Multispecies coalescent process
Multispecies Coalescent Process is a stochastic process model that describes the genealogical relationships for a sample of DNA sequences taken from several species.[1] [2] It represents the application of coalescent theory to the case of multiple species. The multispecies coalescent results in cases where the relationships among species for an individual gene (the gene tree) can differ from the broader history of the species (the species tree). It has important implications for the theory and practice of phylogenetics[3][4] and for understanding genome evolution.
A gene tree is a binary graph that describes the evolutionary relationships between a sample of sequences for a non-recombining locus. A species tree describes the evolutionary relationships between a set of species, assuming tree-like evolution. However, several processes can lead to discordance between gene trees and species trees. The Multispecies Coalescent model provides a framework for inferring species phylogenies while accounting for ancestral polymorphism and gene tree-species tree conflict. The process is also called the Censored Coalescent.[1]
Besides species tree estimation, the multispecies coalescent model also provides a framework for using genomic data to address a number of biological problems, such as estimation of species divergence times, population sizes of ancestral species, species delimitation, and inference of cross-species gene flow.[5][6]
Gene tree-species tree congruence
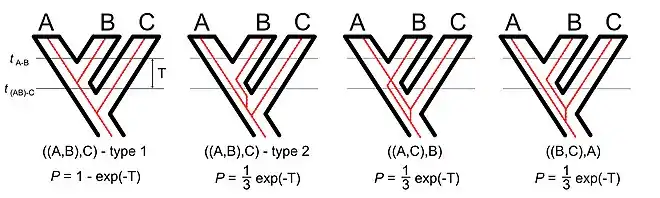
If we consider a rooted three-taxon tree, the simplest non-trivial phylogenetic tree, there are three different tree topologies[7] but four possible gene trees.[8] The existence of four distinct gene trees despite the smaller number of topologies reflects the fact that there are topologically identical gene tree that differ in their coalescent times. In the type 1 tree the alleles in species A and B coalesce after the speciation event that separated the A-B lineage from the C lineage. In the type 2 tree the alleles in species A and B coalesce before the speciation event that separated the A-B lineage from the C lineage (in other words, the type 2 tree is a deep coalescence tree). The type 1 and type 2 gene trees are both congruent with the species tree. The other two gene trees differ from the species tree; the two discordant gene trees are also deep coalescence trees.
The distribution of times to coalescence is actually continuous for all of these trees. In other words, the exact coalescent time for any two loci with the same gene tree may differ. However, it is convenient to break up the trees based on whether the coalescence occurred before or after the earliest speciation event.
Given the internal branch length in coalescent units it is straightforward to calculate the probability of each gene tree.[9] For diploid organisms the branch length in coalescent units is the number of generations between the speciation events divided by twice the effective population size. Since all three of the deep coalescence tree are equiprobable and two of those deep coalescence tree are discordant it is easy to see that the probability that a rooted three-taxon gene tree will be congruent with the species tree is:

