Source–filter model
The source–filter model represents speech as a combination of a sound source, such as the vocal cords, and a linear acoustic filter, the vocal tract. While only an approximation, the model is widely used in a number of applications such as speech synthesis and speech analysis because of its relative simplicity. It is also related to linear prediction. The development of the model is due, in large part, to the early work of Gunnar Fant, although others, notably Ken Stevens, have also contributed substantially to the models underlying acoustic analysis of speech and speech synthesis.[1] Fant built off the work of Tsutomu Chiba and Masato Kajiyama, who first showed the relationship between a vowel's acoustic properties and the shape of the vocal tract.[1]
| Part of a series on | ||||||
| Phonetics | ||||||
|---|---|---|---|---|---|---|
| Part of the Linguistics Series | ||||||
| Subdisciplines | ||||||
| Articulation | ||||||
|
||||||
| Acoustics | ||||||
|
||||||
| Perception | ||||||
|
||||||
| Linguistics portal | ||||||
An important assumption that is often made in the use of the source–filter model is the independence of source and filter.[1] In such cases, the model should more accurately be referred to as the "independent source–filter model".
History
In 1942, Chiba and Kajiyama published their research on vowel acoustics and the vocal tract in their book, The Vowel: Its nature and structure. By creating models of the vocal tract using X-ray photography, they were able to predict the formant frequencies of different vowels, establishing a relationship between the two. Gunnar Fant, a pioneering speech scientist, used Chiba and Kajiyama's research involving X-ray photography of the vocal tract to interpret his own data of Russian speech sounds in Acoustic Theory of Speech Production, which established the source–filter model.[2]
Applications
To varying degrees, different phonemes can be distinguished by the properties of their source(s) and their spectral shape. Voiced sounds (e.g., vowels) have at least one source due to mostly periodic glottal excitation, which can be approximated by an impulse train in the time domain and by harmonics in the frequency domain, and a filter that depends on, for example, tongue position and lip protrusion.[3] On the other hand, fricatives, such as [s] and [f], have at least one source due to turbulent noise produced at a constriction in the oral cavity or pharynx. So-called voiced fricatives, such as [z] and [v], have two sources - one at the glottis and one at the supra-glottal constriction.
Speech synthesis
In implementation of the source–filter model of speech production, the sound source, or excitation signal, is often modelled as a periodic impulse train, for voiced speech, or white noise for unvoiced speech. The vocal tract filter is, in the simplest case, approximated by an all-pole filter, where the coefficients are obtained by performing linear prediction to minimize the mean-squared error in the speech signal to be reproduced. Convolution of the excitation signal with the filter response then produces the synthesised speech.
Modeling human speech production
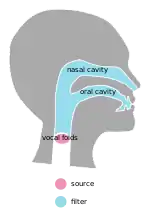
In human speech production, the sound source is the vocal folds, which can produce a periodic sound when constricted or an aperiodic (white noise) sound when relaxed.[4] The filter is the rest of the vocal tract, which can change shape through manipulation of the pharynx, mouth, and nasal cavity.[3] Fant roughly compares the source and filter to phonation and articulation, respectively. The source produces a number of harmonics of varying amplitudes, which travel through the vocal tract and are either amplified or attenuated to produce a speech sound.[4]
See also
References
- Arai, Takayuki (2004). "History of Chiba and Kajiyama and their influence in modern speech science". From Sound to Sense: 50+ Years of Discoveries in Speech Communication (PDF). pp. 115–120.
- Fant, Gunnar. "T. Chiba and M. Kajiyama, Pioneers in Speech Acoustics". Journal of the Phonetic Society of Japan. 5 (2). doi:10.24467/onseikenkyu.5.2_4. Retrieved 3 July 2020.
- Fant, Gunnar (1970). Acoustic Theory of Speech Production with Calculations Based on X-ray Studies of Russian Articulations. De Gruyter.
- Zsiga, Elizabeth C. (2012). The Sounds of Language: An Introduction to Phonetics and Phonology. John Wiley & Sons. ISBN 978-1-118-34060-8.
- Chiba, T.; Kajiyama, M. (1942). The Vowel: Its Nature and Structure. Tokyo: Tokyo-Kaiseikan Pub. Co., Ltd.
(there were reprinted edition in 1952, and Japanese translated edition in 2003 as ISBN 4-00-002107-9) - Stevens, K. N. (2001). "The Chiba and Kajiyama book as a precursor to the acoustic theory of speech production". Journal of Phonetic Society of Japan. 5 (2): 6–7.
- Stevens, K. N. (1998). Acoustic Phonetics. Cambridge, MA: MIT Press. ISBN 978-0-262-19404-4. (hardcover in 1999) / (paperback in 2000).