Approximate Bayesian computation
Approximate Bayesian computation (ABC) constitutes a class of computational methods rooted in Bayesian statistics that can be used to estimate the posterior distributions of model parameters.
In all model-based statistical inference, the likelihood function is of central importance, since it expresses the probability of the observed data under a particular statistical model, and thus quantifies the support data lend to particular values of parameters and to choices among different models. For simple models, an analytical formula for the likelihood function can typically be derived. However, for more complex models, an analytical formula might be elusive or the likelihood function might be computationally very costly to evaluate.
ABC methods bypass the evaluation of the likelihood function. In this way, ABC methods widen the realm of models for which statistical inference can be considered. ABC methods are mathematically well-founded, but they inevitably make assumptions and approximations whose impact needs to be carefully assessed. Furthermore, the wider application domain of ABC exacerbates the challenges of parameter estimation and model selection.
ABC has rapidly gained popularity over the last years and in particular for the analysis of complex problems arising in biological sciences, e.g. in population genetics, ecology, epidemiology, and systems biology.
History
The first ABC-related ideas date back to the 1980s. Donald Rubin, when discussing the interpretation of Bayesian statements in 1984,[1] described a hypothetical sampling mechanism that yields a sample from the posterior distribution. This scheme was more of a conceptual thought experiment to demonstrate what type of manipulations are done when inferring the posterior distributions of parameters. The description of the sampling mechanism coincides exactly with that of the ABC-rejection scheme, and this article can be considered to be the first to describe approximate Bayesian computation. However, a two-stage quincunx was constructed by Francis Galton in the late 1800s that can be seen as a physical implementation of an ABC-rejection scheme for a single unknown (parameter) and a single observation.[2] Another prescient point was made by Rubin when he argued that in Bayesian inference, applied statisticians should not settle for analytically tractable models only, but instead consider computational methods that allow them to estimate the posterior distribution of interest. This way, a wider range of models can be considered. These arguments are particularly relevant in the context of ABC.
In 1984, Peter Diggle and Richard Gratton[3] suggested using a systematic simulation scheme to approximate the likelihood function in situations where its analytic form is intractable. Their method was based on defining a grid in the parameter space and using it to approximate the likelihood by running several simulations for each grid point. The approximation was then improved by applying smoothing techniques to the outcomes of the simulations. While the idea of using simulation for hypothesis testing was not new,[4][5] Diggle and Gratton seemingly introduced the first procedure using simulation to do statistical inference under a circumstance where the likelihood is intractable.
Although Diggle and Gratton's approach had opened a new frontier, their method was not yet exactly identical to what is now known as ABC, as it aimed at approximating the likelihood rather than the posterior distribution. An article of Simon Tavaré et al.[6] was first to propose an ABC algorithm for posterior inference. In their seminal work, inference about the genealogy of DNA sequence data was considered, and in particular the problem of deciding the posterior distribution of the time to the most recent common ancestor of the sampled individuals. Such inference is analytically intractable for many demographic models, but the authors presented ways of simulating coalescent trees under the putative models. A sample from the posterior of model parameters was obtained by accepting/rejecting proposals based on comparing the number of segregating sites in the synthetic and real data. This work was followed by an applied study on modeling the variation in human Y chromosome by Jonathan K. Pritchard et al.[7] using the ABC method. Finally, the term approximate Bayesian computation was established by Mark Beaumont et al.,[8] extending further the ABC methodology and discussing the suitability of the ABC-approach more specifically for problems in population genetics. Since then, ABC has spread to applications outside population genetics, such as systems biology, epidemiology, and phylogeography.
Method
Motivation
A common incarnation of Bayes’ theorem relates the conditional probability (or density) of a particular parameter value given data to the probability of given by the rule


- ,

where denotes the posterior, the likelihood, the prior, and the evidence (also referred to as the marginal likelihood or the prior predictive probability of the data). Note that the denominator is normalizing the total probability of the posterior density to one and can be calculated that way.




The prior represents beliefs or knowledge (such as f.e. physical constraints) about before is available. Since the prior narrows down uncertainity, the posterior estimates have less variance, but might be biased. For convenience the prior is often specified by choosing a particular distribution among a set of well-known and tractable families of distributions, such that both the evaluation of prior probabilities and random generation of values of are relatively straightforward. For certain kinds of models, it is more pragmatic to specify the prior using a factorization of the joint distribution of all the elements of in terms of a sequence of their conditional distributions. If one is only interested in the relative posterior plausibilities of different values of , the evidence can be ignored, as it constitutes a normalising constant, which cancels for any ratio of posterior probabilities. It remains, however, necessary to evaluate the likelihood and the prior . For numerous applications, it is computationally expensive, or even completely infeasible, to evaluate the likelihood,[9] which motivates the use of ABC to circumvent this issue.
The ABC rejection algorithm
All ABC-based methods approximate the likelihood function by simulations, the outcomes of which are compared with the observed data.[10][11][12] More specifically, with the ABC rejection algorithm—the most basic form of ABC—a set of parameter points is first sampled from the prior distribution. Given a sampled parameter point , a data set is then simulated under the statistical model specified by . If the generated is too different from the observed data , the sampled parameter value is discarded. In precise terms, is accepted with tolerance if:




- ,

where the distance measure determines the level of discrepancy between and based on a given metric (e.g. Euclidean distance). A strictly positive tolerance is usually necessary, since the probability that the simulation outcome coincides exactly with the data (event ) is negligible for all but trivial applications of ABC, which would in practice lead to rejection of nearly all sampled parameter points. The outcome of the ABC rejection algorithm is a sample of parameter values approximately distributed according to the desired posterior distribution, and, crucially, obtained without the need to explicitly evaluate the likelihood function.