Where the branch length in coalescent units (T) is also written in an alternative form: the number of generations (t) divided by twice the effective population size (Ne). Pamilo and Nei[9] also derived the probability of congruence for rooted trees of four and five taxa as well as a general upper bound on the probability of congruence for larger trees. Rosenberg[10] followed up with equations used for the complete set of topologies (although the large number of distinct phylogenetic trees that becomes possible as the number of taxa increases[7] makes these equations impractical unless the number of taxa is very limited).
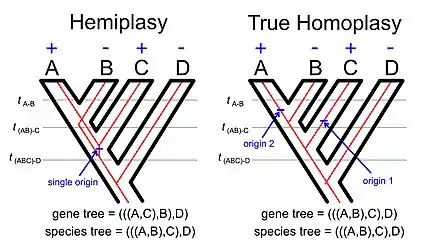
The phenomenon of hemiplasy is a natural extension of the basic idea underlying gene tree-species tree discordance. If we consider the distribution of some character that disagrees with the species tree it might reflect homoplasy (multiple independent origins of the character or a single origin followed by multiple losses) or it could reflect hemiplasy (a single origin of the trait that is associated with a gene tree that disagrees with the species tree).
The phenomenon called incomplete lineage sorting (often abbreviated ILS in the scientific literatures[11]) is linked to the phenomenon. If we examine the illustration of hemiplasy with using a rooted four-taxon tree (see image to the right) the lineage between the common ancestor of taxa A, B, and C and the common ancestor of taxa A and B must be polymorphic for the allele with the derived trait (e.g., a transposable element insertion[12]) and the allele with the ancestral trait. The concept of incomplete lineage sorting ultimately reflects on persistence of polymorphisms across one or more speciation events.
Mathematical description of the multispecies coalescent
The probability density of the gene trees under the multispecies coalescent model is discussed along with its use for parameter estimation using multi-locus sequence data.
Assumptions
In the basic multispecies coalescent model, the species phylogeny is assumed to be known. Complete isolation after species divergence, with no migration, hybridization, or introgression is also assumed. We assume no recombination so that all the sites within the locus share the same gene tree (topology and coalescent times). However, the basic model can be extended in different ways to accommodate migration or introgression, population size changes, recombination.[13] [14]
Data and model parameters
The model and implementation of this method can be applied to any species tree. As an example, the species tree of the great apes: human (H), chimpanzee (C), gorilla (G) and orangutan (O) is considered. The topology of the species tree, (((HC)G)O)), is assumed known and fixed in the analysis (Figure 1).[1] Let be the entire data set, where represent the sequence alignment at locus , with for a total of loci.





The population size of a current species is considered only if more than one individual is sampled from that species at some loci.
The parameters in the model for the example of Figure 1 include the three divergence times , and and population size parameters for humans; for chimpanzees; and , and for the three ancestral species.








The divergence times ('s) are measured by the expected number of mutations per site from the ancestral node in the species tree to the present time (Figure 1 of Rannala and Yang, 2003).

Therefore, the parameters are .

Distribution of gene genealogies
The joint distribution of is derived directly in this section.[1] Two sequences from different species can coalesce only in one populations that are ancestral to the two species. For example, sequences H and G can coalesce in populations HCG or HCGO, but not in populations H or HC. The coalescent processes in different populations are different.

For each population, the genealogy is traced backward in time, until the end of the population at time , and the number of lineages entering the population and the number of lineages leaving it are recorded. For example, and , for population H (Table 1).[1] This process is called a censored coalescent process because the coalescent process for one population may be terminated before all lineages that entered the population have coalesced. If the population consists of disconnected subtrees or lineages.






With one time unit defined as the time taken to accumulate one mutation per site, any two lineages coalesce at the rate . The waiting time until the next coalescent event, which reduces the number of lineages from to has exponential density





If , the probability that no coalescent event occurs between the last one and the end of the population at time ; i.e. during the time interval . This probability is and is 1 if .



(Note: One should recall that the probability of no events over time interval for a Poisson process with rate is . Here the coalescent rate when there are lineages is .)




In addition, to derive the probability of a particular gene tree topology in the population, if a coalescent event occurs in a sample of lineages, the probability that a particular pair of lineages coalesce is .

Multiplying these probabilities together, the joint probability distribution of the gene tree topology in the population and its coalescent times as

- .

The probability of the gene tree and coalescent times for the locus is the product of such probabilities across all the populations. Therefore, the gene genealogy of Figure 1,[1][15] we have

Likelihood-based inference
The gene genealogy at each locus is represented by the tree topology and the coalescent times . Given the species tree and the parameters on it, the probability distribution of is specified by the coalescent process as





- ,

where is the probability density for the gene tree at locus locus ,[1] and the product is because we assume that the gene trees are independent given the parameters.

