Causal model
In philosophy of science, a causal model (or structural causal model) is a conceptual model that describes the causal mechanisms of a system. Causal models can improve study designs by providing clear rules for deciding which independent variables need to be included/controlled for.
They can allow some questions to be answered from existing observational data without the need for an interventional study such as a randomized controlled trial. Some interventional studies are inappropriate for ethical or practical reasons, meaning that without a causal model, some hypotheses cannot be tested.
Causal models can help with the question of external validity (whether results from one study apply to unstudied populations). Causal models can allow data from multiple studies to be merged (in certain circumstances) to answer questions that cannot be answered by any individual data set.
Causal models are falsifiable, in that if they do not match data, they must be rejected as invalid. They must also be credible to those close to the phenomena the model intends to explain.[2]
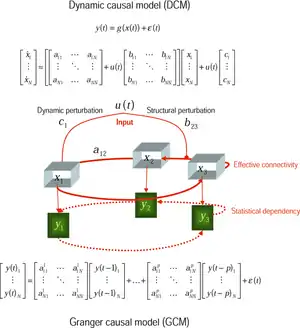
Causal models have found applications in signal processing, epidemiology and machine learning.[3]
Definition
Causal models are mathematical models representing causal relationships within an individual system or population. They facilitate inferences about causal relationships from statistical data. They can teach us a good deal about the epistemology of causation, and about the relationship between causation and probability. They have also been applied to topics of interest to philosophers, such as the logic of counterfactuals, decision theory, and the analysis of actual causation.[4]
— Stanford Encyclopedia of Philosophy
Judea Pearl defines a causal model as an ordered triple , where U is a set of exogenous variables whose values are determined by factors outside the model; V is a set of endogenous variables whose values are determined by factors within the model; and E is a set of structural equations that express the value of each endogenous variable as a function of the values of the other variables in U and V.[3]