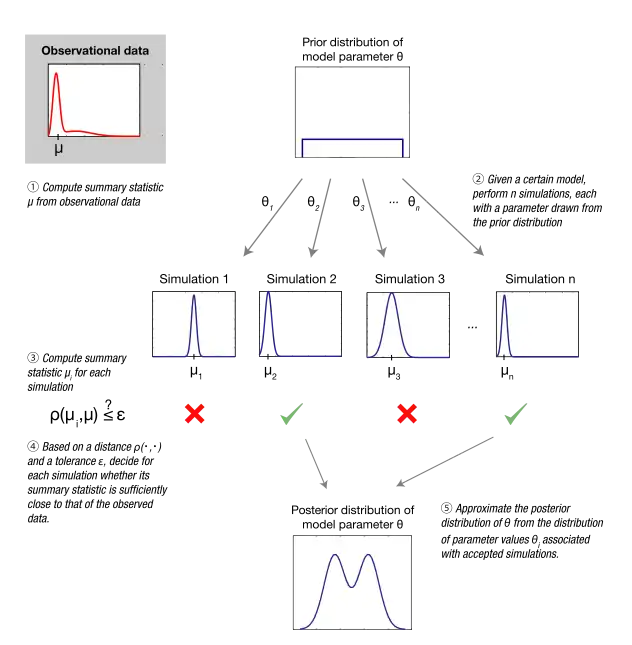
Summary statistics
The probability of generating a data set with a small distance to typically decreases as the dimensionality of the data increases. This leads to a substantial decrease in the computational efficiency of the above basic ABC rejection algorithm. A common approach to lessen this problem is to replace with a set of lower-dimensional summary statistics , which are selected to capture the relevant information in . The acceptance criterion in ABC rejection algorithm becomes:

- .

If the summary statistics are sufficient with respect to the model parameters , the efficiency increase obtained in this way does not introduce any error.[13] Indeed, by definition, sufficiency implies that all information in about is captured by .
As elaborated below, it is typically impossible, outside the exponential family of distributions, to identify a finite-dimensional set of sufficient statistics. Nevertheless, informative but possibly insufficient summary statistics are often used in applications where inference is performed with ABC methods.
Example
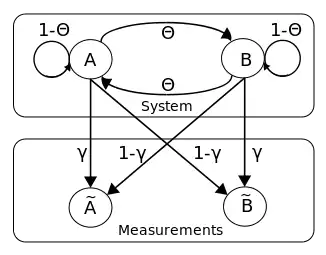
An illustrative example is a bistable system that can be characterized by a hidden Markov model (HMM) subject to measurement noise. Such models are employed for many biological systems: They have, for example, been used in development, cell signaling, activation/deactivation, logical processing and non-equilibrium thermodynamics. For instance, the behavior of the Sonic hedgehog (Shh) transcription factor in Drosophila melanogaster can be modeled with an HMM.[14] The (biological) dynamical model consists of two states: A and B. If the probability of a transition from one state to the other is defined as in both directions, then the probability to remain in the same state at each time step is . The probability to measure the state correctly is (and conversely, the probability of an incorrect measurement is ).



Due to the conditional dependencies between states at different time points, calculation of the likelihood of time series data is somewhat tedious, which illustrates the motivation to use ABC. A computational issue for basic ABC is the large dimensionality of the data in an application like this. The dimensionality can be reduced using the summary statistic , which is the frequency of switches between the two states. The absolute difference is used as a distance measure with tolerance . The posterior inference about the parameter can be done following the five steps presented in.



Step 1: Assume that the observed data form the state sequence AAAABAABBAAAAAABAAAA, which is generated using and . The associated summary statistic—the number of switches between the states in the experimental data—is .



Step 2: Assuming nothing is known about , a uniform prior in the interval is employed. The parameter is assumed to be known and fixed to the data-generating value , but it could in general also be estimated from the observations. A total of parameter points are drawn from the prior, and the model is simulated for each of the parameter points , which results in sequences of simulated data. In this example, , with each drawn parameter and simulated dataset recorded in Table 1, columns 2-3. In practice, would need to be much larger to obtain an appropriate approximation.




| i | Simulated datasets (step 2) | Summary statistic (step 3) |
Distance (step 4) |
Outcome (step 4) | |
|---|---|---|---|---|---|
| 1 | 0.08 | AABAAAABAABAAABAAAAA | 8 | 2 | accepted |
| 2 | 0.68 | AABBABABAAABBABABBAB | 13 | 7 | rejected |
| 3 | 0.87 | BBBABBABBBBABABBBBBA | 9 | 3 | rejected |
| 4 | 0.43 | AABAAAAABBABBBBBBBBA | 6 | 0 | accepted |
| 5 | 0.53 | ABBBBBAABBABBABAABBB | 9 | 3 | rejected |



Step 3: The summary statistic is computed for each sequence of simulated data .

Step 4: The distance between the observed and simulated transition frequencies is computed for all parameter points. Parameter points for which the distance is smaller than or equal to are accepted as approximate samples from the posterior.


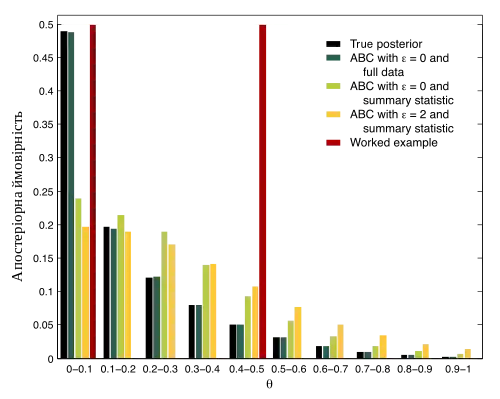


Step 5: The posterior distribution is approximated with the accepted parameter points. The posterior distribution should have a non-negligible probability for parameter values in a region around the true value of in the system if the data are sufficiently informative. In this example, the posterior probability mass is evenly split between the values 0.08 and 0.43.
The posterior probabilities are obtained via ABC with large by utilizing the summary statistic (with and ) and the full data sequence (with ). These are compared with the true posterior, which can be computed exactly and efficiently using the Viterbi algorithm. The summary statistic utilized in this example is not sufficient, as the deviation from the theoretical posterior is significant even under the stringent requirement of . A much longer observed data sequence would be needed to obtain a posterior concentrated around , the true value of .
This example application of ABC uses simplifications for illustrative purposes. More realistic applications of ABC are available in a growing number of peer-reviewed articles.[10][11][12][15]
Model comparison with ABC
Outside of parameter estimation, the ABC framework can be used to compute the posterior probabilities of different candidate models.[16][17][18] In such applications, one possibility is to use rejection sampling in a hierarchical manner. First, a model is sampled from the prior distribution for the models. Then, parameters are sampled from the prior distribution assigned to that model. Finally, a simulation is performed as in single-model ABC. The relative acceptance frequencies for the different models now approximate the posterior distribution for these models. Again, computational improvements for ABC in the space of models have been proposed, such as constructing a particle filter in the joint space of models and parameters.[18]
Once the posterior probabilities of the models have been estimated, one can make full use of the techniques of Bayesian model comparison. For instance, to compare the relative plausibilities of two models and , one can compute their posterior ratio, which is related to the Bayes factor :



- .

