Supercomputer architecture
Approaches to supercomputer architecture have taken dramatic turns since the earliest systems were introduced in the 1960s. Early supercomputer architectures pioneered by Seymour Cray relied on compact innovative designs and local parallelism to achieve superior computational peak performance.[1] However, in time the demand for increased computational power ushered in the age of massively parallel systems.

While the supercomputers of the 1970s used only a few processors, in the 1990s, machines with thousands of processors began to appear and by the end of the 20th century, massively parallel supercomputers with tens of thousands of "off-the-shelf" processors were the norm. Supercomputers of the 21st century can use over 100,000 processors (some being graphic units) connected by fast connections.[2][3]
Throughout the decades, the management of heat density has remained a key issue for most centralized supercomputers.[4][5][6] The large amount of heat generated by a system may also have other effects, such as reducing the lifetime of other system components.[7] There have been diverse approaches to heat management, from pumping Fluorinert through the system, to a hybrid liquid-air cooling system or air cooling with normal air conditioning temperatures.[8][9]
Systems with a massive number of processors generally take one of two paths: in one approach, e.g., in grid computing the processing power of a large number of computers in distributed, diverse administrative domains, is opportunistically used whenever a computer is available.[10] In another approach, a large number of processors are used in close proximity to each other, e.g., in a computer cluster. In such a centralized massively parallel system the speed and flexibility of the interconnect becomes very important, and modern supercomputers have used various approaches ranging from enhanced Infiniband systems to three-dimensional torus interconnects.[11][12]
Context and overview
Since the late 1960s the growth in the power and proliferation of supercomputers has been dramatic, and the underlying architectural directions of these systems have taken significant turns. While the early supercomputers relied on a small number of closely connected processors that accessed shared memory, the supercomputers of the 21st century use over 100,000 processors connected by fast networks.[2][3]
Throughout the decades, the management of heat density has remained a key issue for most centralized supercomputers.[4] Seymour Cray's "get the heat out" motto was central to his design philosophy and has continued to be a key issue in supercomputer architectures, e.g., in large-scale experiments such as Blue Waters.[4][5][6] The large amount of heat generated by a system may also have other effects, such as reducing the lifetime of other system components.[7]

There have been diverse approaches to heat management, e.g., the Cray 2 pumped Fluorinert through the system, while System X used a hybrid liquid-air cooling system and the Blue Gene/P is air-cooled with normal air conditioning temperatures.[8][13][14] The heat from the Aquasar supercomputer is used to warm a university campus.[15][16]
The heat density generated by a supercomputer has a direct dependence on the processor type used in the system, with more powerful processors typically generating more heat, given similar underlying semiconductor technologies.[7] While early supercomputers used a few fast, closely packed processors that took advantage of local parallelism (e.g., pipelining and vector processing), in time the number of processors grew, and computing nodes could be placed further away,e.g., in a computer cluster, or could be geographically dispersed in grid computing.[2][17] As the number of processors in a supercomputer grows, "component failure rate" begins to become a serious issue. If a supercomputer uses thousands of nodes, each of which may fail once per year on the average, then the system will experience several node failures each day.[9]
As the price/performance of general purpose graphic processors (GPGPUs) has improved, a number of petaflop supercomputers such as Tianhe-I and Nebulae have started to rely on them.[18] However, other systems such as the K computer continue to use conventional processors such as SPARC-based designs and the overall applicability of GPGPUs in general purpose high performance computing applications has been the subject of debate, in that while a GPGPU may be tuned to score well on specific benchmarks its overall applicability to everyday algorithms may be limited unless significant effort is spent to tune the application towards it.[19] However, GPUs are gaining ground and in 2012 the Jaguar supercomputer was transformed into Titan by replacing CPUs with GPUs.[20][21][22]
As the number of independent processors in a supercomputer increases, the way they access data in the file system and how they share and access secondary storage resources becomes prominent. Over the years a number of systems for distributed file management were developed, e.g., the IBM General Parallel File System, BeeGFS, the Parallel Virtual File System, Hadoop, etc.[23][24] A number of supercomputers on the TOP100 list such as the Tianhe-I use Linux's Lustre file system.[4]
Early systems with a few processors
The CDC 6600 series of computers were very early attempts at supercomputing and gained their advantage over the existing systems by relegating work to peripheral devices, freeing the CPU (Central Processing Unit) to process actual data. With the Minnesota FORTRAN compiler the 6600 could sustain 500 kiloflops on standard mathematical operations.[25]

Other early supercomputers such as the Cray 1 and Cray 2 that appeared afterwards used a small number of fast processors that worked in harmony and were uniformly connected to the largest amount of shared memory that could be managed at the time.[3]
These early architectures introduced parallel processing at the processor level, with innovations such as vector processing, in which the processor can perform several operations during one clock cycle, rather than having to wait for successive cycles.