History
Aristotle defined a taxonomy of causality, including material, formal, efficient and final causes. Hume rejected Aristotle's taxonomy in favor of counterfactuals. At one point, he denied that objects have "powers" that make one a cause and another an effect.[5]:264 Later he adopted "if the first object had not been, the second had never existed" ("but-for" causation).[5]:265
In the late 19th century, the discipline of statistics began to form. After a years-long effort to identify causal rules for domains such as biological inheritance, Galton introduced the concept of mean regression (epitomized by the sophomore slump in sports) which later led him to the non-causal concept of correlation.[5]
As a positivist, Pearson expunged the notion of causality from much of science as an unprovable special case of association and introduced the correlation coefficient as the metric of association. He wrote, "Force as a cause of motion is exactly the same as a tree god as a cause of growth" and that causation was only a "fetish among the inscrutable arcana of modern science". Pearson founded Biometrika and the Biometrics Lab at University College London, which became the world leader in statistics.[5]
In 1908 Hardy and Weinberg solved the problem of trait stability that had led Galton to abandon causality, by resurrecting Mendelian inheritance.[5]
In 1921 Wright's path analysis became the theoretical ancestor of causal modeling and causal graphs.[6] He developed this approach while attempting to untangle the relative impacts of heredity, development and environment on guinea pig coat patterns. He backed up his then-heretical claims by showing how such analyses could explain the relationship between guinea pig birth weight, in utero time and litter size. Opposition to these ideas by prominent statisticians led them to be ignored for the following 40 years (except among animal breeders). Instead scientists relied on correlations, partly at the behest of Wright's critic (and leading statistician), Fisher.[5] One exception was Burks, a student who in 1926 was the first to apply path diagrams to represent a mediating influence (mediator) and to assert that holding a mediator constant induces errors. She may have invented path diagrams independently.[5]:304
In 1923, Neyman introduced the concept of a potential outcome, but his paper was not translated from Polish to English until 1990.[5]:271
In 1958 Cox warned that controlling for a variable Z is valid only if it is highly unlikely to be affected by independent variables.[5]:154
In the 1960s, Duncan, Blalock, Goldberger and others rediscovered path analysis. While reading Blalock's work on path diagrams, Duncan remembered a lecture by Ogburn twenty years earlier that mentioned a paper by Wright that in turn mentioned Burks.[5]:308
Sociologists originally called causal models structural equation modeling, but once it became a rote method, it lost its utility, leading some practitioners to reject any relationship to causality. Economists adopted the algebraic part of path analysis, calling it simultaneous equation modeling. However, economists still avoided attributing causal meaning to their equations.[5]
Sixty years after his first paper, Wright published a piece that recapitulated it, following Karlin et al.'s critique, which objected that it handled only linear relationships and that robust, model-free presentations of data were more revealing.[5]
In 1973 Lewis advocated replacing correlation with but-for causality (counterfactuals). He referred to humans' ability to envision alternative worlds in which a cause did or not occur and in which effect an appeared only following its cause.[5]:266 In 1974 Rubin introduced the notion of "potential outcomes" as a language for asking causal questions.[5]:269
In 1983 Cartwright proposed that any factor that is "causally relevant" to an effect be conditioned on, moving beyond simple probability as the only guide.[5]:48
In 1986 Baron and Kenny introduced principles for detecting and evaluating mediation in a system of linear equations. As of 2014 their paper was the 33rd most-cited of all time.[5]:324 That year Greenland and Robins introduced the "exchangeability" approach to handling confounding by considering a counterfactual. They proposed assessing what would have happened to the treatment group if they had not received the treatment and comparing that outcome to that of the control group. If they matched, confounding was said to be absent.[5]:154
Columbia University operates the Causal Artificial Intelligence Lab which is attempting to connect causal modeling theory to artificial neural networks.[7]
Ladder of causation
Pearl's causal metamodel involves a three-level abstraction he calls the ladder of causation. The lowest level, Association (seeing/observing), entails the sensing of regularities or patterns in the input data, expressed as correlations. The middle level, Intervention (doing), predicts the effects of deliberate actions, expressed as causal relationships. The highest level, Counterfactuals (imagining), involves constructing a theory of (part of) the world that explains why specific actions have specific effects and what happens in the absence of such actions.[5]
Association
One object is associated with another if observing one changes the probability of observing the other. Example: shoppers who buy toothpaste are more likely to also buy dental floss. Mathematically:

or the probability of (purchasing) floss given (the purchase of) toothpaste. Associations can also be measured via computing the correlation of the two events. Associations have no causal implications. One event could cause the other, the reverse could be true, or both events could be caused by some third event (unhappy hygenist shames shopper into treating their mouth better ).[5]
Intervention
This level asserts specific causal relationships between events. Causality is assessed by experimentally performing some action that affects one of the events. Example: if we doubled the price of toothpaste, what would be the new probability of purchasing? Causality cannot be established by examining history (of price changes) because the price change may have been for some other reason that could itself affect the second event (a tariff that increases the price of both goods). Mathematically:

where do is an operator that signals the experimental intervention (doubling the price).[5] The operator indicates performing the minimal change in the world necessary to create the intended effect, a "mini-surgery" on the model with as little change from reality as possible.[8]
Counterfactuals
The highest level, counterfactual, involves consideration of an alternate version of a past event, or what would happen under different circumstances for the same experimental unit. For example, what is the probability that, if a store had doubled the price of floss, the toothpaste-purchasing shopper would still have bought it?

Counterfactuals can indicate the existence of a causal relationship. Models that can answer counterfactuals allow precise interventions whose consequences can be predicted. At the extreme, such models are accepted as physical laws (as in the laws of physics, e.g., inertia, which says that if force is not applied to a stationary object, it will not move).[5]
Causality
Causality vs correlation
Statistics revolves around the analysis of relationships among multiple variables. Traditionally, these relationships are described as correlations, associations without any implied causal relationships. Causal models attempt to extend this framework by adding the notion of causal relationships, in which changes in one variable cause changes in others.[3]
Twentieth century definitions of causality relied purely on probabilities/associations. One event (X) was said to cause another if it raises the probability of the other (Y). Mathematically this is expressed as:
- .