If the model priors are equal—that is, —the Bayes factor equals the posterior ratio.

In practice, as discussed below, these measures can be highly sensitive to the choice of parameter prior distributions and summary statistics, and thus conclusions of model comparison should be drawn with caution.
Pitfalls and remedies
| Error source | Potential issue | Solution | Subsection |
|---|---|---|---|
| Nonzero tolerance | The inexactness introduces bias into the computed posterior distribution. | Theoretical/practical studies of the sensitivity of the posterior distribution to the tolerance. Noisy ABC. | #Approximation of the posterior |
| Insufficient summary statistics | The information loss causes inflated credible intervals. | Automatic selection/semi-automatic identification of sufficient statistics. Model validation checks (e.g., Templeton 2009[19]). | #Choice and sufficiency of summary statistics |
| Small number of models/incorrectly specified models | The investigated models are not representative/lack predictive power. | Careful selection of models. Evaluation of the predictive power. | #Small number of models |
| Priors and parameter ranges | Conclusions may be sensitive to the choice of priors. Model choice may be meaningless. | Check sensitivity of Bayes factors to the choice of priors. Some theoretical results regarding choice of priors are available. Use alternative methods for model validation. | #Prior distribution and parameter ranges |
| Curse of dimensionality | Low parameter acceptance rates. Model errors cannot be distinguished from an insufficient exploration of the parameter space. Risk of overfitting. | Methods for model reduction if applicable. Methods to speed up the parameter exploration. Quality controls to detect overfitting. | #Curse of dimensionality |
| Model ranking with summary statistics | The computation of Bayes factors on summary statistics may not be related to the Bayes factors on the original data, which may therefore render the results meaningless. | Only use summary statistics that fulfill the necessary and sufficient conditions to produce a consistent Bayesian model choice. Use alternative methods for model validation. | #Bayes factor with ABC and summary statistics |
| Implementation | Low protection to common assumptions in the simulation and the inference process. | Sanity checks of results. Standardization of software. | #Indispensable quality controls |
As for all statistical methods, a number of assumptions and approximations are inherently required for the application of ABC-based methods to real modeling problems. For example, setting the tolerance parameter to zero ensures an exact result, but typically makes computations prohibitively expensive. Thus, values of larger than zero are used in practice, which introduces a bias. Likewise, sufficient statistics are typically not available and instead, other summary statistics are used, which introduces an additional bias due to the loss of information. Additional sources of bias- for example, in the context of model selection—may be more subtle.[13][20]
At the same time, some of the criticisms that have been directed at the ABC methods, in particular within the field of phylogeography,[19][21][22] are not specific to ABC and apply to all Bayesian methods or even all statistical methods (e.g., the choice of prior distribution and parameter ranges).[10][23] However, because of the ability of ABC-methods to handle much more complex models, some of these general pitfalls are of particular relevance in the context of ABC analyses.
This section discusses these potential risks and reviews possible ways to address them.
Approximation of the posterior
A non-negligible comes with the price that one samples from instead of the true posterior . With a sufficiently small tolerance, and a sensible distance measure, the resulting distribution should often approximate the actual target distribution reasonably well. On the other hand, a tolerance that is large enough that every point in the parameter space becomes accepted will yield a replica of the prior distribution. There are empirical studies of the difference between and as a function of ,[24] and theoretical results for an upper -dependent bound for the error in parameter estimates.[25] The accuracy of the posterior (defined as the expected quadratic loss) delivered by ABC as a function of has also been investigated.[26] However, the convergence of the distributions when approaches zero, and how it depends on the distance measure used, is an important topic that has yet to be investigated in greater detail. In particular, it remains difficult to disentangle errors introduced by this approximation from errors due to model mis-specification.[10]

As an attempt to correct some of the error due to a non-zero , the usage of local linear weighted regression with ABC to reduce the variance of the posterior estimates has been suggested.[8] The method assigns weights to the parameters according to how well simulated summaries adhere to the observed ones and performs linear regression between the summaries and the weighted parameters in the vicinity of observed summaries. The obtained regression coefficients are used to correct sampled parameters in the direction of observed summaries. An improvement was suggested in the form of nonlinear regression using a feed-forward neural network model.[27] However, it has been shown that the posterior distributions obtained with these approaches are not always consistent with the prior distribution, which did lead to a reformulation of the regression adjustment that respects the prior distribution.[28]
Finally, statistical inference using ABC with a non-zero tolerance is not inherently flawed: under the assumption of measurement errors, the optimal can in fact be shown to be not zero.[26][29] Indeed, the bias caused by a non-zero tolerance can be characterized and compensated by introducing a specific form of noise to the summary statistics. Asymptotic consistency for such “noisy ABC”, has been established, together with formulas for the asymptotic variance of the parameter estimates for a fixed tolerance.[26]
Choice and sufficiency of summary statistics
Summary statistics may be used to increase the acceptance rate of ABC for high-dimensional data. Low-dimensional sufficient statistics are optimal for this purpose, as they capture all relevant information present in the data in the simplest possible form.[12] However, low-dimensional sufficient statistics are typically unattainable for statistical models where ABC-based inference is most relevant, and consequently, some heuristic is usually necessary to identify useful low-dimensional summary statistics. The use of a set of poorly chosen summary statistics will often lead to inflated credible intervals due to the implied loss of information,[12] which can also bias the discrimination between models. A review of methods for choosing summary statistics is available,[30] which may provide valuable guidance in practice.
One approach to capture most of the information present in data would be to use many statistics, but the accuracy and stability of ABC appears to decrease rapidly with an increasing numbers of summary statistics.[10][12] Instead, a better strategy is to focus on the relevant statistics only—relevancy depending on the whole inference problem, on the model used, and on the data at hand.[31]
An algorithm has been proposed for identifying a representative subset of summary statistics, by iteratively assessing whether an additional statistic introduces a meaningful modification of the posterior.[32] One of the challenges here is that a large ABC approximation error may heavily influence the conclusions about the usefulness of a statistic at any stage of the procedure. Another method[31] decomposes into two main steps. First, a reference approximation of the posterior is constructed by minimizing the entropy. Sets of candidate summaries are then evaluated by comparing the ABC-approximated posteriors with the reference posterior.
With both of these strategies, a subset of statistics is selected from a large set of candidate statistics. Instead, the partial least squares regression approach uses information from all the candidate statistics, each being weighted appropriately.[33] Recently, a method for constructing summaries in a semi-automatic manner has attained a considerable interest.[26] This method is based on the observation that the optimal choice of summary statistics, when minimizing the quadratic loss of the parameter point estimates, can be obtained through the posterior mean of the parameters, which is approximated by performing a linear regression based on the simulated data.
Methods for the identification of summary statistics that could also simultaneously assess the influence on the approximation of the posterior would be of substantial value.[34] This is because the choice of summary statistics and the choice of tolerance constitute two sources of error in the resulting posterior distribution. These errors may corrupt the ranking of models and may also lead to incorrect model predictions. Indeed, none of the methods above assesses the choice of summaries for the purpose of model selection.
Bayes factor with ABC and summary statistics
It has been shown that the combination of insufficient summary statistics and ABC for model selection can be problematic.[13][20] Indeed, if one lets the Bayes factor based on the summary statistic be denoted by , the relation between and takes the form:[13]

- .

