Bernoulli process
In probability and statistics, a Bernoulli process (named after Jacob Bernoulli) is a finite or infinite sequence of binary random variables, so it is a discrete-time stochastic process that takes only two values, canonically 0 and 1. The component Bernoulli variables Xi are identically distributed and independent. Prosaically, a Bernoulli process is a repeated coin flipping, possibly with an unfair coin (but with consistent unfairness). Every variable Xi in the sequence is associated with a Bernoulli trial or experiment. They all have the same Bernoulli distribution. Much of what can be said about the Bernoulli process can also be generalized to more than two outcomes (such as the process for a six-sided die); this generalization is known as the Bernoulli scheme.
The problem of determining the process, given only a limited sample of Bernoulli trials, may be called the problem of checking whether a coin is fair.
Definition
A Bernoulli process is a finite or infinite sequence of independent random variables X1, X2, X3, ..., such that
- for each i, the value of Xi is either 0 or 1;
- for all values of i, the probability p that Xi = 1 is the same.
In other words, a Bernoulli process is a sequence of independent identically distributed Bernoulli trials.
Independence of the trials implies that the process is memoryless. Given that the probability p is known, past outcomes provide no information about future outcomes. (If p is unknown, however, the past informs about the future indirectly, through inferences about p.)
If the process is infinite, then from any point the future trials constitute a Bernoulli process identical to the whole process, the fresh-start property.
Interpretation
The two possible values of each Xi are often called "success" and "failure". Thus, when expressed as a number 0 or 1, the outcome may be called the number of successes on the ith "trial".
Two other common interpretations of the values are true or false and yes or no. Under any interpretation of the two values, the individual variables Xi may be called Bernoulli trials with parameter p.
In many applications time passes between trials, as the index i increases. In effect, the trials X1, X2, ... Xi, ... happen at "points in time" 1, 2, ..., i, .... That passage of time and the associated notions of "past" and "future" are not necessary, however. Most generally, any Xi and Xj in the process are simply two from a set of random variables indexed by {1, 2, ..., n}, the finite cases, or by {1, 2, 3, ...}, the infinite cases.
One experiment with only two possible outcomes, often referred to as "success" and "failure", usually encoded as 1 and 0, can be modeled as a Bernoulli distribution.[1] Several random variables and probability distributions beside the Bernoullis may be derived from the Bernoulli process:
- The number of successes in the first n trials, which has a binomial distribution B(n, p)
- The number of failures needed to get r successes, which has a negative binomial distribution NB(r, p)
- The number of failures needed to get one success, which has a geometric distribution NB(1, p), a special case of the negative binomial distribution
The negative binomial variables may be interpreted as random waiting times.
Formal definition
The Bernoulli process can be formalized in the language of probability spaces as a random sequence of independent realisations of a random variable that can take values of heads or tails. The state space for an individual value is denoted by

Borel algebra
Consider the countably infinite direct product of copies of . It is common to examine either the one-sided set or the two-sided set . There is a natural topology on this space, called the product topology. The sets in this topology are finite sequences of coin flips, that is, finite-length strings of H and T (H stands for heads and T stands for tails), with the rest of (infinitely long) sequence taken as "don't care". These sets of finite sequences are referred to as cylinder sets in the product topology. The set of all such strings form a sigma algebra, specifically, a Borel algebra. This algebra is then commonly written as where the elements of are the finite-length sequences of coin flips (the cylinder sets).





Bernoulli measure
If the chances of flipping heads or tails are given by the probabilities , then one can define a natural measure on the product space, given by (or by for the two-sided process). In another word, if a discrete random variable X has a Bernoulli distribution with parameter p, where 0 ≤ p ≤ 1, and its probability mass function is given by



- and .


We denote this distribution by Ber(p).[2]
Given a cylinder set, that is, a specific sequence of coin flip results at times , the probability of observing this particular sequence is given by



where k is the number of times that H appears in the sequence, and n−k is the number of times that T appears in the sequence. There are several different kinds of notations for the above; a common one is to write

where each is a binary-valued random variable with in Iverson bracket notation, meaning either if or if . This probability is commonly called the Bernoulli measure.[3]







Note that the probability of any specific, infinitely long sequence of coin flips is exactly zero; this is because , for any . A probability equal to 1 implies that any given infinite sequence has measure zero. Nevertheless, one can still say that some classes of infinite sequences of coin flips are far more likely than others, this is given by the asymptotic equipartition property.