Such definitions are inadequate because other relationships (e.g., a common cause for X and Y) can satisfy the condition. Causality is relevant to the second ladder step. Associations are on the first step and provide only evidence to the latter.[5]
A later definition attempted to address this ambiguity by conditioning on background factors. Mathematically:
- ,

where K is the set of background variables and k represents the values of those variables in a specific context. However, the required set of background variables is indeterminate (multiple sets may increase the probability), as long as probability is the only criterion.[5]
Other attempts to define causality include Granger causality, a statistical hypothesis test that causality (in economics) can be assessed by measuring the ability to predict the future values of one time series using prior values of another time series.[5]
Types
A cause can be necessary, sufficient, contributory or some combination.[9]
Necessary
For x to be a necessary cause of y, the presence of y must imply the prior occurrence of x. The presence of x, however, does not imply that y will occur.[10] Necessary causes are also known as "but-for" causes, as in y would not have occurred but for the occurrence of x.[5]:261
Sufficient causes
For x to be a sufficient cause of y, the presence of x must imply the subsequent occurrence of y. However, another cause z may independently cause y. Thus the presence of y does not require the prior occurrence of x.[10]
Contributory causes
For x to be a contributory cause of y, the presence of x must increase the likelihood of y. If the likelihood is 100%, then x is instead called sufficient. A contributory cause may also be necessary.[11]
Model
Causal diagram
A causal diagram is a directed graph that displays causal relationships between variables in a causal model. A causal diagram includes a set of variables (or nodes). Each node is connected by an arrow to one or more other nodes upon which it has a causal influence. An arrowhead delineates the direction of causality, e.g., an arrow connecting variables A and B with the arrowhead at B indicates that a change in A causes a change in B (with an associated probability). A path is a traversal of the graph between two nodes following causal arrows.[5]
Causal diagrams include causal loop diagrams, directed acyclic graphs, and Ishikawa diagrams.[5]
Causal diagrams are independent of the quantitative probabilities that inform them. Changes to those probabilities (e.g., due to technological improvements) do not require changes to the model.[5]
Model elements
Causal models have formal structures with elements with specific properties.[5]
Junction patterns
The three types of connections of three nodes are linear chains, branching forks and merging colliders.[5]
Chain
Chains are straight line connections with arrows pointing from cause to effect. In this model, B is a mediator in that it mediates the change that A would otherwise have on C.[5]:113

Fork
In forks, one cause has multiple effects. The two effects have a common cause. There exists a (non-causal) spurious correlation between A and C that can be eliminated by conditioning on B (for a specific value of B).[5]:114

"Conditioning on B" means "given B" (i.e., given a value of B).
An elaboration of a fork is the confounder:

In such models, B is a common cause of A and C (which also causes A), making B the confounder.[5]:114
Collider
In colliders, multiple causes affect one outcome. Conditioning on B (for a specific value of B) often reveals a non-causal negative correlation between A and C. This negative correlation has been called collider bias and the "explain-away" effect as in, B explains away the correlation between A and C.[5]:115 The correlation can be positive in the case where contributions from both A and C are necessary to affect B.[5]:197

Mediator
A mediator node modifies the effect of other causes on an outcome (as opposed to simply affecting the outcome).[5]:113 For example, in the chain example above, B is a mediator, because it modifies the effect of A (an indirect cause of C) on C (the outcome).
Confounder
A confounder node affects multiple outcomes, creating a positive correlation among them.[5]:114
Instrumental variable
An instrumental variable is one that:[5]:246
- has a path to the outcome
- has no other path to causal variables
- has no direct influence on the outcome
Regression coefficients can serve as estimates of the causal effect of an instrumental variable on an outcome as long as that effect is not confounded. In this way, instrumental variables allow causal factors to be quantified without data on confounders.[5]:249
For example, given the model:

