two intervals for insertion into the tree since orderings sorted by the beginning points or the ending points may be different. A naive approach might be to build two parallel trees, one ordered by the beginning point, and one ordered by the ending point of each interval. This allows discarding half of each tree in time, but the results must be merged, requiring time. This gives us queries in , which is no better than brute-force.

Interval trees solve this problem. This article describes two alternative designs for an interval tree, dubbed the centered interval tree and the augmented tree.
Centered interval tree
Queries require time, with being the total number of intervals and being the number of reported results. Construction requires time, and storage requires space.
Construction
Given a set of intervals on the number line, we want to construct a data structure so that we can efficiently retrieve all intervals overlapping another interval or point.
We start by taking the entire range of all the intervals and dividing it in half at (in practice, should be picked to keep the tree relatively balanced). This gives three sets of intervals, those completely to the left of which we'll call , those completely to the right of which we'll call , and those overlapping which we'll call .




The intervals in and are recursively divided in the same manner until there are no intervals left.
The intervals in that overlap the center point are stored in a separate data structure linked to the node in the interval tree. This data structure consists of two lists, one containing all the intervals sorted by their beginning points, and another containing all the intervals sorted by their ending points.
The result is a binary tree with each node storing:
- A center point
- A pointer to another node containing all intervals completely to the left of the center point
- A pointer to another node containing all intervals completely to the right of the center point
- All intervals overlapping the center point sorted by their beginning point
- All intervals overlapping the center point sorted by their ending point
Intersecting
Given the data structure constructed above, we receive queries consisting of ranges or points, and return all the ranges in the original set overlapping this input.
With a point
The task is to find all intervals in the tree that overlap a given point . The tree is walked with a similar recursive algorithm as would be used to traverse a traditional binary tree, but with extra logic to support searching the intervals overlapping the "center" point at each node.

For each tree node, is compared to , the midpoint used in node construction above. If is less than , the leftmost set of intervals, , is considered. If is greater than , the rightmost set of intervals, , is considered.
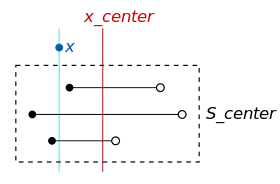
Similarly, the same technique also applies in checking a given interval. If a given interval ends at y and y is less than , all intervals in that begin before y must also overlap the given interval.
As each node is processed as we traverse the tree from the root to a leaf, the ranges in its are processed. If is less than , we know that all intervals in end after , or they could not also overlap . Therefore, we need only find those intervals in that begin before . We can consult the lists of that have already been constructed. Since we only care about the interval beginnings in this scenario, we can consult the list sorted by beginnings. Suppose we find the closest number no greater than in this list. All ranges from the beginning of the list to that found point overlap because they begin before and end after (as we know because they overlap which is larger than ). Thus, we can simply start enumerating intervals in the list until the startpoint value exceeds .
Likewise, if is greater than , we know that all intervals in must begin before , so we find those intervals that end after using the list sorted by interval endings.
If exactly matches , all intervals in can be added to the results without further processing and tree traversal can be stopped.
With an interval
For a result interval to intersect our query interval one of the following must hold:


- the start and/or end point of is in ; or
- completely encloses .
We first find all intervals with start and/or end points inside using a separately-constructed tree. In the one-dimensional case, we can use a search tree containing all the start and end points in the interval set, each with a pointer to its corresponding interval. A binary search in time for the start and end of reveals the minimum and maximum points to consider. Each point within this range references an interval that overlaps and is added to the result list. Care must be taken to avoid duplicates, since an interval might both begin and end within . This can be done using a binary flag on each interval to mark whether or not it has been added to the result set.
Finally, we must find intervals that enclose . To find these, we pick any point inside and use the algorithm above to find all intervals intersecting that point (again, being careful to remove duplicates).
Higher dimensions
The interval tree data structure can be generalized to a higher dimension with identical query and construction time and space.

First, a range tree in dimensions is constructed that allows efficient retrieval of all intervals with beginning and end points inside the query region . Once the corresponding ranges are found, the only thing that is left are those ranges that enclose the region in some dimension. To find these overlaps, interval trees are created, and one axis intersecting is queried for each. For example, in two dimensions, the bottom of the square (or any other horizontal line intersecting ) would be queried against the interval tree constructed for the horizontal axis. Likewise, the left (or any other vertical line intersecting ) would be queried against the interval tree constructed on the vertical axis.