To conclude the formal definition, a Bernoulli process is then given by the probability triple , as defined above.

Law of large numbers, binomial distribution and central limit theorem
Let us assume the canonical process with represented by and represented by . The law of large numbers states that, on the average of the sequence, i.e., , will approach the expected value almost certainly, that is, the events which do not satisfy this limit have zero probability. The expectation value of flipping heads, assumed to be represented by 1, is given by . In fact, one has





for any given random variable out of the infinite sequence of Bernoulli trials that compose the Bernoulli process.
One is often interested in knowing how often one will observe H in a sequence of n coin flips. This is given by simply counting: Given n successive coin flips, that is, given the set of all possible strings of length n, the number N(k,n) of such strings that contain k occurrences of H is given by the binomial coefficient

If the probability of flipping heads is given by p, then the total probability of seeing a string of length n with k heads is

where . The probability measure thus defined is known as the Binomial distribution.

As we can see from the above formula that, if n=1, the Binomial distribution will turn into a Bernoulli distribution. So we can know that the Bernoulli distribution is exactly a special case of Binomial distribution when n equals to 1.
Of particular interest is the question of the value of for a sufficiently long sequences of coin flips, that is, for the limit . In this case, one may make use of Stirling's approximation to the factorial, and write



Inserting this into the expression for P(k,n), one obtains the Normal distribution; this is the content of the central limit theorem, and this is the simplest example thereof.
The combination of the law of large numbers, together with the central limit theorem, leads to an interesting and perhaps surprising result: the asymptotic equipartition property. Put informally, one notes that, yes, over many coin flips, one will observe H exactly p fraction of the time, and that this corresponds exactly with the peak of the Gaussian. The asymptotic equipartition property essentially states that this peak is infinitely sharp, with infinite fall-off on either side. That is, given the set of all possible infinitely long strings of H and T occurring in the Bernoulli process, this set is partitioned into two: those strings that occur with probability 1, and those that occur with probability 0. This partitioning is known as the Kolmogorov 0-1 law.
The size of this set is interesting, also, and can be explicitly determined: the logarithm of it is exactly the entropy of the Bernoulli process. Once again, consider the set of all strings of length n. The size of this set is . Of these, only a certain subset are likely; the size of this set is for . By using Stirling's approximation, putting it into the expression for P(k,n), solving for the location and width of the peak, and finally taking one finds that




This value is the Bernoulli entropy of a Bernoulli process. Here, H stands for entropy; do not confuse it with the same symbol H standing for heads.
John von Neumann posed a curious question about the Bernoulli process: is it ever possible that a given process is isomorphic to another, in the sense of the isomorphism of dynamical systems? The question long defied analysis, but was finally and completely answered with the Ornstein isomorphism theorem. This breakthrough resulted in the understanding that the Bernoulli process is unique and universal; in a certain sense, it is the single most random process possible; nothing is 'more' random than the Bernoulli process (although one must be careful with this informal statement; certainly, systems that are mixing are, in a certain sense, 'stronger' than the Bernoulli process, which is merely ergodic but not mixing. However, such processes do not consist of independent random variables: indeed, many purely deterministic, non-random systems can be mixing).
Dynamical systems
The Bernoulli process can also be understood to be a dynamical system, as an example of an ergodic system and specifically, a measure-preserving dynamical system, in one of several different ways. One way is as a shift space, and the other is as an odometer. These are reviewed below.
Bernoulli shift
One way to create a dynamical system out of the Bernoulli process is as a shift space. There is a natural translation symmetry on the product space given by the shift operator


The Bernoulli measure, defined above, is translation-invariant; that is, given any cylinder set , one has


and thus the Bernoulli measure is a Haar measure; it is an invariant measure on the product space.
Instead of the probability measure , consider instead some arbitrary function . The pushforward



defined by is again some function Thus, the map induces another map on the space of all functions That is, given some , one defines