Z is an instrumental variable, because it has a path to the outcome Y and is unconfounded, e.g., by U.
In the above example, if Z and X take binary values, then the assumption that Z = 0, X = 1 does not occur is called monotonicity.[5]:253
Refinements to the technique include creating an instrument by conditioning on other variable to block the paths between the instrument and the confounder and combining multiple variables to form a single instrument.[5]:257
Mendelian randomization
Definition: Mendelian randomization uses measured variation in genes of known function to examine the causal effect of a modifiable exposure on disease in observational studies.[12][13]
Because genes vary randomly across populations, presence of a gene typically qualifies as an instrumental variable, implying that in many cases, causality can be quantified using regression on an observational study.[5]:255
Associations
Independence conditions
Independence conditions are rules for deciding whether two variables are independent of each other. Variables are independent if the values of one do not directly affect the values of the other. Multiple causal models can share independence conditions. For example, the models
and
have the same independence conditions, because conditioning on B leaves A and C independent. However, the two models do not have the same meaning and can be falsified based on data (that is, if observational data show an association between A and C after conditioning on B, then both models are incorrect). Conversely, data cannot show which of these two models are correct, because they have the same independence conditions.
Conditioning on a variable is a mechanism for conducting hypothetical experiments. Conditioning on a variable involves analyzing the values of other variables for a given value of the conditioned variable. In the first example, conditioning on B implies that observations for a given value of B should show no dependence between A and C. If such a dependence exists, then the model is incorrect. Non-causal models cannot make such distinctions, because they do not make causal assertions.[5]:129–130
Confounder/deconfounder
An essential element of correlational study design is to identify potentially confounding influences on the variable under study, such as demographics. These variables are controlled for to eliminate those influences. However, the correct list of confounding variables cannot be determined a priori. It is thus possible that a study may control for irrelevant variables or even (indirectly) the variable under study.[5]:139
Causal models offer a robust technique for identifying appropriate confounding variables. Formally, Z is a confounder if "Y is associated with Z via paths not going through X". These can often be determined using data collected for other studies. Mathematically, if

then X is a confounder for Y.[5]:151
Earlier, allegedly incorrect definitions include:[5]:152
- "Any variable that is correlated with both X and Y."
- Y is associated with Z among the unexposed.
- Noncollapsibility: A difference between the "crude relative risk and the relative risk resulting after adjustment for the potential confounder".
- Epidemiological: A variable associated with X in the population at large and associated with Y among people unexposed to X.
The latter is flawed in that given that in the model:

Z matches the definition, but is a mediator, not a confounder, and is an example of controlling for the outcome.
In the model

Traditionally, B was considered to be a confounder, because it is associated with X and with Y but is not on a causal path nor is it a descendant of anything on a causal path. Controlling for B causes it to become a confounder. This is known as M-bias.[5]:161
Backdoor adjustment
For analysing the causal effect of X on Y in a causal model we need to adjust for all confounder variables (deconfounding). To identify the set of confounders we need to (1) block every noncausal path between X and Y by this set (2) without disrupting any causal paths and (3) without creating any spurious paths.[5]:158
Definition: a backdoor path from variable X to Y is any path from X to Y that starts with an arrow pointing to X.[5]:158
Definition: Given an ordered pair of variables (X,Y) in a model, a set of confounder variables Z satisfies the backdoor criterion if (1) no confounder variable Z is a descendent of X and (2) all backdoor paths between X and Y are blocked by the set of confounders.
If the backdoor criterion is satisfied for (X,Y), X and Y are deconfounded by the set of confounder variables. It is not necessary to control for any variables other than the confounders.[5]:158 The backdoor criterion is a sufficient but not necessary condition to find a set of variables Z to decounfound the analysis of the causal effect of X on y.
When the causal model is a plausible representation of reality and the backdoor criterion is satisfied, then partial regression coefficients can be used as (causal) path coefficients (for linear relationships).[5]:223 [14]

Frontdoor adjustment
Definition: a frontdoor path is a direct causal path for which data is available for all variables.[5]:226
The following converts a do expression into a do-free expression by conditioning on the variables along the front-door path.[5]:226