Each interval tree also needs an addition for higher dimensions. At each node we traverse in the tree, is compared with to find overlaps. Instead of two sorted lists of points as was used in the one-dimensional case, a range tree is constructed. This allows efficient retrieval of all points in that overlap region .
Deletion
If after deleting an interval from the tree, the node containing that interval contains no more intervals, that node may be deleted from the tree. This is more complex than a normal binary tree deletion operation.
An interval may overlap the center point of several nodes in the tree. Since each node stores the intervals that overlap it, with all intervals completely to the left of its center point in the left subtree, similarly for the right subtree, it follows that each interval is stored in the node closest to the root from the set of nodes whose center point it overlaps.
Normal deletion operations in a binary tree (for the case where the node being deleted has two children) involve promoting a node further from the leaf to the position of the node being deleted (usually the leftmost child of the right subtree, or the rightmost child of the left subtree).
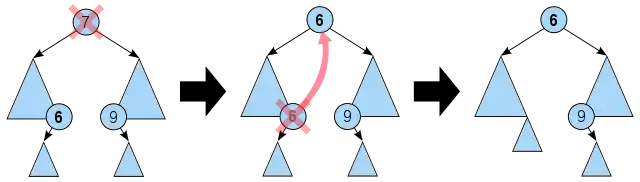
As a result of this promotion, some nodes that were above the promoted node will become its descendants; it is necessary to search these nodes for intervals that also overlap the promoted node, and move those intervals into the promoted node. As a consequence, this may result in new empty nodes, which must be deleted, following the same algorithm again.
Balancing
The same issues that affect deletion also affect rotation operations; rotation must preserve the invariant that nodes are stored as close to the root as possible.
Augmented tree
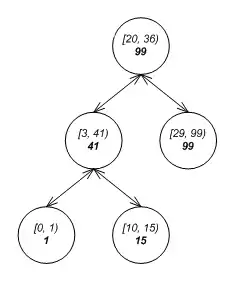
Another way to represent intervals is described in Cormen et al. (2009, Section 14.3: Interval trees, pp. 348–354).
Both insertion and deletion require time, with being the total number of intervals in the tree prior to the insertion or deletion operation.
An augmented tree can be built from a simple ordered tree, for example a binary search tree or self-balancing binary search tree, ordered by the 'low' values of the intervals. An extra annotation is then added to every node, recording the maximum upper value among all the intervals from this node down. Maintaining this attribute involves updating all ancestors of the node from the bottom up whenever a node is added or deleted. This takes only O(h) steps per node addition or removal, where h is the height of the node added or removed in the tree. If there are any tree rotations during insertion and deletion, the affected nodes may need updating as well.
Now, it is known that two intervals and overlap only when both and . When searching the trees for nodes overlapping with a given interval, you can immediately skip:




- all nodes to the right of nodes whose low value is past the end of the given interval.
- all nodes that have their maximum high value below the start of the given interval.
Membership queries
Some performance may be gained if the tree avoids unnecessary traversals. These can occur when adding intervals that already exist or removing intervals that don't exist.
A total order can be defined on the intervals by ordering them first by their lower bounds and then by their upper bounds. Then, a membership check can be performed in time, versus the time required to find duplicates if intervals overlap the interval to be inserted or removed. This solution has the advantage of not requiring any additional structures. The change is strictly algorithmic. The disadvantage is that membership queries take time.