The map is a linear operator, as (obviously) one has and for functions and constant . This linear operator is called the transfer operator or the Ruelle–Frobenius–Perron operator. This operator has a spectrum, that is, a collection of eigenfunctions and corresponding eigenvalues. The largest eigenvalue is the Frobenius–Perron eigenvalue, and in this case, it is 1. The associated eigenvector is the invariant measure: in this case, it is the Bernoulli measure. That is,





If one restricts to act on polynomials, then the eigenfunctions are (curiously) the Bernoulli polynomials![4][5] This coincidence of naming was presumably not known to Bernoulli.
The 2x mod 1 map
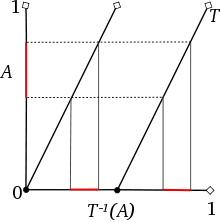

The above can be made more precise. Given an infinite string of binary digits write


The resulting is a real number in the unit interval The shift induces a homomorphism, also called , on the unit interval. Since one can easily see that This map is called the dyadic transformation; for the doubly-infinite sequence of bits the induced homomorphism is the Baker's map.





Consider now the space of functions in . Given some one can easily find that


Restricting the action of the operator to functions that are on polynomials, one finds that it has a discrete spectrum given by

where the are the Bernoulli polynomials. Indeed, the Bernoulli polynomials obey the identity


The Cantor set
Note that the sum

gives the Cantor function, as conventionally defined. This is one reason why the set is sometimes called the Cantor set.

Odometer
Another way to create a dynamical system is to define an odometer. Informally, this is exactly what it sounds like: just "add one" to the first position, and let the odometer "roll over" by using carry bits as the odometer rolls over. This is nothing more than base-two addition on the set of infinite strings. Since addition forms a group (mathematics), and the Bernoulli process was already given a topology, above, this provides a simple example of a topological group.
In this case, the transformation is given by

It leaves the Bernoulli measure invariant only for the special case of (the "fair coin"); otherwise not. Thus, is a measure preserving dynamical system in this case, otherwise, it is merely a conservative system.

Bernoulli sequence
The term Bernoulli sequence is often used informally to refer to a realization of a Bernoulli process. However, the term has an entirely different formal definition as given below.
Suppose a Bernoulli process formally defined as a single random variable (see preceding section). For every infinite sequence x of coin flips, there is a sequence of integers

called the Bernoulli sequence associated with the Bernoulli process. For example, if x represents a sequence of coin flips, then the associated Bernoulli sequence is the list of natural numbers or time-points for which the coin toss outcome is heads.
So defined, a Bernoulli sequence is also a random subset of the index set, the natural numbers .