In time, as the number of processors increased, different architectural issues emerged. Two issues that need to be addressed as the number of processors increases are the distribution of memory and processing. In the distributed memory approach, each processor is physically packaged close with some local memory. The memory associated with other processors is then "further away" based on bandwidth and latency parameters in non-uniform memory access.
In the 1960s pipelining was viewed as an innovation, and by the 1970s the use of vector processors had been well established. By the 1980s, many supercomputers used parallel vector processors.[2]
The relatively small number of processors in early systems, allowed them to easily use a shared memory architecture, which allows processors to access a common pool of memory. In the early days a common approach was the use of uniform memory access (UMA), in which access time to a memory location was similar between processors. The use of non-uniform memory access (NUMA) allowed a processor to access its own local memory faster than other memory locations, while cache-only memory architectures (COMA) allowed for the local memory of each processor to be used as cache, thus requiring coordination as memory values changed.[26]
As the number of processors increases, efficient interprocessor communication and synchronization on a supercomputer becomes a challenge. A number of approaches may be used to achieve this goal. For instance, in the early 1980s, in the Cray X-MP system, shared registers were used. In this approach, all processors had access to shared registers that did not move data back and forth but were only used for interprocessor communication and synchronization. However, inherent challenges in managing a large amount of shared memory among many processors resulted in a move to more distributed architectures.[27]
Massive centralized parallelism

During the 1980s, as the demand for computing power increased, the trend to a much larger number of processors began, ushering in the age of massively parallel systems, with distributed memory and distributed file systems, given that shared memory architectures could not scale to a large number of processors.[2][28] Hybrid approaches such as distributed shared memory also appeared after the early systems.[29]
The computer clustering approach connects a number of readily available computing nodes (e.g. personal computers used as servers) via a fast, private local area network.[30] The activities of the computing nodes are orchestrated by "clustering middleware", a software layer that sits atop the nodes and allows the users to treat the cluster as by and large one cohesive computing unit, e.g. via a single system image concept.[30]
Computer clustering relies on a centralized management approach which makes the nodes available as orchestrated shared servers. It is distinct from other approaches such as peer to peer or grid computing which also use many nodes, but with a far more distributed nature.[30] By the 21st century, the TOP500 organization's semiannual list of the 500 fastest supercomputers often includes many clusters, e.g. the world's fastest in 2011, the K computer with a distributed memory, cluster architecture.[31][32]
When a large number of local semi-independent computing nodes are used (e.g. in a cluster architecture) the speed and flexibility of the interconnect becomes very important. Modern supercomputers have taken different approaches to address this issue, e.g. Tianhe-1 uses a proprietary high-speed network based on the Infiniband QDR, enhanced with FeiTeng-1000 CPUs.[4] On the other hand, the Blue Gene/L system uses a three-dimensional torus interconnect with auxiliary networks for global communications.[11] In this approach each node is connected to its six nearest neighbors. A similar torus was used by the Cray T3E.[12]
Massive centralized systems at times use special-purpose processors designed for a specific application, and may use field-programmable gate arrays (FPGA) chips to gain performance by sacrificing generality. Examples of special-purpose supercomputers include Belle,[33] Deep Blue,[34] and Hydra,[35] for playing chess, Gravity Pipe for astrophysics,[36] MDGRAPE-3 for protein structure computation molecular dynamics[37] and Deep Crack,[38] for breaking the DES cipher.
Massive distributed parallelism
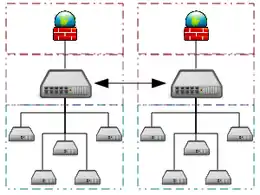
Grid computing uses a large number of computers in distributed, diverse administrative domains. It is an opportunistic approach which uses resources whenever they are available.[10] An example is BOINC a volunteer-based, opportunistic grid system.[39] Some BOINC applications have reached multi-petaflop levels by using close to half a million computers connected on the internet, whenever volunteer resources become available.[40] However, these types of results often do not appear in the TOP500 ratings because they do not run the general purpose Linpack benchmark.
