Palindromic sequence
A palindromic sequence is a nucleic acid sequence in a double-stranded DNA or RNA molecule wherein reading in a certain direction (e.g. 5' to 3') on one strand matches the sequence reading in the opposite direction (e.g. 5' to 3') on the complementary strand. This definition of palindrome thus depends on complementary strands being palindromic of each other.
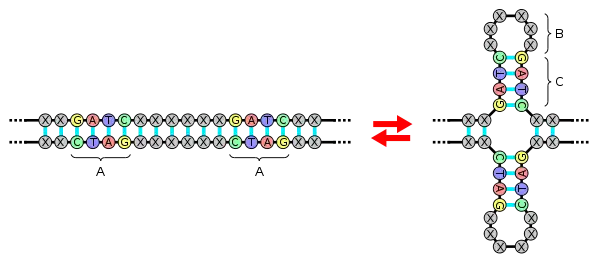
A: Palindrome, B: Loop, C: Stem
The meaning of palindrome in the context of genetics is slightly different from the definition used for words and sentences. Since a double helix is formed by two paired antiparallel strands of nucleotides that run in opposite directions, and the nucleotides always pair in the same way (adenine (A) with thymine (T) in DNA or uracil (U) in RNA; cytosine (C) with guanine (G)), a (single-stranded) nucleotide sequence is said to be a palindrome if it is equal to its reverse complement. For example, the DNA sequence ACCTAGGT is palindromic because its nucleotide-by-nucleotide complement is TGGATCCA, and reversing the order of the nucleotides in the complement gives the original sequence.
A palindromic nucleotide sequence is capable of forming a hairpin. The stem portion of the hairpin is a pseudo-double stranded portion since the entire hairpin is a part of same (single) strand of nucleic acid. Palindromic motifs are found in most genomes or sets of genetic instructions. They have been specially researched in bacterial chromosomes and in the so-called Bacterial Interspersed Mosaic Elements (BIMEs) scattered over them. In 2008, a genome sequencing project discovered that large portions of the human X and Y chromosomes are arranged as palindromes.[1] A palindromic structure allows the Y chromosome to repair itself by bending over at the middle if one side is damaged.
Palindromes also appear to be found frequently in the peptide sequences that make up proteins,[2][3] but their role in protein function is not clearly known. It has been suggested that the existence of palindromes in peptides might be related to the prevalence of low-complexity regions in proteins, as palindromes are frequently associated with low-complexity sequences. Their prevalence may also be related to the propensity of such sequences to form alpha helices[4] or protein/protein complexes.[5]
Examples
Restriction enzyme sites
Palindromic sequences play an important role in molecular biology. Because a DNA sequence is double stranded, the base pairs are read, (not just the bases on one strand), to determine a palindrome. Many restriction endonucleases (restriction enzymes) recognize specific palindromic sequences and cut them. The restriction enzyme EcoR1 recognizes the following palindromic sequence:
5'- G A A T T C -3' 3'- C T T A A G -5'
The top strand reads 5'-GAATTC-3', while the bottom strand reads 3'-CTTAAG-5'. If the DNA strand is flipped over, the sequences are exactly the same (5'GAATTC-3' and 3'-CTTAAG-5'). Here are more restriction enzymes and the palindromic sequences which they recognize:
| Enzyme | Source | Recognition Sequence | Cut |
|---|---|---|---|
| EcoR1 | Escherichia coli |
5'GAATTC 3'CTTAAG |
5'---G AATTC---3' 3'---CTTAA G---5' |
| BamH1 | Bacillus amyloliquefaciens |
5'GGATCC 3'CCTAGG |
5'---G GATCC---3' 3'---CCTAG G---5' |
| Taq1 | Thermus aquaticus |
5'TCGA 3'AGCT |
5'---T CGA---3' 3'---AGC T---5' |
| Alu1* | Arthrobacter luteus |
5'AGCT 3'TCGA |
5'---AG CT---3' 3'---TC GA---5' |
| * = blunt ends | |||
Methylation sites
Palindromic sequences may also have methylation sites. These are the sites where a methyl group can be attached to the palindromic sequence. Methylation makes the resistant gene inactive; this is called insertional inactivation or insertional mutagenesis. For example, in PBR322 methylation at the tetracyclin resistant gene makes the plasmid liable to tetracyclin; after methylation at the tetracyclin resistant gene if the plasmid is exposed to antibiotic tetracyclin, it does not survive.
Palindromic nucleotides in T cell receptors
Diversity of T cell receptor (TCR) genes is generated by nucleotide insertions upon V(D)J recombination from their germline-encoded V, D and J segments. Nucleotide insertions at V-D and D-J junctions are random, but some small subsets of these insertions are exceptional, in that one to three base pairs inversely repeat the sequence of the germline DNA. These short complementary palindromic sequences are called P nucleotides.[6]
References
- Larionov S, Loskutov A, Ryadchenko E (February 2008). "Chromosome evolution with naked eye: palindromic context of the life origin". Chaos. 18 (1): 013105. doi:10.1063/1.2826631. PMID 18377056.
- Ohno S (1990). "Intrinsic evolution of proteins. The role of peptidic palindromes". Riv. Biol. 83 (2–3): 287–91, 405–10. PMID 2128128.
- Giel-Pietraszuk M, Hoffmann M, Dolecka S, Rychlewski J, Barciszewski J (February 2003). "Palindromes in proteins" (PDF). J. Protein Chem. 22 (2): 109–13. doi:10.1023/A:1023454111924. PMID 12760415.
- Sheari A, Kargar M, Katanforoush A, et al. (2008). "A tale of two symmetrical tails: structural and functional characteristics of palindromes in proteins". BMC Bioinformatics. 9: 274. doi:10.1186/1471-2105-9-274. PMC 2474621. PMID 18547401.
- Pinotsis N, Wilmanns M (October 2008). "Protein assemblies with palindromic structure motifs". Cell. Mol. Life Sci. 65 (19): 2953–6. doi:10.1007/s00018-008-8265-1. PMID 18791850.
- Srivastava, SK; Robins, HS (2012). "Palindromic nucleotide analysis in human T cell receptor rearrangements". PLOS One. 7 (12): e52250. doi:10.1371/journal.pone.0052250. PMC 3528771. PMID 23284955.