Almost all Bernoulli sequences are ergodic sequences.
Randomness extraction
From any Bernoulli process one may derive a Bernoulli process with p = 1/2 by the von Neumann extractor, the earliest randomness extractor, which actually extracts uniform randomness.
Basic von Neumann extractor
Represent the observed process as a sequence of zeroes and ones, or bits, and group that input stream in non-overlapping pairs of successive bits, such as (11)(00)(10)... . Then for each pair,
- if the bits are equal, discard;
- if the bits are not equal, output the first bit.
This table summarizes the computation.
| input | output |
|---|---|
| 00 | discard |
| 01 | 0 |
| 10 | 1 |
| 11 | discard |
For example, an input stream of eight bits 10011011 would by grouped into pairs as (10)(01)(10)(11). Then, according to the table above, these pairs are translated into the output of the procedure: (1)(0)(1)() (=101).
In the output stream 0 and 1 are equally likely, as 10 and 01 are equally likely in the original, both having probability p(1−p) = (1−p)p. This extraction of uniform randomness does not require the input trials to be independent, only uncorrelated. More generally, it works for any exchangeable sequence of bits: all sequences that are finite rearrangements are equally likely.
The von Neumann extractor uses two input bits to produce either zero or one output bits, so the output is shorter than the input by a factor of at least 2. On average the computation discards proportion p2 + (1 − p)2 of the input pairs(00 and 11), which is near one when p is near zero or one, and is minimized at 1/4 when p = 1/2 for the original process (in which case the output stream is 1/4 the length of the input stream on average).
Von Neumann (classical) main operation pseudocode:
if (Bit1 ≠ Bit2) {
output(Bit1)
}
Iterated von Neumann extractor
This decrease in efficiency, or waste of randomness present in the input stream, can be mitigated by iterating the algorithm over the input data. This way the output can be made to be "arbitrarily close to the entropy bound".[6]
The iterated version of the von Neumann algorithm, also known as Advanced Multi-Level Strategy (AMLS),[7] was introduced by Yuval Peres in 1992.[6] It works recursively, recycling "wasted randomness" from two sources: the sequence of discard/non-discard, and the values of discarded pairs (0 for 00, and 1 for 11). Intuitively, it relies on the fact that, given the sequence already generated, both of those sources are still exchangeable sequences of bits, and thus eligible for another round of extraction. While such generation of additional sequences can be iterated infinitely to extract all available entropy, an infinite amount of computational resources is required, therefore the number of iterations is typically fixed to a low value – this value either fixed in advance, or calculated at runtime.
More concretely, on an input sequence, the algorithm consumes the input bits in pairs, generating output together with two new sequences:
| input | output | new sequence 1 | new sequence 2 |
|---|---|---|---|
| 00 | none | 0 | 0 |
| 01 | 0 | 1 | none |
| 10 | 1 | 1 | none |
| 11 | none | 0 | 1 |
(If the length of the input is odd, the last bit is completely discarded.) Then the algorithm is applied recursively to each of the two new sequences, until the input is empty.
Example: The input stream from above, 10011011, is processed this way:
| step number | input | output | new sequence 1 | new sequence 2 |
|---|---|---|---|---|
| 0 | (10)(01)(10)(11) | (1)(0)(1)() | (1)(1)(1)(0) | ()()()(1) |
| 1 | (11)(10) | ()(1) | (0)(1) | (1)() |
| 1.1 | (01) | (0) | (1) | () |
| 1.1.1 | 1 | none | none | none |
| 1.2 | 1 | none | none | none |
| 2 | 1 | none | none | none |
From the step of 1 on, the input becomes the new sequence1 of the last step to move on in this process. The output is therefore (101)(1)(0)()()() (=10110), so that from the eight bits of input five bits of output were generated, as opposed to three bits through the basic algorithm above. The constant output of exactly 2 bits per round (compared with a variable 0 to 1 bits in classical VN) also allows for constant-time implementations which are resistant to timing attacks.
Von Neumann–Peres (iterated) main operation pseudocode:
if (Bit1 ≠ Bit2) {
output(1, Sequence1)
output(Bit1)
} else {
output(0, Sequence1)
output(Bit1, Sequence2)
}
Another tweak was presented in 2016, based on the observation that the Sequence2 channel doesn't provide much throughput, and a hardware implementation with a finite number of levels can benefit from discarding it earlier in exchange for processing more levels of Sequence1.[8]
References
- A modern introduction to probability and statistics. pp. 45–46. ISBN 9781852338961.
- A modern introduction to probability and statistics. pp. 45–46. ISBN 9781852338961.
- Klenke, Achim (2006). Probability Theory. Springer-Verlag. ISBN 978-1-84800-047-6.
- Pierre Gaspard, "r-adic one-dimensional maps and the Euler summation formula", Journal of Physics A, 25 (letter) L483-L485 (1992).
- Dean J. Driebe, Fully Chaotic Maps and Broken Time Symmetry, (1999) Kluwer Academic Publishers, Dordrecht Netherlands ISBN 0-7923-5564-4
- Peres, Yuval (March 1992). "Iterating Von Neumann's Procedure for Extracting Random Bits" (PDF). The Annals of Statistics. 20 (1): 590–597. doi:10.1214/aos/1176348543. Archived from the original (PDF) on 18 May 2013. Retrieved 30 May 2013.
- "Tossing a Biased Coin" (PDF). eecs.harvard.edu. Retrieved 2018-07-28.
- Rožić, Vladimir; Yang, Bohan; Dehaene, Wim; Verbauwhede, Ingrid (3–5 May 2016). Iterating Von Neumann's post-processing under hardware constraints (PDF). 2016 IEEE International Symposium on Hardware Oriented Security and Trust (HOST). Maclean, VA, USA. doi:10.1109/HST.2016.7495553\.
Further reading
- Carl W. Helstrom, Probability and Stochastic Processes for Engineers, (1984) Macmillan Publishing Company, New York ISBN 0-02-353560-1.