The probability of data given the gene tree and coalescent times (and thus branch lengths) at the locus, , is Felsenstein's phylogenetic likelihood.[16] Due to the assumption of independent evolution across the loci,



The likelihood function or the probability of the sequence data given the parameters is then an average over the unobserved gene trees

where the integration represents summation over all possible gene tree topologies () and, for each possible topology at each locus, integration over the coalescent times .[17] This is in general intractable except for very small species trees.
In Bayesian inference, we assign a prior on the parameters, , and then the posterior is given as


where again the integration represents summation over all possible gene tree topologies () and integration over the coalescent times . In practice this integration over the gene trees is achieved through a Markov chain Monte Carlo algorithm, which samples from the joint conditional distribution of the parameters and the gene trees

The above assumes that the species tree is fixed. In species-tree estimation, the species tree () changes as well, so that the joint conditional distribution (from which the MCMC samples) is


where is the prior on species trees.

As a major departure from two-step summary methods, full-likelihood methods average over the gene trees. This means that they make use of information in the branch lengths (coalescent times) on the gene trees and accommodate their uncertainties (due to limited sequence length in the alignments) at the same time. It also explains why full-likelihood methods are computationally much more demanding than two-step summary methods.
Markov chain Monte Carlo under the multispecies coalescent
The integration or summation over the gene trees in the definition of the likelihood function above is virtually impossible to compute except for very small species trees with only two or three species.[18] Full-likelihood or full-data methods, based on calculation of the likelihood funciton on sequence alignments, have thus mostly relied on Markov chain Monte Carlo algorithms. MCMC algorithms under the multispecies coalescent model are similar to those used in Bayesian phylogenetics but are distinctly more complex, mainly due to the fact that the gene trees at multiple loci and the species tree have to be compatible: sequence divergence has to be older than species divergence. As a result, changing the species tree while the gene trees are fixed (or changing a gene tree while the species tree is fixed) leads to inefficient algorithms with poor mixing properties. Considerable efforts have been taken to design smart algorithms that change the species tree and gene trees in a coordinated manner, as in the rubber-band algorithm for changing species divergence times,[1] the coordinated NNI, SPR and NodeSlider moves.[19][20]
Consider for example the case of twe species (A and B) and two sequences at each locus, with a sequence divergence time at locus . We have for all . When we want to change the species divergence time within the constriant of the current , we may have very little room for change, as may be virtually identical to the smallest of the . The rubber-band algorithm [1] changes without consideration of the , and then modifies the deterministically in the same way that marks on a rubber band move when the rubber band is held from a fixed point pulled towards one end. In general, the rubber-band move guarantees that the ages of nodes in the gene trees are modified so that they remain compatible with the modified species divergence time.