Thus, a summary statistic is sufficient for comparing two models and if and only if:
- ,

which results in that . It is also clear from the equation above that there might be a huge difference between and if the condition is not satisfied, as can be demonstrated by toy examples.[13][17][20] Crucially, it was shown that sufficiency for or alone, or for both models, does not guarantee sufficiency for ranking the models.[13] However, it was also shown that any sufficient summary statistic for a model in which both and are nested is valid for ranking the nested models.[13]

The computation of Bayes factors on may therefore be misleading for model selection purposes, unless the ratio between the Bayes factors on and would be available, or at least could be approximated reasonably well. Alternatively, necessary and sufficient conditions on summary statistics for a consistent Bayesian model choice have recently been derived,[35] which can provide useful guidance.
However, this issue is only relevant for model selection when the dimension of the data has been reduced. ABC-based inference, in which the actual data sets are directly compared—as is the case for some systems biology applications (e.g., see [36])—circumvents this problem.
Indispensable quality controls
As the above discussion makes clear, any ABC analysis requires choices and trade-offs that can have a considerable impact on its outcomes. Specifically, the choice of competing models/hypotheses, the number of simulations, the choice of summary statistics, or the acceptance threshold cannot currently be based on general rules, but the effect of these choices should be evaluated and tested in each study.[11]
A number of heuristic approaches to the quality control of ABC have been proposed, such as the quantification of the fraction of parameter variance explained by the summary statistics.[11] A common class of methods aims at assessing whether or not the inference yields valid results, regardless of the actually observed data. For instance, given a set of parameter values, which are typically drawn from the prior or the posterior distributions for a model, one can generate a large number of artificial datasets. In this way, the quality and robustness of ABC inference can be assessed in a controlled setting, by gauging how well the chosen ABC inference method recovers the true parameter values, and also models if multiple structurally different models are considered simultaneously.
Another class of methods assesses whether the inference was successful in light of the given observed data, for example, by comparing the posterior predictive distribution of summary statistics to the summary statistics observed.[11] Beyond that, cross-validation techniques[37] and predictive checks[38][39] represent promising future strategies to evaluate the stability and out-of-sample predictive validity of ABC inferences. This is particularly important when modeling large data sets, because then the posterior support of a particular model can appear overwhelmingly conclusive, even if all proposed models in fact are poor representations of the stochastic system underlying the observation data. Out-of-sample predictive checks can reveal potential systematic biases within a model and provide clues on to how to improve its structure or parametrization.
Fundamentally novel approaches for model choice that incorporate quality control as an integral step in the process have recently been proposed. ABC allows, by construction, estimation of the discrepancies between the observed data and the model predictions, with respect to a comprehensive set of statistics. These statistics are not necessarily the same as those used in the acceptance criterion. The resulting discrepancy distributions have been used for selecting models that are in agreement with many aspects of the data simultaneously,[40] and model inconsistency is detected from conflicting and co-dependent summaries. Another quality-control-based method for model selection employs ABC to approximate the effective number of model parameters and the deviance of the posterior predictive distributions of summaries and parameters.[41] The deviance information criterion is then used as measure of model fit. It has also been shown that the models preferred based on this criterion can conflict with those supported by Bayes factors. For this reason, it is useful to combine different methods for model selection to obtain correct conclusions.
Quality controls are achievable and indeed performed in many ABC-based works, but for certain problems, the assessment of the impact of the method-related parameters can be challenging. However, the rapidly increasing use of ABC can be expected to provide a more thorough understanding of the limitations and applicability of the method.
General risks in statistical inference exacerbated in ABC
This section reviews risks that are strictly speaking not specific to ABC, but also relevant for other statistical methods as well. However, the flexibility offered by ABC to analyze very complex models makes them highly relevant to discuss here.
Prior distribution and parameter ranges
The specification of the range and the prior distribution of parameters strongly benefits from previous knowledge about the properties of the system. One criticism has been that in some studies the “parameter ranges and distributions are only guessed based upon the subjective opinion of the investigators”,[42] which is connected to classical objections of Bayesian approaches.[43]
With any computational method, it is typically necessary to constrain the investigated parameter ranges. The parameter ranges should if possible be defined based on known properties of the studied system, but may for practical applications necessitate an educated guess. However, theoretical results regarding objective priors are available, which may for example be based on the principle of indifference or the principle of maximum entropy.[44][45] On the other hand, automated or semi-automated methods for choosing a prior distribution often yield improper densities. As most ABC procedures require generating samples from the prior, improper priors are not directly applicable to ABC.
