Object co-segmentation
In computer vision, object co-segmentation is a special case of image segmentation, which is defined as jointly segmenting semantically similar objects in multiple images or video frames.[2][3]

Challenges
It is often challenging to extract segmentation masks of a target/object from a noisy collection of images or video frames, which involves object discovery coupled with segmentation. A noisy collection implies that the object/target is present sporadically in a set of images or the object/target disappears intermittently throughout the video of interest. Early methods[4][5] typically involve mid-level representations such as object proposals.
Dynamic Markov networks-based methods

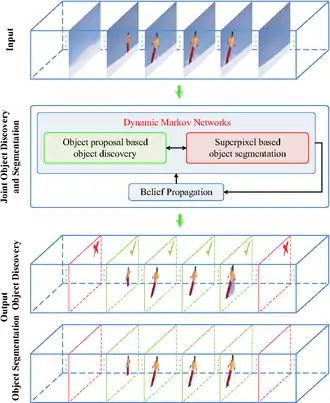
A joint object discover and co-segmentation method based on coupled dynamic Markov networks has been proposed recently,[1] which claims significant improvements in robustness against irrelevant/noisy video frames.
Unlike previous efforts which conveniently assumes the consistent presence of the target objects throughout the input video, this coupled dual dynamic Markov network based algorithm simultaneously carries out both the detection and segmentation tasks with two respective Markov networks jointly updated via belief propagation.
Specifically, the Markov network responsible for segmentation is initialized with superpixels and provides information for its Markov counterpart responsible for the object detection task. Conversely, the Markov network responsible for detection builds the object proposal graph with inputs including the spatio-temporal segmentation tubes.
Graph cut-based methods
Graph cut optimization is a popular tool in computer vision, especially in earlier image segmentation applications. As an extension of regular graph cuts, multi-level hypergraph cut is proposed[6] to account for more complex high order correspondences among video groups beyond typical pairwise correlations.
With such hypergraph extension, multiple modalities of correspondences, including low-level appearance, saliency, coherent motion and high level features such as object regions, could be seamlessly incorporated in the hyperedge computation. In addition, as an core advantage over co-occurrence based approach, hypergraph implicitly retains more complex correspondences among its vertices, with the hyperedge weights conveniently computed by eigenvalue decomposition of Laplacian matrices.
CNN/LSTM-based methods

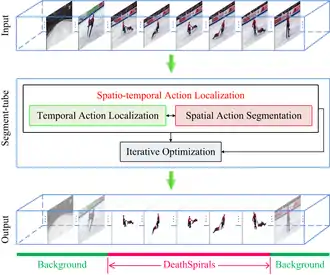
In action localization applications, object co-segmentation is also implemented as the segment-tube spatio-temporal detector.[7] Inspired by the recent spatio-temporal action localization efforts with tubelets (sequences of bounding boxes), Le et al. present a new spatio-temporal action localization detector Segment-tube, which consists of sequences of per-frame segmentation masks. This Segment-tube detector can temporally pinpoint the starting/ending frame of each action category in the presence of preceding/subsequent interference actions in untrimmed videos. Simultaneously, the Segment-tube detector produces per-frame segmentation masks instead of bounding boxes, offering superior spatial accuracy to tubelets. This is achieved by alternating iterative optimization between temporal action localization and spatial action segmentation.
The proposed segment-tube detector is illustrated in the flowchart on the right. The sample input is an untrimmed video containing all frames in a pair figure skating video, with only a portion of these frames belonging to a relevant category (e.g., the DeathSpirals). Initialized with saliency based image segmentation on individual frames, this method first performs temporal action localization step with a cascaded 3D CNN and LSTM, and pinpoints the starting frame and the ending frame of a target action with a coarse-to-fine strategy. Subsequently, the segment-tube detector refines per-frame spatial segmentation with graph cut by focusing on relevant frames identified by the temporal action localization step. The optimization alternates between the temporal action localization and spatial action segmentation in an iterative manner. Upon practical convergence, the final spatio-temporal action localization results are obtained in the format of a sequence of per-frame segmentation masks (bottom row in the flowchart) with precise starting/ending frames.
See also
References
- Liu, Ziyi; Wang, Le; Hua, Gang; Zhang, Qilin; Niu, Zhenxing; Wu, Ying; Zheng, Nanning (2018). "Joint Video Object Discovery and Segmentation by Coupled Dynamic Markov Networks" (PDF). IEEE Transactions on Image Processing. 27 (12): 5840–5853. Bibcode:2018ITIP...27.5840L. doi:10.1109/tip.2018.2859622. ISSN 1057-7149. PMID 30059300. S2CID 51867241.
- Vicente, Sara; Rother, Carsten; Kolmogorov, Vladimir (2011). Object cosegmentation. IEEE. doi:10.1109/cvpr.2011.5995530. ISBN 978-1-4577-0394-2.
- Chen, Ding-Jie; Chen, Hwann-Tzong; Chang, Long-Wen (2012). Video object cosegmentation. New York, New York, USA: ACM Press. doi:10.1145/2393347.2396317. ISBN 978-1-4503-1089-5.
- Lee, Yong Jae; Kim, Jaechul; Grauman, Kristen (2011). Key-segments for video object segmentation. IEEE. doi:10.1109/iccv.2011.6126471. ISBN 978-1-4577-1102-2.
- Ma, Tianyang; Latecki, Longin Jan. Maximum weight cliques with mutex constraints for video object segmentation. IEEE CVPR 2012. doi:10.1109/CVPR.2012.6247735.
- Wang, Le; Lv, Xin; Zhang, Qilin; Niu, Zhenxing; Zheng, Nanning; Hua, Gang (2020). "Object Cosegmentation in Noisy Videos with Multilevel Hypergraph" (PDF). IEEE Transactions on Multimedia. IEEE: 1. doi:10.1109/tmm.2020.2995266. ISSN 1520-9210.
- Wang, Le; Duan, Xuhuan; Zhang, Qilin; Niu, Zhenxing; Hua, Gang; Zheng, Nanning (2018-05-22). "Segment-Tube: Spatio-Temporal Action Localization in Untrimmed Videos with Per-Frame Segmentation" (PDF). Sensors. MDPI AG. 18 (5): 1657. doi:10.3390/s18051657. ISSN 1424-8220. PMC 5982167. PMID 29789447.

