Object detection
Object detection is a computer technology related to computer vision and image processing that deals with detecting instances of semantic objects of a certain class (such as humans, buildings, or cars) in digital images and videos.[1] Well-researched domains of object detection include face detection and pedestrian detection. Object detection has applications in many areas of computer vision, including image retrieval and video surveillance.
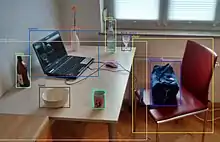
Uses
It is widely used in computer vision tasks such as image annotation,[2] activity recognition,[3] face detection, face recognition, video object co-segmentation. It is also used in tracking objects, for example tracking a ball during a football match, tracking movement of a cricket bat, or tracking a person in a video.
Concept
Every object class has its own special features that helps in classifying the class – for example all circles are round. Object class detection uses these special features. For example, when looking for circles, objects that are at a particular distance from a point (i.e. the center) are sought. Similarly, when looking for squares, objects that are perpendicular at corners and have equal side lengths are needed. A similar approach is used for face identification where eyes, nose, and lips can be found and features like skin color and distance between eyes can be found.
Methods

Methods for object detection generally fall into either machine learning-based approaches or deep learning-based approaches. For Machine Learning approaches, it becomes necessary to first define features using one of the methods below, then using a technique such as support vector machine (SVM) to do the classification. On the other hand, deep learning techniques are able to do end-to-end object detection without specifically defining features, and are typically based on convolutional neural networks (CNN).
- Machine learning approaches:
- Deep learning approaches:
See also
References
- Dasiopoulou, Stamatia, et al. "Knowledge-assisted semantic video object detection." IEEE Transactions on Circuits and Systems for Video Technology 15.10 (2005): 1210–1224.
- Ling Guan; Yifeng He; Sun-Yuan Kung (1 March 2012). Multimedia Image and Video Processing. CRC Press. pp. 331–. ISBN 978-1-4398-3087-1.
- Wu, Jianxin, et al. "A scalable approach to activity recognition based on object use." 2007 IEEE 11th international conference on computer vision. IEEE, 2007.
- Bochkovskiy, Alexey (2020). "Yolov4: Optimal Speed and Accuracy of Object Detection". arXiv:2004.10934 [cs.CV].
- Dalal, Navneet (2005). "Histograms of oriented gradients for human detection" (PDF). Computer Vision and Pattern Recognition. 1.
- Ross, Girshick (2014). "Rich feature hierarchies for accurate object detection and semantic segmentation" (PDF). Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE: 580–587. arXiv:1311.2524. doi:10.1109/CVPR.2014.81. ISBN 978-1-4799-5118-5. S2CID 215827080.
- Girschick, Ross (2015). "Fast R-CNN" (PDF). Proceedings of the IEEE International Conference on Computer Vision: 1440–1448. arXiv:1504.08083. Bibcode:2015arXiv150408083G.
- Shaoqing, Ren (2015). "Faster R-CNN". Advances in Neural Information Processing Systems. arXiv:1506.01497.
- Pang, Jiangmiao; Chen, Kai; Shi, Jianping; Feng, Huajun; Ouyang, Wanli; Lin, Dahua (2019-04-04). "Libra R-CNN: Towards Balanced Learning for Object Detection". arXiv:1904.02701v1 [cs.CV].
- Liu, Wei (October 2016). "SSD: Single shot multibox detector". Computer Vision – ECCV 2016. European Conference on Computer Vision. Lecture Notes in Computer Science. 9905. pp. 21–37. arXiv:1512.02325. doi:10.1007/978-3-319-46448-0_2. ISBN 978-3-319-46447-3. S2CID 2141740.
- Redmon, Joseph (2016). "You only look once: Unified, real-time object detection". Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. arXiv:1506.02640. Bibcode:2015arXiv150602640R.
- Redmon, Joseph (2017). "YOLO9000: better, faster, stronger". arXiv:1612.08242 [cs.CV].
- Redmon, Joseph (2018). "Yolov3: An incremental improvement". arXiv:1804.02767 [cs.CV].
- Zhang, Shifeng (2018). "Single-Shot Refinement Neural Network for Object Detection". Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition: 4203–4212. arXiv:1711.06897. Bibcode:2017arXiv171106897Z.
- Lin, Tsung-Yi (2020). "Focal Loss for Dense Object Detection". IEEE Transactions on Pattern Analysis and Machine Intelligence. 42 (2): 318–327. arXiv:1708.02002. Bibcode:2017arXiv170802002L. doi:10.1109/TPAMI.2018.2858826. PMID 30040631. S2CID 47252984.
- Zhu, Xizhou (2018). "Deformable ConvNets v2: More Deformable, Better Results". arXiv:1811.11168 [cs.CV].
- Dai, Jifeng (2017). "Deformable Convolutional Networks". arXiv:1703.06211 [cs.CV].
- "Object Class Detection". Vision.eecs.ucf.edu. Archived from the original on 2013-07-14. Retrieved 2013-10-09.
- "ETHZ – Computer Vision Lab: Publications". Vision.ee.ethz.ch. Archived from the original on 2013-06-03. Retrieved 2013-10-09.