Although grid computing has had success in parallel task execution, demanding supercomputer applications such as weather simulations or computational fluid dynamics have remained out of reach, partly due to the barriers in reliable sub-assignment of a large number of tasks as well as the reliable availability of resources at a given time.[39][41][42]
In quasi-opportunistic supercomputing a large number of geographically disperse computers are orchestrated with built-in safeguards.[43] The quasi-opportunistic approach goes beyond volunteer computing on a highly distributed systems such as BOINC, or general grid computing on a system such as Globus by allowing the middleware to provide almost seamless access to many computing clusters so that existing programs in languages such as Fortran or C can be distributed among multiple computing resources.[43]
Quasi-opportunistic supercomputing aims to provide a higher quality of service than opportunistic resource sharing.[44] The quasi-opportunistic approach enables the execution of demanding applications within computer grids by establishing grid-wise resource allocation agreements; and fault tolerant message passing to abstractly shield against the failures of the underlying resources, thus maintaining some opportunism, while allowing a higher level of control.[10][43][45]
21st-century architectural trends

The air-cooled IBM Blue Gene supercomputer architecture trades processor speed for low power consumption so that a larger number of processors can be used at room temperature, by using normal air-conditioning.[14][46] The second-generation Blue Gene/P system has processors with integrated node-to-node communication logic.[47] It is energy-efficient, achieving 371 MFLOPS/W.[48]
The K computer is a water-cooled, homogeneous processor, distributed memory system with a cluster architecture.[32][49] It uses more than 80,000 SPARC64 VIIIfx processors, each with eight cores, for a total of over 700,000 cores—almost twice as many as any other system. It comprises more than 800 cabinets, each with 96 computing nodes (each with 16 GB of memory), and 6 I/O nodes. Although it is more powerful than the next five systems on the TOP500 list combined, at 824.56 MFLOPS/W it has the lowest power to performance ratio of any current major supercomputer system.[50][51] The follow up system for the K computer, called the PRIMEHPC FX10 uses the same six-dimensional torus interconnect, but still only one processor per node.[52]
Unlike the K computer, the Tianhe-1A system uses a hybrid architecture and integrates CPUs and GPUs.[4] It uses more than 14,000 Xeon general-purpose processors and more than 7,000 Nvidia Tesla general-purpose graphics processing units (GPGPUs) on about 3,500 blades.[53] It has 112 computer cabinets and 262 terabytes of distributed memory; 2 petabytes of disk storage is implemented via Lustre clustered files.[54][55][56][4] Tianhe-1 uses a proprietary high-speed communication network to connect the processors.[4] The proprietary interconnect network was based on the Infiniband QDR, enhanced with Chinese made FeiTeng-1000 CPUs.[4] In the case of the interconnect the system is twice as fast as the Infiniband, but slower than some interconnects on other supercomputers.[57]
The limits of specific approaches continue to be tested, as boundaries are reached through large scale experiments, e.g., in 2011 IBM ended its participation in the Blue Waters petaflops project at the University of Illinois.[58][59] The Blue Waters architecture was based on the IBM POWER7 processor and intended to have 200,000 cores with a petabyte of "globally addressable memory" and 10 petabytes of disk space.[6] The goal of a sustained petaflop led to design choices that optimized single-core performance, and hence a lower number of cores. The lower number of cores was then expected to help performance on programs that did not scale well to a large number of processors.[6] The large globally addressable memory architecture aimed to solve memory address problems in an efficient manner, for the same type of programs.[6] Blue Waters had been expected to run at sustained speeds of at least one petaflop, and relied on the specific water-cooling approach to manage heat. In the first four years of operation, the National Science Foundation spent about $200 million on the project. IBM released the Power 775 computing node derived from that project's technology soon thereafter, but effectively abandoned the Blue Waters approach.[58][59]
Architectural experiments are continuing in a number of directions, e.g. the Cyclops64 system uses a "supercomputer on a chip" approach, in a direction away from the use of massive distributed processors.[60][61] Each 64-bit Cyclops64 chip contains 80 processors, and the entire system uses a globally addressable memory architecture.[62] The processors are connected with non-internally blocking crossbar switch and communicate with each other via global interleaved memory. There is no data cache in the architecture, but half of each SRAM bank can be used as a scratchpad memory.[62] Although this type of architecture allows unstructured parallelism in a dynamically non-contiguous memory system, it also produces challenges in the efficient mapping of parallel algorithms to a many-core system.[61]
See also
| Wikimedia Commons has media related to Supercomputers. |
References
- Sao-Jie Chen; Guang-Huei Lin; Pao-Ann Hsiung; Yu-Hen Hu (9 February 2009). Hardware Software Co-Design of a Multimedia Soc Platform. Springer. pp. 70–72. ISBN 978-1-4020-9622-8. Retrieved 15 June 2012.