Alternately, at the rate of memory, membership queries in expected constant time can be implemented with a hash table, updated in lockstep with the interval tree. This may not necessarily double the total memory requirement, if the intervals are stored by reference rather than by value.
Java example: Adding a new interval to the tree
The key of each node is the interval itself, hence nodes are ordered first by low value and finally by high value, and the value of each node is the end point of the interval:
public void add(Interval i) {
put(i, i.getEnd());
}
Java example: Searching a point or an interval in the tree
To search for an interval, one walks the tree, using the key (n.getKey()) and high value (n.getValue()) to omit any branches that cannot overlap the query. The simplest case is a point query:
// Search for all intervals containing "p", starting with the
// node "n" and adding matching intervals to the list "result"
public void search(IntervalNode n, Point p, List<Interval> result) {
// Don't search nodes that don't exist
if (n == null)
return;
// If p is to the right of the rightmost point of any interval
// in this node and all children, there won't be any matches.
if (p.compareTo(n.getValue()) > 0)
return;
// Search left children
search(n.getLeft(), p, result);
// Check this node
if (n.getKey().contains(p))
result.add(n.getKey());
// If p is to the left of the start of this interval,
// then it can't be in any child to the right.
if (p.compareTo(n.getKey().getStart()) < 0)
return;
// Otherwise, search right children
search(n.getRight(), p, result);
}
where
a.compareTo(b)returns a negative value if a < ba.compareTo(b)returns zero if a = ba.compareTo(b)returns a positive value if a > b
The code to search for an interval is similar, except for the check in the middle:
// Check this node
if (n.getKey().overlapsWith(i))
result.add (n.getKey());
overlapsWith() is defined as:
public boolean overlapsWith(Interval other) {
return start.compareTo(other.getEnd()) <= 0 &&
end.compareTo(other.getStart()) >= 0;
}
Higher dimensions
Augmented trees can be extended to higher dimensions by cycling through the dimensions at each level of the tree. For example, for two dimensions, the odd levels of the tree might contain ranges for the x-coordinate, while the even levels contain ranges for the y-coordinate. This approach effectively converts the data structure from an augmented binary tree to an augmented kd-tree, thus significantly complicating the balancing algorithms for insertions and deletions.
A simpler solution is to use nested interval trees. First, create a tree using the ranges for the y-coordinate. Now, for each node in the tree, add another interval tree on the x-ranges, for all elements whose y-range is the same as that node's y-range.
The advantage of this solution is that it can be extended to an arbitrary number of dimensions using the same code base.
At first, the additional cost of the nested trees might seem prohibitive, but this is usually not so. As with the non-nested solution earlier, one node is needed per x-coordinate, yielding the same number of nodes for both solutions. The only additional overhead is that of the nested tree structures, one per vertical interval. This structure is usually of negligible size, consisting only of a pointer to the root node, and possibly the number of nodes and the depth of the tree.
Medial- or length-oriented tree
A medial- or length-oriented tree is similar to an augmented tree, but symmetrical, with the binary search tree ordered by the medial points of the intervals. There is a maximum-oriented binary heap in every node, ordered by the length of the interval (or half of the length). Also we store the minimum and maximum possible value of the subtree in each node (thus the symmetry).
Overlap test
Using only start and end values of two intervals , for , the overlap test can be performed as follows:


and


This can be simplified using the sum and difference:


Which reduces the overlap test to:

Adding interval
Adding new intervals to the tree is the same as for a binary search tree using the medial value as the key. We push onto the binary heap associated with the node, and update the minimum and maximum possible values associated with all higher nodes.

Searching for all overlapping intervals
Let's use for the query interval, and for the key of a node (compared to of intervals)



Starting with root node, in each node, first we check if it is possible that our query interval overlaps with the node subtree using minimum and maximum values of node (if it is not, we don't continue for this node).
Then we calculate for intervals inside this node (not its children) to overlap with query interval (knowing ):



and perform a query on its binary heap for the 's bigger than
Then we pass through both left and right children of the node, doing the same thing.
In the worst-case, we have to scan all nodes of the binary search tree, but since binary heap query is optimum, this is acceptable (a 2- dimensional problem can not be optimum in both dimensions)
This algorithm is expected to be faster than a traditional interval tree (augmented tree) for search operations. Adding elements is a little slower in practice, though the order of growth is the same.
References
- Jens M. Schmidt. Interval Stabbing Problems in Small Integer Ranges. DOI. ISAAC'09, 2009
- Range Queries#Semigroup operators
- Mark de Berg, Marc van Kreveld, Mark Overmars, and Otfried Schwarzkopf. Computational Geometry, Second Revised Edition. Springer-Verlag 2000. Section 10.1: Interval Trees, pp. 212–217.
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2009), Introduction to Algorithms (3rd ed.), MIT Press and McGraw-Hill, ISBN 978-0-262-03384-8
- Franco P. Preparata and Michael Ian Shamos. Computational Geometry: An Introduction. Springer-Verlag, 1985
External links
- CGAL : Computational Geometry Algorithms Library in C++ contains a robust implementation of Range Trees
- Boost.Icl offers C++ implementations of interval sets and maps.
- IntervalTree (Python) - a centered interval tree with AVL balancing, compatible with tagged intervals
- Interval Tree (C#) - an augmented interval tree, with AVL balancing
- Interval Tree (Ruby) - a centered interval tree, immutable, compatible with tagged intervals
- IntervalTree (Java) - an augmented interval tree, with AVL balancing, supporting overlap, find, Collection interface, id-associated intervals