One should also keep the purpose of the analysis in mind when choosing the prior distribution. In principle, uninformative and flat priors, that exaggerate our subjective ignorance about the parameters, may still yield reasonable parameter estimates. However, Bayes factors are highly sensitive to the prior distribution of parameters. Conclusions on model choice based on Bayes factor can be misleading unless the sensitivity of conclusions to the choice of priors is carefully considered.
Small number of models
Model-based methods have been criticized for not exhaustively covering the hypothesis space.[22] Indeed, model-based studies often revolve around a small number of models, and due to the high computational cost to evaluate a single model in some instances, it may then be difficult to cover a large part of the hypothesis space.
An upper limit to the number of considered candidate models is typically set by the substantial effort required to define the models and to choose between many alternative options.[11] There is no commonly accepted ABC-specific procedure for model construction, so experience and prior knowledge are used instead.[12] Although more robust procedures for a priori model choice and formulation would be beneficial, there is no one-size-fits-all strategy for model development in statistics: sensible characterization of complex systems will always necessitate a great deal of detective work and use of expert knowledge from the problem domain.
Some opponents of ABC contend that since only few models—subjectively chosen and probably all wrong—can be realistically considered, ABC analyses provide only limited insight.[22] However, there is an important distinction between identifying a plausible null hypothesis and assessing the relative fit of alternative hypotheses.[10] Since useful null hypotheses, that potentially hold true, can extremely seldom be put forward in the context of complex models, predictive ability of statistical models as explanations of complex phenomena is far more important than the test of a statistical null hypothesis in this context. It is also common to average over the investigated models, weighted based on their relative plausibility, to infer model features (e.g., parameter values) and to make predictions.
Large datasets
Large data sets may constitute a computational bottleneck for model-based methods. It was, for example, pointed out that in some ABC-based analyses, part of the data have to be omitted.[22] A number of authors have argued that large data sets are not a practical limitation,[11][43] although the severity of this issue depends strongly on the characteristics of the models. Several aspects of a modeling problem can contribute to the computational complexity, such as the sample size, number of observed variables or features, time or spatial resolution, etc. However, with increasing computing power, this issue will potentially be less important.
Instead of sampling parameters for each simulation from the prior, it has been proposed alternatively to combine the Metropolis-Hastings algorithm with ABC, which was reported to result in a higher acceptance rate than for plain ABC.[34] Naturally, such an approach inherits the general burdens of MCMC methods, such as the difficulty to assess convergence, correlation among the samples from the posterior,[24] and relatively poor parallelizability.[11]
Likewise, the ideas of sequential Monte Carlo (SMC) and population Monte Carlo (PMC) methods have been adapted to the ABC setting.[24][46] The general idea is to iteratively approach the posterior from the prior through a sequence of target distributions. An advantage of such methods, compared to ABC-MCMC, is that the samples from the resulting posterior are independent. In addition, with sequential methods the tolerance levels must not be specified prior to the analysis, but are adjusted adaptively.[47]
It is relatively straightforward to parallelize a number of steps in ABC algorithms based on rejection sampling and sequential Monte Carlo methods. It has also been demonstrated that parallel algorithms may yield significant speedups for MCMC-based inference in phylogenetics,[48] which may be a tractable approach also for ABC-based methods. Yet an adequate model for a complex system is very likely to require intensive computation irrespectively of the chosen method of inference, and it is up to the user to select a method that is suitable for the particular application in question.
Curse of dimensionality
High-dimensional data sets and high-dimensional parameter spaces can require an extremely large number of parameter points to be simulated in ABC-based studies to obtain a reasonable level of accuracy for the posterior inferences. In such situations, the computational cost is severely increased and may in the worst case render the computational analysis intractable. These are examples of well-known phenomena, which are usually referred to with the umbrella term curse of dimensionality.[49]
To assess how severely the dimensionality of a data set affects the analysis within the context of ABC, analytical formulas have been derived for the error of the ABC estimators as functions of the dimension of the summary statistics.[50][51] In addition, Blum and François have investigated how the dimension of the summary statistics is related to the mean squared error for different correction adjustments to the error of ABC estimators. It was also argued that dimension reduction techniques are useful to avoid the curse-of-dimensionality, due to a potentially lower-dimensional underlying structure of summary statistics.[50] Motivated by minimizing the quadratic loss of ABC estimators, Fearnhead and Prangle have proposed a scheme to project (possibly high-dimensional) data into estimates of the parameter posterior means; these means, now having the same dimension as the parameters, are then used as summary statistics for ABC.[51]