- Hoffman, Allan R. (1989). Supercomputers : directions in technology and applications. Washington, D.C.: National Academy Press. pp. 35–47. ISBN 978-0-309-04088-4.
- Hill, Mark D.; Jouppi, Norman P.; Sohi, Gurindar (2000). Readings in computer architecture. San Francisco: Morgan Kaufmann. pp. 40–49. ISBN 978-1-55860-539-8.
- Yang, Xue-Jun; Liao, Xiang-Ke; Lu, Kai; Hu, Qing-Feng; Song, Jun-Qiang; Su, Jin-Shu (2011). "The TianHe-1A Supercomputer: Its Hardware and Software". Journal of Computer Science and Technology. 26 (3): 344–351. doi:10.1007/s02011-011-1137-8.
- Murray, Charles J. (1997). The supermen : the story of Seymour Cray and the technical wizards behind the supercomputer. New York: John Wiley. pp. 133–135. ISBN 978-0-471-04885-5.
- Biswas, edited by Rupak (2010). Parallel computational fluid dynamics : recent advances and future directions : papers from the 21st International Conference on Parallel Computational Fluid Dynamics. Lancaster, Pa.: DEStech Publications. p. 401. ISBN 978-1-60595-022-8.CS1 maint: extra text: authors list (link)
- Yongge Huáng, ed. (2008). Supercomputing research advances. New York: Nova Science Publishers. pp. 313–314. ISBN 978-1-60456-186-9.
- Tokhi, M. O.; Hossain, M. A.; Shaheed, M. H. (2003). Parallel computing for real-time signal processing and control. London [u.a.]: Springer. pp. 201–202. ISBN 978-1-85233-599-1.
- Vaidy S. Sunderam, ed. (2005). Computational science -- ICCS 2005. 5th international conference, Atlanta, GA, USA, May 22-25, 2005 : proceedings (1st ed.). Berlin: Springer. pp. 60–67. ISBN 978-3-540-26043-1.
- Prodan, Radu; Thomas Fahringer (2007). Grid computing experiment management, tool integration, and scientific workflows. Berlin: Springer. pp. 1–4. ISBN 978-3-540-69261-4.
- Knight, Will (27 June 2007). "IBM creates world's most powerful computer". New Scientist.
- Adiga, N. R.; Blumrich, M. A.; Chen, D.; Coteus, P.; Gara, A.; Giampapa, M. E.; Heidelberger, P.; Singh, S.; Steinmacher-Burow, B. D.; Takken, T.; Tsao, M.; Vranas, P. (March 2005). "Blue Gene/L torus interconnection network" (PDF). IBM Journal of Research and Development. 49 (2.3): 265–276. doi:10.1147/rd.492.0265. Archived from the original (PDF) on 2011-08-15.CS1 maint: multiple names: authors list (link)
- Varadarajan, S. (14 March 2005). System X building the Virginia Tech supercomputer. Computer Communications and Networks, 2004. ICCCN 2004. Proceedings. 13th International Conference on. p. 1. doi:10.1109/ICCCN.2004.1401570. ISBN 978-0-7803-8814-7. ISSN 1095-2055.
- Prickett Morgan, Timothy (22 November 2010). "IBM uncloaks 20 petaflops BlueGene/Q super". The Register.
- "IBM Hot Water-Cooled Supercomputer Goes Live at ETH Zurich". HPCwire. Zurich. 2 July 2010. Archived from the original on 13 August 2012.
- LaMonica, Martin (10 May 2010). "IBM liquid-cooled supercomputer heats building". Green Tech. Cnet.
- Henderson, Harry (2008). "Supercomputer Architecture". Encyclopedia of Computer Science and Technology. p. 217. ISBN 978-0-8160-6382-6.
- Prickett Morgan, Timothy (31 May 2010). "Top 500 supers – The Dawning of the GPUs". The Register.
- Rainer Keller; David Kramer; Jan-Philipp Weiss (1 December 2010). Facing the Multicore-Challenge: Aspects of New Paradigms and Technologies in Parallel Computing. Springer. pp. 118–121. ISBN 978-3-642-16232-9. Retrieved 15 June 2012.
- Poeter, Damon (11 October 2011). "Cray's Titan Supercomputer for ORNL could be world's fastest". PC Magazine.
