Book scanning
Book scanning or book digitization (also: magazine scanning or magazine digitization) is the process of converting physical books and magazines into digital media such as images, electronic text, or electronic books (e-books) by using an image scanner.


Digital books can be easily distributed, reproduced, and read on-screen. Common file formats are DjVu, Portable Document Format (PDF), and Tagged Image File Format (TIFF). To convert the raw images optical character recognition (OCR) is used to turn book pages into a digital text format like ASCII or other similar format, which reduces the file size and allows the text to be reformatted, searched, or processed by other applications.
Image scanners may be manual or automated. In an ordinary commercial image scanner, the book is placed on a flat glass plate (or platen), and a light and optical array moves across the book underneath the glass. In manual book scanners, the glass plate extends to the edge of the scanner, making it easier to line up the book's spine. Other book scanners place the book face up in a v-shaped frame, and photograph the pages from above. Pages may be turned by hand or by automated paper transport devices. Glass or plastic sheets are usually pressed against the page to flatten it.
After scanning, software adjusts the document images by lining it up, cropping it, picture-editing it, and converting it to text and final e-book form. Human proofreaders usually check the output for errors.
Scanning at 118 dots/centimeter (300 dpi) is adequate for conversion to digital text output, but for archival reproduction of rare, elaborate or illustrated books, much higher resolution is used. High-end scanners capable of thousands of pages per hour can cost thousands of dollars, but do-it-yourself (DIY), manual book scanners capable of 1200 pages per hour have been built for US$300.[1]
Commercial book scanners