Full likelihood methods tend to reach their limit when the data consist of a few hundred loci, even though more than 10,000 loci have been analyzed in a few published studies.[21][22]
Extensions
The basic multispecies coalescent model can be extended in a number of ways to accommodate major factors of the biological process of reproduction and drift.[13] [14] For example, incorporating continuous-time migration leads to the MSC+M (for MSC with migration) model, also known as the isolation-with-migration or IM models.[23][24] Incorporating episodic hybridization/introgression leads to the MSC with introgression (MSci)[25] or multispecies-network-coalescent (MSNC) model.[26][27]
Impact on phylogenetic estimation
The multispecies coalescent has profound implications for the theory and practice of molecular phylogenetics.[3][4] Since individual gene trees can differ from the species tree one cannot estimate the tree for a single locus and assume that the gene tree correspond the species tree. In fact, one can be virtually certain that any individual gene tree will differ from the species tree for at least some relationships when any reasonable number of taxa are considered. However, gene tree-species tree discordance has an impact on the theory and practice of species tree estimation that goes beyond the simple observation that one cannot use a single gene tree to estimate the species tree because there is a part of parameter space where the most frequent gene tree is incongruent with the species tree. This part of parameter space is called the anomaly zone[28] and any discordant gene trees that are more expected to arise more often than the gene tree. that matches the species tree are called anomalous gene trees.
The existence of the anomaly zone implies that one cannot simply estimate a large number of gene trees and assume the gene tree recovered the largest number of times is the species tree. Of course, estimating the species tree by a "democratic vote" of gene trees would only work for a limited number of taxa outside of the anomaly zone given the extremely large number of phylogenetic trees that are possible.[7] However, the existence of the anomalous gene trees also means that simple methods for combining gene trees, like the majority rule extended ("greedy") consensus method or the matrix representation with parsimony (MRP) supertree[29][30] approach, will not be consistent estimators of the species tree[31][32] (i.e., they will be misleading). Simply generating the majority-rule consensus tree for the gene trees, where groups that are present in at least 50% of gene trees are retained, will not be misleading as long as a sufficient number of gene trees are used.[31] However, this ability of the majority-rule consensus tree for a set of gene trees to avoid incorrect clades comes at the cost of having unresolved groups.
Simulations have shown that there are parts of species tree parameter space where maximum likelihood estimates of phylogeny are incorrect trees with increasing probability as the amount of data analyzed increases.[33] This is important because the "concatenation approach," where multiple sequence alignments from different loci are concatenated to form a single large supermatrix alignment that is then used for maximum likelihood (or Bayesian MCMC) analysis, is both easy to implement and commonly used in empirical studies. This represents a case of model misspecification because the concatenation approach implicitly assumes that all gene trees have the same topology.[34] Indeed, it has now been proven that analyses of data generated under the multispecies coalescent using maximum likelihood analysis of a concatenated data are not guaranteed to converge on the true species tree as the number of loci used for the analysis increases[35][36][37] (i.e., maximum likelihood concatenation is statistically inconsistent).
Software for inference under the multispecies coalescent