ABC can be used to infer problems in high-dimensional parameter spaces, although one should account for the possibility of overfitting (e.g., see the model selection methods in [40] and [41]). However, the probability of accepting the simulated values for the parameters under a given tolerance with the ABC rejection algorithm typically decreases exponentially with increasing dimensionality of the parameter space (due to the global acceptance criterion).[12] Although no computational method (based on ABC or not) seems to be able to break the curse-of-dimensionality, methods have recently been developed to handle high-dimensional parameter spaces under certain assumptions (e.g., based on polynomial approximation on sparse grids,[52] which could potentially heavily reduce the simulation times for ABC). However, the applicability of such methods is problem dependent, and the difficulty of exploring parameter spaces should in general not be underestimated. For example, the introduction of deterministic global parameter estimation led to reports that the global optima obtained in several previous studies of low-dimensional problems were incorrect.[53] For certain problems, it might therefore be difficult to know whether the model is incorrect or, as discussed above, whether the explored region of the parameter space is inappropriate.[22] More pragmatic approaches are to cut the scope of the problem through model reduction,[12] discretisation of variables and the use of canonical models such as noisy models. Noisy models exploit information on the conditional independence between variables.[54]
Software
A number of software packages are currently available for application of ABC to particular classes of statistical models.
| Software | Keywords and features | Reference |
|---|---|---|
| pyABC | Python framework for efficient distributed ABC-SMC (Sequential Monte Carlo). | [55] |
| DIY-ABC | Software for fit of genetic data to complex situations. Comparison of competing models. Parameter estimation. Computation of bias and precision measures for a given model and known parameters values. | [56] |
| abc R package |
Several ABC algorithms for performing parameter estimation and model selection. Nonlinear heteroscedastic regression methods for ABC. Cross-validation tool. | [57][58] |
| EasyABC R package |
Several algorithms for performing efficient ABC sampling schemes, including 4 sequential sampling schemes and 3 MCMC schemes. | [59][60] |
| ABC-SysBio | Python package. Parameter inference and model selection for dynamical systems. Combines ABC rejection sampler, ABC SMC for parameter inference, and ABC SMC for model selection. Compatible with models written in Systems Biology Markup Language (SBML). Deterministic and stochastic models. | [61] |
| ABCtoolbox | Open source programs for various ABC algorithms including rejection sampling, MCMC without likelihood, a particle-based sampler, and ABC-GLM. Compatibility with most simulation and summary statistics computation programs. | [62] |
| msBayes | Open source software package consisting of several C and R programs that are run with a Perl "front-end". Hierarchical coalescent models. Population genetic data from multiple co-distributed species. | [63] |
| PopABC | Software package for inference of the pattern of demographic divergence. Coalescent simulation. Bayesian model choice. | [64] |
| ONeSAMP | Web-based program to estimate the effective population size from a sample of microsatellite genotypes. Estimates of effective population size, together with 95% credible limits. | [65] |
| ABC4F | Software for estimation of F-statistics for dominant data. | [66] |
| 2BAD | 2-event Bayesian ADmixture. Software allowing up to two independent admixture events with up to three parental populations. Estimation of several parameters (admixture, effective sizes, etc.). Comparison of pairs of admixture models. | [67] |
| ELFI | Engine for Likelihood-Free Inference. ELFI is a statistical software package written in Python for Approximate Bayesian Computation (ABC), also known e.g. as likelihood-free inference, simulator-based inference, approximative Bayesian inference etc. | [68] |
| ABCpy | Python package for ABC and other likelihood-free inference schemes. Several state-of-the-art algorithms available. Provides quick way to integrate existing generative (from C++, R etc.), user-friendly parallelization using MPI or Spark and summary statistics learning (with neural network or linear regression). | [69] |
The suitability of individual software packages depends on the specific application at hand, the computer system environment, and the algorithms required.
See also
References
![]() This article was adapted from the following source under a CC BY 4.0 license (2013) (reviewer reports): "Approximate Bayesian computation". PLOS Computational Biology. 9 (1): e1002803. 2013. doi:10.1371/JOURNAL.PCBI.1002803. ISSN 1553-734X. PMC 3547661. PMID 23341757. Wikidata Q4781761.
This article was adapted from the following source under a CC BY 4.0 license (2013) (reviewer reports): "Approximate Bayesian computation". PLOS Computational Biology. 9 (1): e1002803. 2013. doi:10.1371/JOURNAL.PCBI.1002803. ISSN 1553-734X. PMC 3547661. PMID 23341757. Wikidata Q4781761.
- Rubin, DB (1984). "Bayesianly Justifiable and Relevant Frequency Calculations for the Applied Statistician". The Annals of Statistics. 12 (4): 1151–1172. doi:10.1214/aos/1176346785.
- see figure 5 in Stigler, Stephen M. (2010). "Darwin, Galton and the Statistical Enlightenment". Journal of the Royal Statistical Society. Series A (Statistics in Society). 173 (3): 469–482. doi:10.1111/j.1467-985X.2010.00643.x. ISSN 0964-1998.
- Diggle, PJ (1984). "Monte Carlo Methods of Inference for Implicit Statistical Models". Journal of the Royal Statistical Society, Series B. 46: 193–227.
- Bartlett, MS (1963). "The spectral analysis of point processes". Journal of the Royal Statistical Society, Series B. 25: 264–296.
- Hoel, DG; Mitchell, TJ (1971). "The simulation, fitting and testing of a stochastic cellular proliferation model". Biometrics. 27 (1): 191–199. doi:10.2307/2528937. JSTOR 2528937. PMID 4926451.
- Tavaré, S; Balding, DJ; Griffiths, RC; Donnelly, P (1997). "Inferring Coalescence Times from DNA Sequence Data". Genetics. 145 (2): 505–518. PMC 1207814. PMID 9071603.
- Pritchard, JK; Seielstad, MT; Perez-Lezaun, A; et al. (1999). "Population Growth of Human Y Chromosomes: A Study of Y Chromosome Microsatellites". Molecular Biology and Evolution. 16 (12): 1791–1798. doi:10.1093/oxfordjournals.molbev.a026091. PMID 10605120.
- Beaumont, MA; Zhang, W; Balding, DJ (2002). "Approximate Bayesian Computation in Population Genetics". Genetics. 162 (4): 2025–2035. PMC 1462356. PMID 12524368.
- Busetto A.G., Buhmann J. Stable Bayesian Parameter Estimation for Biological Dynamical Systems.; 2009. IEEE Computer Society Press pp. 148-157.