- Feldman, Michael (11 October 2011). "GPUs Will Morph ORNL's Jaguar Into 20-Petaflop Titan". HPC Wire.
- Prickett Morgan, Timothy (11 October 2011). "Oak Ridge changes Jaguar's spots from CPUs to GPUs".
- Hai-Xiang Lin; Michael Alexander; Martti Forsell, eds. (2010). Euro-Par 2009 parallel processing workshops : HPPC, HeteroPar, PROPER, ROIA, UNICORE, VHPC, Delft, The Netherlands, August 25-28, 2009 ; workshops (Online-Ausg. ed.). Berlin: Springer. p. 345. ISBN 978-3-642-14121-8.
- Reiner Dumke; René Braungarten; Günter Büren (3 December 2008). Software Process and Product Measurement: International Conferences, IWSM 2008, MetriKon 2008, and Mensura 2008, Munich, Germany, November 18-19, 2008 : Proceedings. Springer. pp. 144–117. ISBN 978-3-540-89402-5. Retrieved 15 June 2012.
- Frisch, Michael J. (December 1972). "Remarks on algorithm 352 [S22], algorithm 385 [S13], algorithm 392 [D3]". Communications of the ACM. 15 (12): 1074. doi:10.1145/361598.361914.
- El-Rewini, Hesham; Mostafa Abd-El-Barr (2005). Advanced computer architecture and parallel processing. Hoboken, NJ: Wiley-Interscience. pp. 77–80. ISBN 978-0-471-46740-3.
- J. J. Dongarra; L. Grandinetti; J. Kowalik; G.R. Joubert (13 September 1995). High Performance Computing: Technology, Methods and Applications. Elsevier. pp. 123–125. ISBN 978-0-444-82163-8. Retrieved 15 June 2012.
- Greg Astfalk (1996). Applications on Advanced Architecture Computers. SIAM. pp. 61–64. ISBN 978-0-89871-368-8. Retrieved 15 June 2012.
- Jelica Protić; Milo Tomašević; Milo Tomasevic; Veljko Milutinović (1998). Distributed shared memory: concepts and systems. IEEE Computer Society Press. pp. ix–x. ISBN 978-0-8186-7737-3. Retrieved 15 June 2012.
- Tomoya Enokido; Leonard Barolli; Makoto Takizawa, eds. (2007). Network-based information systems : first international conference, NBiS 2007, Regensburg, Germany, September 3-7, 2007 : proceedings. Berlin: Springer. p. 375. ISBN 978-3-540-74572-3.
- TOP500 list To view all clusters on the TOP500 list select "cluster" as architecture from the "sublist menu" on the TOP500 site.
- Yokokawa, M.; Shoji, Fumiyoshi; Uno, Atsuya; Kurokawa, Motoyoshi; Watanabe, Tadashi (22 August 2011). The K computer: Japanese next-generation supercomputer development project. Low Power Electronics and Design (ISLPED) 2011 International Symposium on. pp. 371–372. doi:10.1109/ISLPED.2011.5993668. ISBN 978-1-61284-658-3.
- Condon, J.H. and K.Thompson, "Belle Chess Hardware", In Advances in Computer Chess 3 (ed.M.R.B.Clarke), Pergamon Press, 1982.
- Hsu, Feng-hsiung (2002). Behind Deep Blue: Building the Computer that Defeated the World Chess Champion. Princeton University Press. ISBN 978-0-691-09065-8.CS1 maint: ref=harv (link)
- Donninger, Chrilly; Ulf Lorenz (2004). The Chess Monster Hydra. Lecture Notes in Computer Science. 3203. pp. 927–932. doi:10.1007/978-3-540-30117-2_101. ISBN 978-3-540-22989-6.
- Makino, Junichiro; Makoto Taiji (1998). Scientific simulations with special purpose computers : the GRAPE systems. Chichester [u.a.]: Wiley. ISBN 978-0-471-96946-4.
- RIKEN press release, Completion of a one-petaflops computer system for simulation of molecular dynamics Archived 2012-12-02 at the Wayback Machine
- Electronic Frontier Foundation (1998). Cracking DES – Secrets of Encryption Research, Wiretap Politics & Chip Design. Oreilly & Associates Inc. ISBN 978-1-56592-520-5.
- Vega, Francisco Fernández de Vega (2010). Erick Cantú-Paz (ed.). Parallel and distributed computational intelligence (Online-Ausg. ed.). Berlin: Springer-Verlag. pp. 65–68. ISBN 978-3-642-10674-3.