There are two basic approaches for phylogenetic estimation in the multispecies coalescent framework: 1) full-likelihood or full-data methods which operate on multilocus sequence alignments directly, including both maximum likelihood and Bayesian methods, and 2) summary methods, which use a summary of the original sequence data, including the two-step methods that use estimated gene trees as summary input and SVDQuartets, which use site pattern counts pooled over loci as summary input.
| Program | Description | Method | References |
|---|---|---|---|
| ASTRAL | ASTRAL (Accurate Species TRee ALgorithm) summarizes a set of gene trees using a quartet method generate an estimate of the species tree with coalescent branch lengths and support values (local posterior probabilities[38]) | Summary | Mirarab et al. (2014);[39] Zhang et al. (2018)[40] |
| ASTRID | ASTRID (Accurate Species TRees from Internode Distances) is an extension of the NJst method.[41] ASTRID/NJst is a summary species tree method that calculates the internode distances from a set of input gene trees. A distance method like neighbor joining or minimum evolution is then used to estimate the species tree from those distances. Note that ASTRID/NJst is not consistent under a model of missing data[42] | Summary | Vachaspati and Warnow (2015)[43] |
| BPP | Bayesian MCMC software package for inferring phylogeny and divergence times among populations under the multispecies coalescent process; also includes method for species delimitation | Full likelihood | Yang et al. (2015);[44] Flouri et al. (2018)[45] |
| *BEAST | Bayesian MCMC software package for inferring phylogeny and divergence times among populations under the multispecies coalescent process. Implemented as part of the BEAST software package (pronounced Star BEAST) | Full likelihood | Heled and Drummond (2010)[46] |
| MP-EST | Accepts a set of gene trees as input and generates the maximum pseudolikelihood estimate of the species tree | Summary | Liu et al. (2010)[47] |
| SVDquartets (implemented in PAUP*) | PAUP* is a general phylogenetic estimation package that implements many methods. SVDquartets is a method that has shown to be statistically consistent for data generated given the multispecies coalescent | Summary/Site-pattern method | Chifman and Kubatko (2014)[48] |
References
- Rannala B, Yang Z (August 2003). "Bayes estimation of species divergence times and ancestral population sizes using DNA sequences from multiple loci". Genetics. 164 (4): 1645–56. PMC 1462670. PMID 12930768.
- Degnan JH, Rosenberg NA (June 2009). "Gene tree discordance, phylogenetic inference and the multispecies coalescent". Trends in Ecology & Evolution. 24 (6): 332–40. doi:10.1016/j.tree.2009.01.009. PMID 19307040.
- Maddison WP (1997-09-01). "Gene Trees in Species Trees". Systematic Biology. 46 (3): 523–536. doi:10.1093/sysbio/46.3.523. ISSN 1063-5157.
- Edwards SV (January 2009). "Is a new and general theory of molecular systematics emerging?". Evolution; International Journal of Organic Evolution. 63 (1): 1–19. doi:10.1111/j.1558-5646.2008.00549.x. PMID 19146594.
- Yang, Ziheng (2014-05-15), "Simulating molecular evolution", Molecular Evolution, Oxford University Press, pp. 418–441, ISBN 978-0-19-960260-5, retrieved 2021-01-07
- Bruce Rannala, Scott V. Edwards, Adam Leaché, and Ziheng Yang (2020). The Multispecies Coalescent Model and Species Tree Inference. In Scornavacca, C., Delsuc, F., and Galtier, N., editors, Phylogenetics in the Genomic Era, chapter No. 3.3, pp. 3.3:1–3.3:21. No commercial publisher | Authors open access book. The book is freely available at https://hal.inria.fr/PGE.
- Felsenstein J (March 1978). "The Number of Evolutionary Trees". Systematic Zoology. 27 (1): 27. doi:10.2307/2412810.
- Hobolth A, Christensen OF, Mailund T, Schierup MH (February 2007). "Genomic relationships and speciation times of human, chimpanzee, and gorilla inferred from a coalescent hidden Markov model". PLoS Genetics. 3 (2): e7. doi:10.1371/journal.pgen.0030007. PMC 1802818. PMID 17319744.
- Pamilo P, Nei M (September 1988). "Relationships between gene trees and species trees". Molecular Biology and Evolution. 5 (5): 568–83. doi:10.1093/oxfordjournals.molbev.a040517. PMID 3193878.
- Rosenberg NA (March 2002). "The probability of topological concordance of gene trees and species trees". Theoretical Population Biology. 61 (2): 225–47. doi:10.1006/tpbi.2001.1568. PMID 11969392.