- Beaumont, MA (2010). "Approximate Bayesian Computation in Evolution and Ecology". Annual Review of Ecology, Evolution, and Systematics. 41: 379–406. doi:10.1146/annurev-ecolsys-102209-144621.
- Bertorelle, G; Benazzo, A; Mona, S (2010). "ABC as a flexible framework to estimate demography over space and time: some cons, many pros". Molecular Ecology. 19 (13): 2609–2625. doi:10.1111/j.1365-294x.2010.04690.x. PMID 20561199. S2CID 12129604.
- Csilléry, K; Blum, MGB; Gaggiotti, OE; François, O (2010). "Approximate Bayesian Computation (ABC) in practice". Trends in Ecology & Evolution. 25 (7): 410–418. doi:10.1016/j.tree.2010.04.001. PMID 20488578.
- Didelot, X; Everitt, RG; Johansen, AM; Lawson, DJ (2011). "Likelihood-free estimation of model evidence". Bayesian Analysis. 6: 49–76. doi:10.1214/11-ba602.
- Lai, K; Robertson, MJ; Schaffer, DV (2004). "The sonic hedgehog signaling system as a bistable genetic switch". Biophys. J. 86 (5): 2748–2757. Bibcode:2004BpJ....86.2748L. doi:10.1016/s0006-3495(04)74328-3. PMC 1304145. PMID 15111393.
- Marin, JM; Pudlo, P; Robert, CP; Ryder, RJ (2012). "Approximate Bayesian computational methods". Statistics and Computing. 22 (6): 1167–1180. arXiv:1101.0955. doi:10.1007/s11222-011-9288-2. S2CID 40304979.
- Wilkinson, R. G. (2007). Bayesian Estimation of Primate Divergence Times, Ph.D. thesis, University of Cambridge.
- Grelaud, A; Marin, J-M; Robert, C; Rodolphe, F; Tally, F (2009). "Likelihood-free methods for model choice in Gibbs random fields". Bayesian Analysis. 3: 427–442.
- Toni T, Stumpf MPH (2010). Simulation-based model selection for dynamical systems in systems and population biology, Bioinformatics' 26 (1):104–10.
- Templeton, AR (2009). "Why does a method that fails continue to be used? The answer". Evolution. 63 (4): 807–812. doi:10.1111/j.1558-5646.2008.00600.x. PMC 2693665. PMID 19335340.
- Robert, CP; Cornuet, J-M; Marin, J-M; Pillai, NS (2011). "Lack of confidence in approximate Bayesian computation model choice". Proc Natl Acad Sci U S A. 108 (37): 15112–15117. Bibcode:2011PNAS..10815112R. doi:10.1073/pnas.1102900108. PMC 3174657. PMID 21876135.
- Templeton, AR (2008). "Nested clade analysis: an extensively validated method for strong phylogeographic inference". Molecular Ecology. 17 (8): 1877–1880. doi:10.1111/j.1365-294x.2008.03731.x. PMC 2746708. PMID 18346121.
- Templeton, AR (2009). "Statistical hypothesis testing in intraspecific phylogeography: nested clade phylogeographical analysis vs. approximate Bayesian computation". Molecular Ecology. 18 (2): 319–331. doi:10.1111/j.1365-294x.2008.04026.x. PMC 2696056. PMID 19192182.
- Berger, JO; Fienberg, SE; Raftery, AE; Robert, CP (2010). "Incoherent phylogeographic inference". Proceedings of the National Academy of Sciences of the United States of America. 107 (41): E157. Bibcode:2010PNAS..107E.157B. doi:10.1073/pnas.1008762107. PMC 2955098. PMID 20870964.
- Sisson, SA; Fan, Y; Tanaka, MM (2007). "Sequential Monte Carlo without likelihoods". Proc Natl Acad Sci U S A. 104 (6): 1760–1765. Bibcode:2007PNAS..104.1760S. doi:10.1073/pnas.0607208104. PMC 1794282. PMID 17264216.
- Dean TA, Singh SS, Jasra A, Peters GW (2011) Parameter estimation for hidden markov models with intractable likelihoods. arXiv:11035399v1 [mathST] 28 Mar 2011.
- Fearnhead P, Prangle D (2011) Constructing Summary Statistics for Approximate Bayesian Computation: Semi-automatic ABC. ArXiv:10041112v2 [statME] 13 Apr 2011.
- Blum, M; Francois, O (2010). "Non-linear regression models for approximate Bayesian computation". Stat Comp. 20: 63–73. arXiv:0809.4178. doi:10.1007/s11222-009-9116-0. S2CID 2403203.
- Leuenberger, C; Wegmann, D (2009). "Bayesian Computation and Model Selection Without Likelihoods". Genetics. 184 (1): 243–252. doi:10.1534/genetics.109.109058. PMC 2815920. PMID 19786619.
- Wilkinson RD (2009) Approximate Bayesian computation (ABC) gives exact results under the assumption of model error. arXiv:08113355.
- Blum MGB, Nunes MA, Prangle D, Sisson SA (2012) A comparative review of dimension reduction methods in approximate Bayesian computation. arxiv.org/abs/1202.3819
- Nunes, MA; Balding, DJ (2010). "On optimal selection of summary statistics for approximate Bayesian computation". Stat Appl Genet Mol Biol. 9: Article 34. doi:10.2202/1544-6115.1576. PMID 20887273. S2CID 207319754.
- Joyce, P; Marjoram, P (2008). "Approximately sufficient statistics and bayesian computation". Stat Appl Genet Mol Biol. 7 (1): Article 26. doi:10.2202/1544-6115.1389. PMID 18764775. S2CID 38232110.
- Wegmann, D; Leuenberger, C; Excoffier, L (2009). "Efficient approximate Bayesian computation coupled with Markov chain Monte Carlo without likelihood". Genetics. 182 (4): 1207–1218. doi:10.1534/genetics.109.102509. PMC 2728860. PMID 19506307.
- Marjoram, P; Molitor, J; Plagnol, V; Tavare, S (2003). "Markov chain Monte Carlo without likelihoods". Proc Natl Acad Sci U S A. 100 (26): 15324–15328. Bibcode:2003PNAS..10015324M. doi:10.1073/pnas.0306899100. PMC 307566. PMID 14663152.
- Marin J-M, Pillai NS, Robert CP, Rousseau J (2011) Relevant statistics for Bayesian model choice. ArXiv:11104700v1 [mathST] 21 Oct 2011: 1-24.
- Toni, T; Welch, D; Strelkowa, N; Ipsen, A; Stumpf, M (2007). "Approximate Bayesian computation scheme for parameter inference and model selection in dynamical systems". J R Soc Interface. 6 (31): 187–202. doi:10.1098/rsif.2008.0172. PMC 2658655. PMID 19205079.
- Arlot, S; Celisse, A (2010). "A survey of cross-validation procedures for model selection". Statistics Surveys. 4: 40–79. arXiv:0907.4728. doi:10.1214/09-ss054. S2CID 14332192.
- Dawid, A. "Present position and potential developments: Some personal views: Statistical theory: The prequential approach". Journal of the Royal Statistical Society, Series A. 1984: 278–292.
- Vehtari, A; Lampinen, J (2002). "Bayesian model assessment and comparison using cross-validation predictive densities". Neural Computation. 14 (10): 2439–2468. CiteSeerX 10.1.1.16.3206. doi:10.1162/08997660260293292. PMID 12396570. S2CID 366285.
- Ratmann, O; Andrieu, C; Wiuf, C; Richardson, S (2009). "Model criticism based on likelihood-free inference, with an application to protein network evolution". Proceedings of the National Academy of Sciences of the United States of America. 106 (26): 10576–10581. Bibcode:2009PNAS..10610576R. doi:10.1073/pnas.0807882106. PMC 2695753. PMID 19525398.