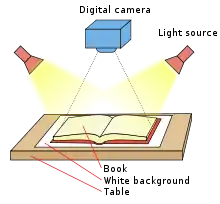
Commercial book scanners are not like normal scanners; these book scanners are usually a high quality digital camera with light sources on either side of the camera mounted on some sort of frame to provide easy access for a person or machine to flip through the pages of the book. Some models involve V-shaped book cradles, which provide support for book spines and also center book position automatically.
The advantage of this type of scanner is that it is very fast, compared to the productivity of overhead scanners.
Large-scale projects
Projects like Project Gutenberg (est. 1971), Million Book Project (est. circa 2001), Google Books (est. 2004), and the Open Content Alliance (est. 2005) scan books on a large scale.
One of the main challenges to this is the sheer volume of books that must be scanned. In 2010 the total number of works appearing as books in human history was estimated to be around 130 million.[2] All of these must be scanned and then made searchable online for the public to use as a universal library. Currently, there are three main ways that large organizations are relying on: outsourcing, scanning in-house using commercial book scanners, and scanning in-house using robotic scanning solutions.
As for outsourcing, books are often shipped to be scanned by low-cost sources to India or China. Alternatively, due to convenience, safety and technology improvement, many organizations choose to scan in-house by using either overhead scanners which are time-consuming, or digital camera-based scanning machines which are substantially faster and is a method employed by Internet Archive as well as Google. Traditional methods have included cutting off the book's spine and scanning the pages in a scanner with automatic page-feeding capability, with subsequent rebinding of the loose pages.
Once the page is scanned, the data is either entered manually or via OCR, another major cost of the book scanning projects.
Due to copyright issues, most scanned books are those that are out of copyright; however, Google Book Search is known to scan books still protected under copyright unless the publisher specifically prohibits this.
Collaborative projects
There are many collaborative digitization projects throughout the United States. Two of the earliest projects were the Collaborative Digitization Project in Colorado and NC ECHO – North Carolina Exploring Cultural Heritage Online,[3] based at the State Library of North Carolina.
These projects establish and publish best practices for digitization and work with regional partners to digitize cultural heritage materials. Additional criteria for best practices have more recently been established in the UK, Australia and the European Union.[4] Wisconsin Heritage Online[5] is a collaborative digitization project modeled after the Colorado Collaborative Digitization Project. Wisconsin uses a wiki[6] to build and distribute collaborative documentation. Georgia's collaborative digitization program, the Digital Library of Georgia,[7] presents a seamless virtual library on the state's history and life, including more than a hundred digital collections from 60 institutions and 100 agencies of government. The Digital Library of Georgia is a GALILEO[8] initiative based at the University of Georgia Libraries.
In the twentieth century, the Hill Museum and Manuscript Library photographed books in Ethiopia that were subsequently destroyed amidst political violence in 1975. The library has since worked to photograph manuscripts in Middle Eastern countries.[9]
In South-Asia, the Nanakshahi trust is digitizing manuscripts of Gurmukhīscript.
In Australia, there have been many collaborative projects between the National Library of Australia and universities to improve the repository infrastructure that digitized information would be stored in.[10] Some of these projects include, the ARROW (Australian Research Repositories Online to the World) project and the APSR (Australian Partnership for Sustainable Repository) project.
Destructive scanning methods
For book scanning on a low budget, the least expensive method to scan a book or magazine is to cut off the binding. This converts the book or magazine into a sheaf of looseleaf papers, which can then be loaded into a standard automatic document feeder (ADF) and scanned using inexpensive and common scanning technology. While this is not a desirable solution for very old and uncommon books, it is a useful tool for book and magazine scanning where the book is not an expensive collector's item and replacement of the scanned content is easy. There are two technical difficulties with this process, first with the cutting and second with the scanning.
Unbinding
More precise and less destructive than cutting pages with a paper guillotine or razor or scissors is the technique of meticulous unbinding by hand, assisted with tools. This technique has been successfully employed for tens of thousands of pages of archival original paper scanned for the Riazanov Library digital archive project from newspapers and magazines and pamphlets, varying from 50 to 100 years old and more, and often composed of fragile, brittle paper. Although the monetary value for some collectors (and for most sellers of this sort of material) is destroyed by unbinding, unbinding in many cases actually greatly assists preservation of the physical pages themselves, making them more accessible to researchers and less likely to be damaged when subsequently examined. The down side is that unbound stacks of pages are "fluffed up", and therefore more exposed to oxygen in the air, which may in some cases (theoretically) speed deterioration. This can be addressed by putting weights on the pages after they are unbound, and storage in appropriate containers.
Hand unbinding will preserve text that runs into the gutters of bindings, and most critically allows more easy and complete high quality scans to be made of two page wide material, such as center cartoons, graphic art, and photos in magazines. The digital archive of The Liberator 1918-1924 on Marxist Internet Archive nicely demonstrates the quality of two page wide graphic art scans made possible by careful hand unbinding prior to flat bed or other scanning.
Unbinding techniques vary with the binding technology, from simply removing a few staples to unbending and removing nails to meticulously grinding down of layers of glue on the spine of a book to precisely the right point, followed by laborious removal of the string used to hold the book together.
Note that with some newspapers (such as Labor Action 1950-1952) there are columns on the center facing pages that run right in-between the pages. Chopping off part of the spine of a bound volume of such papers will lose part of this text. Even the Greenwood Reprint of this publication failed to preserve the text content of those center columns, cutting off significant amounts of text there. Only when bound volumes of the original newspaper were meticulously unbound, and the opened pair of center pages were scanned as a single page on a flat bed scanner was the center column content made digitally available. Alternatively, one can present the two facing center pages as three scans. One of each individual page, and one of a page sized area situated over the center of the two pages.
Cutting
One method of cutting a stack of 500 to 1000 pages in one pass is accomplished with a guillotine paper cutter. This is a large steel table with a paper vise that screws down onto the stack and firmly secures it before cutting. The cut is accomplished with a large sharpened steel blade which moves straight down and cuts the entire length of each sheet all at once. A lever on the blade permits several hundred pounds of force to be applied to the blade for a quick one-pass cut.
A clean cut through a thick stack of paper cannot be made with a traditional inexpensive sickle-shaped hinged paper cutter. These cutters are only intended for a few sheets, with up to ten sheets being the practical cutting limit. A large stack of paper applies torsional forces on the hinge, pulling the blade away from the cutting edge on the table. The cut becomes more inaccurate as the cut moves away from the hinge, and the force required to hold the blade against the cutting edge increases as the cut moves away from the hinge.
The guillotine cutting process dulls the blade over time, requiring that it be resharpened. Coated paper such as slick magazine paper dulls the blade more quickly than plain book paper, due to the kaolinite clay coating. Additionally, removing the binding of an entire hardcover book causes excessive wear due to cutting through the cover's stiff backing material. Instead the outer cover can be removed and only interior pages need be cut.
An alternate method of unbinding books is to use a table saw. While this method is potentially dangerous and does not leave as smooth an edge as the guillotine paper cutter method, it is more readily available to the average person. The ideal method is to clamp the book between two thick boards using heavy machine screws to provide the clamping force. The entire wood and book package is fed through the table saw using the rip fence as a guide. A sharp fine carbide tooth blade is ideal for generating an acceptable cut. The quality of the cut depends on the blade, feed rate, type of paper, paper coating, and binding material.
Scanning
Once the paper is liberated from the spine, it can be scanned one sheet at a time using a traditional flatbed scanner or automatic document feeder.
Pages with a decorative riffled edging or curving in an arc due to a non-flat binding can be difficult to scan using an ADF, as they are designed to scan pages of uniform shape and size, and variably sized or shaped pages can lead to improper scanning. The riffled edges or curved edge can be guillotined off to render the outer edges flat and smooth before the binding is cut.
The coated paper of magazines and bound textbooks can make them difficult for the rollers in an ADF to pick up and guide along the paper path. An ADF which uses a series of rollers and channels to flip sheets over may jam or misfeed when fed coated paper. Generally there are fewer problems by using as straight of a paper path as is possible, with few bends and curves. The clay can also rub off the paper over time and coat sticky pickup rollers, causing them to loosely grip the paper. The ADF rollers may need periodic cleaning to prevent this slipping.
Magazines can pose a bulk-scanning challenge due to small nonuniform sheets of paper in the stack, such as magazine subscription cards and fold out pages. These need to be removed before the bulk scan begins, and are either scanned separately if they include worthwhile content, or are simply left out of the scan process.
Non-destructive scanning