Presuming data for these observable probabilities is available, the ultimate probability can be computed without an experiment, regardless of the existence of other confounding paths and without backdoor adjustment.[5]:226
Interventions
Queries
Queries are questions asked based on a specific model. They are generally answered via performing experiments (interventions). Interventions take the form of fixing the value of one variable in a model and observing the result. Mathematically, such queries take the form (from the example):[5]:8

where the do operator indicates that the experiment explicitly modified the price of toothpaste. Graphically, this blocks any causal factors that would otherwise affect that variable. Diagramatically, this erases all causal arrows pointing at the experimental variable.[5]:40
More complex queries are possible, in which the do operator is applied (the value is fixed) to multiple variables.
Do calculus
The do calculus is the set of manipulations that are available to transform one expression into another, with the general goal of transforming expressions that contain the do operator into expressions that do not. Expressions that do not include the do operator can be estimated from observational data alone, without the need for an experimental intervention, which might be expensive, lengthy or even unethical (e.g., asking subjects to take up smoking).[5]:231 The set of rules is complete (it can be used to derive every true statement in this system).[5]:237 An algorithm can determine whether, for a given model, a solution is computable in polynomial time.[5]:238
Rules
The calculus includes three rules for the transformation of conditional probability expressions involving the do operator.
Rule 1
Rule 1 permits the addition or deletion of observations.:[5]:235

in the case that the variable set Z blocks all paths from W to Y and all arrows leading into X have been deleted.[5]:234
Rule 2
Rule 2 permits the replacement of an intervention with an observation or vice versa.:[5]:235

in the case that Z satisfies the back-door criterion.[5]:234
Rule 3
Rule 3 permits the deletion or addition of interventions.:[5]

in the case where no causal paths connect X and Y.[5]:234 :235
Extensions
The rules do not imply that any query can have its do operators removed. In those cases, it may be possible to substitute a variable that is subject to manipulation (e.g., diet) in place of one that is not (e.g., blood cholesterol), which can then be transformed to remove the do. Example:

Counterfactuals
Counterfactuals consider possibilities that are not found in data, such as whether a nonsmoker would have developed cancer had they instead been a heavy smoker. They are the highest step on Pearl's causality ladder.
Potential outcome
Definition: A potential outcome for a variable Y is "the value Y would have taken for individual u, had X been assigned the value x". Mathematically:[5]:270
- or .


The potential outcome is defined at the level of the individual u.[5]:270
The conventional approach to potential outcomes is data-, not model-driven, limiting its ability to untangle causal relationships. It treats causal questions as problems of missing data and gives incorrect answers to even standard scenarios.[5]:275
Causal inference
In the context of causal models, potential outcomes are interpreted causally, rather than statistically.
The first law of causal inference states that the potential outcome

can be computed by modifying causal model M (by deleting arrows into X) and computing the outcome for some x. Formally:[5]:280

Conducting a counterfactual
Examining a counterfactual using a causal model involves three steps.[15] The approach is valid regardless of the form of the model relationships, linear or otherwise. When the model relationships are fully specified, point values can be computed. In other cases (e.g., when only probabilities are available) a probability-interval statement, such as non-smoker x would have a 10-20% chance of cancer, can be computed.[5]:279
Given the model:

the equations for calculating the values of A and C derived from regression analysis or another technique can be applied, substituting known values from an observation and fixing the value of other variables (the counterfactual).[5]:278
Abduct
Apply abductive reasoning (logical inference that uses observation to find the simplest/most likely explanation) to estimate u, the proxy for the unobserved variables on the specific observation that supports the counterfactual.[5]:278 Compute the probability of u given the propositional evidence.
Act
For a specific observation, use the do operator to establish the counterfactual (e.g., m=0), modifying the equations accordingly.[5]:278
Mediation
Direct and indirect (mediated) causes can only be distinguished via conducting counterfactuals.[5]:301 Understanding mediation requires holding the mediator constant while intervening on the direct cause. In the model