- Jarvis ED, Mirarab S, Aberer AJ, Li B, Houde P, Li C, et al. (December 2014). "Whole-genome analyses resolve early branches in the tree of life of modern birds". Science. 346 (6215): 1320–31. doi:10.1126/science.1253451. PMC 4405904. PMID 25504713.
- Suh A, Smeds L, Ellegren H (August 2015). Penny D (ed.). "The Dynamics of Incomplete Lineage Sorting across the Ancient Adaptive Radiation of Neoavian Birds". PLoS Biology. 13 (8): e1002224. doi:10.1371/journal.pbio.1002224. PMC 4540587. PMID 26284513.
- https://academic.oup.com/sysbio/article/67/5/786/5017269
- https://hal.archives-ouvertes.fr/hal-02535622
- Yang Z (2014). Molecular evolution : a statistical approach (First ed.). Oxford: Oxford University Press. pp. Chapter 9. ISBN 9780199602605. OCLC 869346345.
- Felsenstein J (1981). "Evolutionary trees from DNA sequences: a maximum likelihood approach". Journal of Molecular Evolution. 17 (6): 368–76. doi:10.1007/BF01734359. PMID 7288891.
- Xu B, Yang Z (December 2016). "Challenges in Species Tree Estimation Under the Multispecies Coalescent Model". Genetics. 204 (4): 1353–1368. doi:10.1534/genetics.116.190173. PMC 5161269. PMID 27927902.
- Yang, Ziheng (2002-12-01). "Likelihood and Bayes Estimation of Ancestral Population Sizes in Hominoids Using Data From Multiple Loci". Genetics. 162 (4): 1811–1823. ISSN 0016-6731. PMID 12524351.
- Yang, Z.; Rannala, B. (2014-12-01). "Unguided Species Delimitation Using DNA Sequence Data from Multiple Loci". Molecular Biology and Evolution. 31 (12): 3125–3135. doi:10.1093/molbev/msu279. ISSN 0737-4038. PMC 4245825. PMID 25274273.
- Rannala, Bruce; Yang, Ziheng (2017-01-04). "Efficient Bayesian species tree inference under the multispecies coalescent". Systematic Biology: syw119. doi:10.1093/sysbio/syw119. ISSN 1063-5157.
- Shi, Cheng-Min; Yang, Ziheng (2018-01-01). "Coalescent-Based Analyses of Genomic Sequence Data Provide a Robust Resolution of Phylogenetic Relationships among Major Groups of Gibbons". Molecular Biology and Evolution. 35 (1): 159–179. doi:10.1093/molbev/msx277. ISSN 0737-4038. PMC 5850733. PMID 29087487.
- Thawornwattana, Yuttapong; Dalquen, Daniel; Yang, Ziheng (2018-10-01). Tamura, Koichiro (ed.). "Coalescent Analysis of Phylogenomic Data Confidently Resolves the Species Relationships in the Anopheles gambiae Species Complex". Molecular Biology and Evolution. 35 (10): 2512–2527. doi:10.1093/molbev/msy158. ISSN 0737-4038. PMC 6188554. PMID 30102363.
- Hey, Jody (April 2010). "Isolation with Migration Models for More Than Two Populations". Molecular Biology and Evolution. 27 (4): 905–920. doi:10.1093/molbev/msp296. ISSN 1537-1719. PMC 2877539. PMID 19955477.
- Zhu, T.; Yang, Z. (2012-10-01). "Maximum Likelihood Implementation of an Isolation-with-Migration Model with Three Species for Testing Speciation with Gene Flow". Molecular Biology and Evolution. 29 (10): 3131–3142. doi:10.1093/molbev/mss118. ISSN 0737-4038.
- Flouri, Tomáš; Jiao, Xiyun; Rannala, Bruce; Yang, Ziheng (2020-04-01). Rosenberg, Michael (ed.). "A Bayesian Implementation of the Multispecies Coalescent Model with Introgression for Phylogenomic Analysis". Molecular Biology and Evolution. 37 (4): 1211–1223. doi:10.1093/molbev/msz296. ISSN 0737-4038. PMC 7086182. PMID 31825513.
- Wen, Dingqiao; Nakhleh, Luay (2018-05-01). Kubatko, Laura (ed.). "Coestimating Reticulate Phylogenies and Gene Trees from Multilocus Sequence Data". Systematic Biology. 67 (3): 439–457. doi:10.1093/sysbio/syx085. ISSN 1063-5157.
- Zhang, Chi; Ogilvie, Huw A; Drummond, Alexei J; Stadler, Tanja (2018-02-01). "Bayesian Inference of Species Networks from Multilocus Sequence Data". Molecular Biology and Evolution. 35 (2): 504–517. doi:10.1093/molbev/msx307. ISSN 0737-4038. PMC 5850812. PMID 29220490.
- Degnan JH, Rosenberg NA (May 2006). Wakeley J (ed.). "Discordance of species trees with their most likely gene trees". PLoS Genetics. 2 (5): e68. doi:10.1371/journal.pgen.0020068. PMC 1464820. PMID 16733550.
- Baum BR (February 1992). "Combining trees as a way of combining data sets for phylogenetic inference, and the desirability of combining gene trees". Taxon. 41 (1): 3–10. doi:10.2307/1222480. ISSN 0040-0262.