Software driven machines and robots have been developed to scan books without the need of unbinding them in order to preserve both the contents of the document and create a digital image archive of its current state. This recent trend has been due in part to ever improving imaging technologies that allow a high quality digital archive image to be captured with little or no damage to a rare or fragile book in a reasonably short period of time.
The first fully automated book scanner was the DL (Digitizing Line) scanner, manufactured by 4DigitalBooks in Switzerland. The first known installation was at Stanford University in 2001.[11][12] The scanner received a Dow Jones Runner-Up award under Business Applications Category in 2001.[13]
In 2007 the company TREVENTUS presented an automated book scanner with a book opening angle for scanning of 60°. Which is an improvement in the area of conservation of the books during scanning. The company was awarded with the European Union "ICT Grand Prize 2007",[14][15] for its development of the ScanRobot®. This technology was also used in a mass digitization project from the Bavarian State Library[16] where 8,900 books from the 16th century became digitized using three of these v-shape scanners within 18 months.

Indus International, Inc, based in West Salem, WI, produces scanners which were bought by some US entities for services like interlibrary loan.[17]
Most high-end commercial robotic scanners use traditional air and suction technology while some others use alternative approaches like bionic fingers for turning pages. Some scanners take advantage of ultrasonic sensors or photoelectric sensors to detect dual pages and prevent skipping of pages. With reports of machines being able to scan up to 2900 pages per hour,[18] robotic book scanners are specifically designed for large-scale digitization projects.
Google's patent 7508978 shows an infrared camera technology which allows detection and automatic adjustment of the three-dimensional shape of the page.[19][20] Researchers from the University of Tokyo have an experimental non-destructive book scanner[21] that includes a 3D surface scanner to allow images of a curved page to be straightened in software. Thus the book or magazine can be scanned as quickly as the operator can flip through the pages, about 200 pages per minute.
See also

References
- "DIY High-Speed Book Scanner from Trash and Cheap Cameras". instructables.com. Retrieved 19 January 2014.
- Taycher, Leonid (2010-08-05). "As of Aug 5, 2010, google estimates that there are 129,864,880 different books in the world". Googleblog.blogspot.co.at. Retrieved 2014-08-08.
- "North Carolina ECHO : Exploring Cultural Heritage Online". ncecho.org.
- Digital Libraries: Principles and Practice in a Global Environment, Ariadne April 2005.
- "Recollection Wisconsin". 29 November 2006.
- "Wisconsin Heritage Online [licensed for non-commercial use only] / FrontPage". pbworks.com.
- "Welcome to the Digital Library of Georgia". usg.edu.
- "GALILEO". usg.edu.
- "Codices decoded". The Economist. 18 December 2010. p. 151.
- Libraries in the twenty-first century: Charting new directions in information services. Edited by Stuart Ferguson, 2007, pg 84
- Davies, John. "4DigitalBooks launches digital book scanner". PrintWeek.
- "Stanford University Libraries (SUL) Robotic Book Scanner". Stanford University Libraries (SUL).
- "Technology Innovation Awards: Winners 2001". Dow Jones. Archived from the original on 2015-09-23. Retrieved 2017-08-07.
- "European Commission - PRESS RELEASES - Press release - British, Swedish and Austrian entrepreneurs win the EU's "Nobel prize" for ICT". europa.eu. Retrieved 2019-06-04.
- "Treventus ICT Grand price 2007". Treventus.
- "Bavarian State Library VD16 project" (PDF). Treventus. Archived from the original (PDF) on 2016-07-08. Retrieved 2019-06-04.
- Hope College (2012-09-06). "Meet the Library's New Scanner". Retrieved 2020-05-21.
- Rapp, David. "Product Watch: Library Scanners". Library Journal. Retrieved 11 May 2014.
- US 7508978, Lefevere, Francois-Marie & Marin Saric, "Detection of grooves in scanned images", issued March 24, 2009, assigned to Google
- The Secret Of Google's Book Scanning Machine Revealed, by Maureen Clements, April 30, 2009.
- Guizzo, Erico (2010-03-17). ""Superfast Scanner Lets You Digitize Book By Flipping Pages", IEEE Spectrum, March 17, 2010". Spectrum.ieee.org. Retrieved 2014-08-08.
External links
| Wikimedia Commons has media related to Book scanners. |
- Release of the first U.S. designed and manufactured planetary book scanner
- Do It Yourself book scanner device forum
- Google Open Source Linear Book Scanner
- Stanford University video shows some book scanning
- University of Tokyo high speed scanner
| Production | |
|---|---|
| Consumption | |
| By country | |
| Other |
|
| Related | |
| |