M mediates X's influence on Y, while X also has an unmediated effect on Y. Thus M is held constant, while do(X) is computed.
The Mediation Fallacy instead involves conditioning on the mediator if the mediator and the outcome are confounded, as they are in the above model.
For linear models, the indirect effect can be computed by taking the product of all the path coefficients along a mediated pathway. The total indirect effect is computed by the sum of the individual indirect effects. For linear models mediation is indicated when the coefficients of an equation fitted without including the mediator vary significantly from an equation that includes it.[5]:324
Direct effect
In experiments on such a model, the controlled direct effect (CDE) is computed by forcing the value of the mediator M (do(M = 0)) and randomly assigning some subjects to each of the values of X (do(X=0), do(X=1), ...) and observing the resulting values of Y.[5]:317

Each value of the mediator has a corresponding CDE.
However, a better experiment is to compute the natural direct effect. (NDE) This is the effect determined by leaving the relationship between X and M untouched while intervening on the relationship between X and Y.[5]:318

For example, consider the direct effect of increasing dental hygenist visits (X) from every other year to every year, which encourages flossing (M). Gums (Y) get healthier, either because of the hygenist (direct) or the flossing (mediator/indirect). The experiment is to continue flossing while skipping the hygenist visit.
Indirect effect
The indirect effect of X on Y is the "increase we would see in Y while holding X constant and increasing M to whatever value M would attain under a unit increase in X".[5]:328
Indirect effects cannot be "controlled" because the direct path cannot be disabled by holding another variable constant. The natural indirect effect (NIE) is the effect on gum health (Y) from flossing (M). The NIE is calculated as the sum of (floss and no-floss cases) of the difference between the probability of flossing given the hygenist and without the hygenist, or:[5]:321

The above NDE calculation includes counterfactual subscripts (). For nonlinear models, the seemingly obvious equivalence[5]:322


does not apply because of anomalies such as threshold effects and binary values. However,