- Ragan MA (March 1992). "Phylogenetic inference based on matrix representation of trees". Molecular Phylogenetics and Evolution. 1 (1): 53–58. doi:10.1016/1055-7903(92)90035-F.
- Degnan JH, DeGiorgio M, Bryant D, Rosenberg NA (February 2009). "Properties of consensus methods for inferring species trees from gene trees". Systematic Biology. 58 (1): 35–54. doi:10.1093/sysbio/syp008. PMC 2909780. PMID 20525567.
- Wang Y, Degnan JH (2011-05-02). "Performance of Matrix Representation with Parsimony for Inferring Species from Gene Trees". Statistical Applications in Genetics and Molecular Biology. 10 (1). doi:10.2202/1544-6115.1611.
- Kubatko LS, Degnan JH (February 2007). Collins T (ed.). "Inconsistency of phylogenetic estimates from concatenated data under coalescence". Systematic Biology. 56 (1): 17–24. doi:10.1080/10635150601146041. PMID 17366134.
- Warnow T (May 2015). "Concatenation Analyses in the Presence of Incomplete Lineage Sorting". PLoS Currents. 7. doi:10.1371/currents.tol.8d41ac0f13d1abedf4c4a59f5d17b1f7. PMC 4450984. PMID 26064786.
- Roch S, Steel M (March 2015). "Likelihood-based tree reconstruction on a concatenation of aligned sequence data sets can be statistically inconsistent". Theoretical Population Biology. 100C: 56–62. doi:10.1016/j.tpb.2014.12.005. PMID 25545843.
- Mendes FK, Hahn MW (January 2018). "Why Concatenation Fails Near the Anomaly Zone". Systematic Biology. 67 (1): 158–169. doi:10.1093/sysbio/syx063. PMID 28973673.
- Roch S, Nute M, Warnow T (March 2019). Kubatko L (ed.). "Long-Branch Attraction in Species Tree Estimation: Inconsistency of Partitioned Likelihood and Topology-Based Summary Methods". Systematic Biology. 68 (2): 281–297. arXiv:1803.02800. doi:10.1093/sysbio/syy061. PMID 30247732.
- Sayyari E, Mirarab S (July 2016). "Fast Coalescent-Based Computation of Local Branch Support from Quartet Frequencies". Molecular Biology and Evolution. 33 (7): 1654–68. doi:10.1093/molbev/msw079. PMC 4915361. PMID 27189547.
- Mirarab S, Reaz R, Bayzid MS, Zimmermann T, Swenson MS, Warnow T (September 2014). "ASTRAL: genome-scale coalescent-based species tree estimation". Bioinformatics. 30 (17): i541-8. doi:10.1093/bioinformatics/btu462. PMC 4147915. PMID 25161245.
- Zhang C, Rabiee M, Sayyari E, Mirarab S (May 2018). "ASTRAL-III: polynomial time species tree reconstruction from partially resolved gene trees". BMC Bioinformatics. 19 (Suppl 6): 153. doi:10.1186/s12859-018-2129-y. PMC 5998893. PMID 29745866.
- Liu, Liang; Yu, Lili (2011-10-01). "Estimating Species Trees from Unrooted Gene Trees". Systematic Biology. 60 (5): 661–667. doi:10.1093/sysbio/syr027. ISSN 1076-836X.
- Rhodes JA, Nute MG, Warnow T. (January 2020). "NJst and ASTRID are not statistically consistent under a random model of missing data". arXiv:2001.07844 https://arxiv.org/abs/2001.07844
- Vachaspati, Pranjal; Warnow, Tandy (December 2015). "ASTRID: Accurate Species TRees from Internode Distances". BMC Genomics. 16 (S10): S3. doi:10.1186/1471-2164-16-S10-S3. ISSN 1471-2164. PMC 4602181. PMID 26449326.
- Yang Z (2015-10-01). "The BPP program for species tree estimation and species delimitation". Current Zoology. 61 (5): 854–865. doi:10.1093/czoolo/61.5.854. ISSN 2396-9814.
- Flouri T, Jiao X, Rannala B, Yang Z (October 2018). Yoder AD (ed.). "Species Tree Inference with BPP Using Genomic Sequences and the Multispecies Coalescent". Molecular Biology and Evolution. 35 (10): 2585–2593. doi:10.1093/molbev/msy147. PMC 6188564. PMID 30053098.
- Heled, J.; Drummond, A. J. (2010-03-01). "Bayesian Inference of Species Trees from Multilocus Data". Molecular Biology and Evolution. 27 (3): 570–580. doi:10.1093/molbev/msp274. ISSN 0737-4038. PMC 2822290. PMID 19906793.
- Liu L, Yu L, Edwards SV (October 2010). "A maximum pseudo-likelihood approach for estimating species trees under the coalescent model". BMC Evolutionary Biology. 10 (1): 302. doi:10.1186/1471-2148-10-302. PMC 2976751. PMID 20937096.
- Chifman J, Kubatko L (December 2014). "Quartet inference from SNP data under the coalescent model". Bioinformatics. 30 (23): 3317–24. doi:10.1093/bioinformatics/btu530. PMC 4296144. PMID 25104814.