- BOIN statistics, 2011 Archived 2010-09-19 at the Wayback Machine
- Guang R. Gao, ed. (2010). Languages and compilers for parallel computing : 22nd international workshop, LCPC 2009, Newark, DE, USA, October 8-10, 2009, revised selected papers (1st ed.). Berlin: Springer. pp. 10–11. ISBN 978-3-642-13373-2.
- Mario R. Guarracino, ed. (2011-06-24). Euro-par 2010, Parallel Processing Workshops Heteropar, Hpcc, Hibb, Coregrid, Uchpc, Hpcf, Proper, Ccpi, Vhpc, Iscia, Italy, August 31 - September 3, 2010. Berlin [u.a.]: Springer-Verlag New York Inc. pp. 274–277. ISBN 978-3-642-21877-4.
- Kravtsov, Valentin; David Carmeli; Werner Dubitzky; Ariel Orda; Assaf Schuster; Benny Yoshpa (2007). "Quasi-opportunistic supercomputing in grids". IEEE International Symposium on High Performance Distributed Computing: 233–244.
- Marian Bubak, ed. (2008). Computational science -- ICCS 2008 : 8th international conference, Krakow, Poland, June 23-25, 2008 ; proceedings (Online-Ausg. ed.). Berlin: Springer. pp. 112–113. ISBN 978-3-540-69383-3.
- Gabrielle Allen, ed. (2009). Computational science - ICCS 2009 : 9th international conference, Baton Rouge, LA, USA, May 25-27, 2009 ; proceedings. Berlin: Springer. pp. 387–388. ISBN 978-3-642-01969-2.
- Cunha, José C. (2005). Euro-Par 2005 Parallel Processing. [New York]: Springer-Verlag Berlin/Heidelberg. pp. 560–567. ISBN 978-3-540-28700-1.
- "IBM Triples Performance of World's Fastest, Most Energy-Efficient Supercomputer". 2007-06-27. Retrieved 2011-12-24.
- "The Green500 List". Archived from the original on 2016-08-26. Retrieved 2020-02-13.
- TOP500 list Archived 2012-01-20 at the Wayback Machine
- Takumi Maruyama (2009). SPARC64(TM) VIIIfx: Fujitsu's New Generation Octo Core Processor for PETA Scale computing (PDF). Proceedings of Hot Chips 21. IEEE Computer Society.
- "RIKEN Advanced Institute for Computational Science" (PDF). RIKEN. Archived from the original (PDF) on 27 July 2011. Retrieved 20 June 2011.
- Fujitsu Unveils Post-K SupercomputerHPC Wire Nov 7 2011
- "MSN | Outlook, Office, Skype, Bing, Breaking News, and Latest Videos". Archived from the original on 2010-10-07.
- "China ..." 28 October 2010.
- "Top100 ..." 28 October 2010.
- Tianhe-1A
- Thibodeau, Patrick (4 November 2010). "U.S. says China building 'entirely indigenous' supercomputer". Computerworld. Archived from the original on 11 October 2012. Retrieved 5 February 2012.
- The Register: IBM yanks chain on 'Blue Waters' super
- The Statesman IBM's Unix computer business is booming
- Niu, Yanwei; Ziang Hu; Kenneth Barner; Guang R. Gao (2005). Performance modelling and optimization of memory access on cellular computer architecture cyclops64. Proceeding NPC'05 Proceedings of the 2005 IFIP International Conference on Network and Parallel Computing. Lecture Notes in Computer Science. 3779. pp. 132–143. doi:10.1007/11577188_18. ISBN 978-3-540-29810-6.
- Tan, Guangming; Sreedhar, Vugranam C.; Gao, Guang R. (13 November 2009). "Analysis and performance results of computing betweenness centrality on IBM Cyclops64". The Journal of Supercomputing. 56 (1): 1–24. doi:10.1007/s11227-009-0339-9.
- Hai Jin; Daniel A. Reed; Wenbin Jiang (2005). Network and Parallel Computing: IFIP International Conference, NPC 2005, Beijing, China, November 30 - December 3, 2005 ; Proceedings. Birkhäuser. pp. 132–133. ISBN 978-3-540-29810-6. Retrieved 15 June 2012.
| General | |
|---|---|
| Levels | |
| Multithreading |
|
| Theory | |
| Elements | |
| Coordination | |
| Programming | |
| Hardware | |
| APIs | |
| Problems | |
| |