- Francois, O; Laval, G (2011). "Deviance Information Criteria for Model Selection in Approximate Bayesian Computation". Stat Appl Genet Mol Biol. 10: Article 33. arXiv:1105.0269. Bibcode:2011arXiv1105.0269F. doi:10.2202/1544-6115.1678. S2CID 11143942.
- Templeton, AR (2010). "Coherent and incoherent inference in phylogeography and human evolution". Proceedings of the National Academy of Sciences of the United States of America. 107 (14): 6376–6381. Bibcode:2010PNAS..107.6376T. doi:10.1073/pnas.0910647107. PMC 2851988. PMID 20308555.
- Beaumont, MA; Nielsen, R; Robert, C; Hey, J; Gaggiotti, O; et al. (2010). "In defence of model-based inference in phylogeography". Molecular Ecology. 19 (3): 436–446. doi:10.1111/j.1365-294x.2009.04515.x. PMC 5743441. PMID 29284924.
- Jaynes ET (1968) Prior Probabilities. IEEE Transactions on Systems Science and Cybernetics 4.
- Berger, J.O. (2006). "The case for objective Bayesian analysis". Bayesian Analysis. 1 (pages 385–402 and 457–464): 385–402. doi:10.1214/06-BA115.
- Beaumont, MA; Cornuet, J-M; Marin, J-M; Robert, CP (2009). "Adaptive approximate Bayesian computation". Biometrika. 96 (4): 983–990. arXiv:0805.2256. doi:10.1093/biomet/asp052. S2CID 16579245.
- Del Moral P, Doucet A, Jasra A (2011) An adaptive sequential Monte Carlo method for approximate Bayesian computation. Statistics and computing.
- Feng, X; Buell, DA; Rose, JR; Waddellb, PJ (2003). "Parallel Algorithms for Bayesian Phylogenetic Inference". Journal of Parallel and Distributed Computing. 63 (7–8): 707–718. CiteSeerX 10.1.1.109.7764. doi:10.1016/s0743-7315(03)00079-0.
- Bellman R (1961) Adaptive Control Processes: A Guided Tour: Princeton University Press.
- Blum MGB (2010) Approximate Bayesian Computation: a nonparametric perspective, Journal of the American Statistical Association (105): 1178-1187
- Fearnhead, P; Prangle, D (2012). "Constructing summary statistics for approximate Bayesian computation: semi-automatic approximate Bayesian computation". Journal of the Royal Statistical Society, Series B. 74 (3): 419–474. CiteSeerX 10.1.1.760.7753. doi:10.1111/j.1467-9868.2011.01010.x.
- Gerstner, T; Griebel, M (2003). "Dimension-Adaptive Tensor-Product Quadrature". Computing. 71: 65–87. CiteSeerX 10.1.1.16.2434. doi:10.1007/s00607-003-0015-5. S2CID 16184111.
- Singer, AB; Taylor, JW; Barton, PI; Green, WH (2006). "Global dynamic optimization for parameter estimation in chemical kinetics". J Phys Chem A. 110 (3): 971–976. Bibcode:2006JPCA..110..971S. doi:10.1021/jp0548873. PMID 16419997.
- Cardenas, IC (2019). "On the use of Bayesian networks as a meta-modeling approach to analyse uncertainties in slope stability analysis". Georisk: Assessment and Management of Risk for Engineered Systems and Geohazards. 13 (1): 53–65. doi:10.1080/17499518.2018.1498524.
- Klinger, E.; Rickert, D.; Hasenauer, J. (2017). pyABC: distributed, likelihood-free inference.
- Cornuet, J-M; Santos, F; Beaumont, M; et al. (2008). "Inferring population history with DIY ABC: a user-friendly approach to approximate Bayesian computation". Bioinformatics. 24 (23): 2713–2719. doi:10.1093/bioinformatics/btn514. PMC 2639274. PMID 18842597.
- Csilléry, K; François, O; Blum, MGB (2012). "abc: an R package for approximate Bayesian computation (ABC)". Methods in Ecology and Evolution. 3 (3): 475–479. arXiv:1106.2793. doi:10.1111/j.2041-210x.2011.00179.x. S2CID 16679366.
- Csillery, K; Francois, O; Blum, MGB (2012-02-21). "Approximate Bayesian Computation (ABC) in R: A Vignette" (PDF). Retrieved 10 May 2013.
- Jabot, F; Faure, T; Dumoulin, N (2013). "EasyABC: performing efficient approximate Bayesian computation sampling schemes using R." Methods in Ecology and Evolution. 4 (7): 684–687. doi:10.1111/2041-210X.12050.
- Jabot, F; Faure, T; Dumoulin, N (2013-06-03). "EasyABC: a vignette" (PDF).
- Liepe, J; Barnes, C; Cule, E; Erguler, K; Kirk, P; Toni, T; Stumpf, MP (2010). "ABC-SysBio—approximate Bayesian computation in Python with GPU support". Bioinformatics. 26 (14): 1797–1799. doi:10.1093/bioinformatics/btq278. PMC 2894518. PMID 20591907.
- Wegmann, D; Leuenberger, C; Neuenschwander, S; Excoffier, L (2010). "ABCtoolbox: a versatile toolkit for approximate Bayesian computations". BMC Bioinformatics. 11: 116. doi:10.1186/1471-2105-11-116. PMC 2848233. PMID 20202215.
- Hickerson, MJ; Stahl, E; Takebayashi, N (2007). "msBayes: Pipeline for testing comparative phylogeographic histories using hierarchical approximate Bayesian computation". BMC Bioinformatics. 8 (268): 1471–2105. doi:10.1186/1471-2105-8-268. PMC 1949838. PMID 17655753.
- Lopes, JS; Balding, D; Beaumont, MA (2009). "PopABC: a program to infer historical demographic parameters". Bioinformatics. 25 (20): 2747–2749. doi:10.1093/bioinformatics/btp487. PMID 19679678.
- Tallmon, DA; Koyuk, A; Luikart, G; Beaumont, MA (2008). "COMPUTER PROGRAMS: onesamp: a program to estimate effective population size using approximate Bayesian computation". Molecular Ecology Resources. 8 (2): 299–301. doi:10.1111/j.1471-8286.2007.01997.x. PMID 21585773. S2CID 9848290.
- Foll, M; Baumont, MA; Gaggiotti, OE (2008). "An Approximate Bayesian Computation approach to overcome biases that arise when using AFLP markers to study population structure". Genetics. 179 (2): 927–939. doi:10.1534/genetics.107.084541. PMC 2429886. PMID 18505879.
- Bray, TC; Sousa, VC; Parreira, B; Bruford, MW; Chikhi, L (2010). "2BAD: an application to estimate the parental contributions during two independent admisture events". Molecular Ecology Resources. 10 (3): 538–541. doi:10.1111/j.1755-0998.2009.02766.x. hdl:10400.7/205. PMID 21565053. S2CID 6528668.
- Kangasrääsiö, Antti; Lintusaari, Jarno; Skytén, Kusti; Järvenpää, Marko; Vuollekoski, Henri; Gutmann, Michael; Vehtari, Aki; Corander, Jukka; Kaski, Samuel (2016). "ELFI: Engine for Likelihood-Free Inference" (PDF). NIPS 2016 Workshop on Advances in Approximate Bayesian Inference. arXiv:1708.00707. Bibcode:2017arXiv170800707L.
- Dutta, R; Schoengens, M; Pacchiardi, L; Ummadisingu, A; Widmer, N; Onnela, J. P.; Mira, A (2020). "ABCpy: A High-Performance Computing Perspective to Approximate Bayesian Computation". arXiv:1711.04694. Cite journal requires
|journal=(help)
External links
- Darren Wilkinson (March 31, 2013). "Introduction to Approximate Bayesian Computation". Retrieved 2013-03-31.
- Rasmus Bååth (October 20, 2014). "Tiny Data, Approximate Bayesian Computation and the Socks of Karl Broman". Retrieved 2015-01-22.