works for all model relationships (linear and nonlinear). It allows NDE to then be calculated directly from observational data, without interventions or use of counterfactual subscripts.[5]:326
Transportability
Causal models provide a vehicle for integrating data across datasets, known as transport, even though the causal models (and the associated data) differ. E.g., survey data can be merged with randomized, controlled trial data.[5]:352 Transport offers a solution to the question of external validity, whether a study can be applied in a different context.
Where two models match on all relevant variables and data from one model is known to be unbiased, data from one population can be used to draw conclusions about the other. In other cases, where data is known to be biased, reweighting can allow the dataset to be transported. In a third case, conclusions can be drawn from an incomplete dataset. In some cases, data from studies of multiple populations can be combined (via transportation) to allow conclusions about an unmeasured population. In some cases, combining estimates (e.g., P(W|X)) from multiple studies can increase the precision of a conclusion.[5]:355
Do-calculus provides a general criterion for transport: A target variable can be transformed into another expression via a series of do-operations that does not involve any "difference-producing" variables (those that distinguish the two populations).[5]:355 An analogous rule applies to studies that have relevantly different participants.[5]:356
Bayesian network
Any causal model can be implemented as a Bayesian network. Bayesian networks can be used to provide the inverse probability of an event (given an outcome, what are the probabilities of a specific cause). This requires preparation of a conditional probability table, showing all possible inputs and outcomes with their associated probabilities.[5]:119
For example, given a two variable model of Disease and Test (for the disease) the conditional probability table takes the form:[5]:117
| Test | ||
|---|---|---|
| Disease | Positive | Negative |
| Negative | 12 | 88 |
| Positive | 73 | 27 |
According to this table, when a patient does not have the disease, the probability of a positive test is 12%.
While this is tractable for small problems, as the number of variables and their associated states increase, the probability table (and associated computation time) increases exponentially.[5]:121
Bayesian networks are used commercially in applications such as wireless data error correction and DNA analysis.[5]:122
Invariants/context
A different conceptualization of causality involves the notion of invariant relationships. In the case of identifying handwritten digits, digit shape controls meaning, thus shape and meaning are the invariants. Changing the shape changes the meaning. Other properties do not (e.g., color). This invariance should carry across datasets generated in different contexts (the non-invariant properties form the context). Rather than learning (assessing causality) using pooled data sets, learning on one and testing on another can help distinguish variant from invariant properties.[16]
See also
- Causal network – a Bayesian network with an explicit requirement that the relationships be causal
- Structural equation modeling – a statistical technique for testing and estimating causal relations
- Path analysis (statistics)
- Bayesian network
References
- Karl Friston (Feb 2009). "Causal Modelling and Brain Connectivity in Functional Magnetic Resonance Imaging". PLOS Biology. 7 (2): e1000033. doi:10.1371/journal.pbio.1000033. PMC 2642881. PMID 19226186.
- Barlas, Yaman; Carpenter, Stanley (1990). "Philosophical roots of model validation: Two paradigms". System Dynamics Review. 6 (2): 148–166. doi:10.1002/sdr.4260060203.
- Pearl 2009
- Hitchcock, Christopher (2018), "Causal Models", in Zalta, Edward N. (ed.), The Stanford Encyclopedia of Philosophy (Fall 2018 ed.), Metaphysics Research Lab, Stanford University, retrieved 2018-09-08
- Pearl, Judea; Mackenzie, Dana (2018-05-15). The Book of Why: The New Science of Cause and Effect. Basic Books. ISBN 9780465097616.
- Okasha, Samir (2012-01-12). "Causation in Biology". In Beebee, Helen; Hitchcock, Christopher; Menzies, Peter (eds.). The Oxford Handbook of Causation. 1. OUP Oxford. doi:10.1093/oxfordhb/9780199279739.001.0001. ISBN 9780191629464.
- Bergstein, Brian. "What AI still can't do". MIT Technology Review. Retrieved 2020-02-20.
- Pearl, Judea (29 Oct 2019). "Causal and Counterfactual Inference" (PDF). Retrieved 14 December 2020. Cite journal requires
|journal=(help) - Epp, Susanna S. (2004). Discrete Mathematics with Applications. Thomson-Brooks/Cole. pp. 25–26. ISBN 9780534359454.
- "Causal Reasoning". www.istarassessment.org. Retrieved 2 March 2016.
- Riegelman, R. (1979). "Contributory cause: Unnecessary and insufficient". Postgraduate Medicine. 66 (2): 177–179. doi:10.1080/00325481.1979.11715231. PMID 450828.
- Katan MB (March 1986). "Apolipoprotein E isoforms, serum cholesterol, and cancer". Lancet. 1 (8479): 507–8. doi:10.1016/s0140-6736(86)92972-7. PMID 2869248. S2CID 38327985.
- Smith, George Davey; Ebrahim, Shah (2008). Mendelian Randomization: Genetic Variants as Instruments for Strengthening Causal Inference in Observational Studies. National Academies Press (US).
- Pearl 2009, chapter 3-3 Controlling Confounding Bias
- Pearl, Judea (2009). Causality. Cambridge: Cambridge University Press. p. 207. ISBN 978-0-511-80316-1.
- Hao, Karen (May 8, 2019). "Deep learning could reveal why the world works the way it does". MIT Technology Review. Retrieved February 10, 2020.
External links
- Pearl, Judea (2010-02-26). "An Introduction to Causal Inference". The International Journal of Biostatistics. 6 (2): Article 7. doi:10.2202/1557-4679.1203. ISSN 1557-4679. PMC 2836213. PMID 20305706.
- Causal modeling at PhilPapers
- Falk, Dan (2019-03-17). "AI Algorithms Are Now Shockingly Good at Doing Science". Wired. ISSN 1059-1028. Retrieved 2019-03-20.
- Maudlin, Tim (2019-08-30). "The Why of the World". Boston Review. Retrieved 2019-09-09.
- Hartnett, Kevin. "To Build Truly Intelligent Machines, Teach Them Cause and Effect". Quanta Magazine. Retrieved 2019-09-19.
- [1]
- Learning Representations using Causal Invariance, ICLR, February 2020, retrieved 2020-02-10
