Vocoder
A vocoder (/ˈvoʊkoʊdər/, a portmanteau of voice and encoder) is a category of voice codec that analyzes and synthesizes the human voice signal for audio data compression, multiplexing, voice encryption or voice transformation.

The vocoder was invented in 1938 by Homer Dudley at Bell Labs as a means of synthesizing human speech.[1] This work was developed into the channel vocoder which was used as a voice codec for telecommunications for coding speech to conserve bandwidth in transmission.
By encrypting the control signals, voice transmission can be secured against interception. Its primary use in this fashion is for secure radio communication. The advantage of this method of encryption is that none of the original signal is sent, only envelopes of the bandpass filters. The receiving unit needs to be set up in the same filter configuration to re-synthesize a version of the original signal spectrum.
The vocoder has also been used extensively as an electronic musical instrument. The decoder portion of the vocoder, called a voder, can be used independently for speech synthesis.
Theory
The human voice consists of sounds generated by the opening and closing of the glottis by the vocal cords, which produces a periodic waveform with many harmonics. This basic sound is then filtered by the nose and throat (a complicated resonant piping system) to produce differences in harmonic content (formants) in a controlled way, creating the wide variety of sounds used in speech. There is another set of sounds, known as the unvoiced and plosive sounds, which are created or modified by the mouth in different fashions.
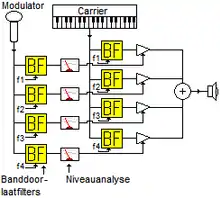
The vocoder examines speech by measuring how its spectral characteristics change over time. This results in a series of signals representing these modified frequencies at any particular time as the user speaks. In simple terms, the signal is split into a number of frequency bands (the larger this number, the more accurate the analysis) and the level of signal present at each frequency band gives the instantaneous representation of the spectral energy content. To recreate speech, the vocoder simply reverses the process, processing a broadband noise source by passing it through a stage that filters the frequency content based on the originally recorded series of numbers.
Specifically, in the encoder, the input is passed through a multiband filter, then each band is passed through an envelope follower, and the control signals from the envelope followers are transmitted to the decoder. The decoder applies these (amplitude) control signals to corresponding amplifiers of the filter channels for re-synthesis.
Information about the instantaneous frequency of the original voice signal (as distinct from its spectral characteristic) is discarded; it was not important to preserve this for the vocoder's original use as an encryption aid. It is this "dehumanizing" aspect of the vocoding process that has made it useful in creating special voice effects in popular music and audio entertainment.
The vocoder process sends only the parameters of the vocal model over the communication link, instead of a point-by-point recreation of the waveform. Since the parameters change slowly compared to the original speech waveform, the bandwidth required to transmit speech can be reduced. This allows more speech channels to utilize a given communication channel, such as a radio channel or a submarine cable.
Analog vocoders typically analyze an incoming signal by splitting the signal into multiple tuned frequency bands or ranges. A modulator and carrier signal are sent through a series of these tuned bandpass filters. In the example of a typical robot voice, the modulator is a microphone and the carrier is noise or a sawtooth waveform. There are usually between eight and 20 bands.
The amplitude of the modulator for each of the individual analysis bands generates a voltage that is used to control amplifiers for each of the corresponding carrier bands. The result is that frequency components of the modulating signal are mapped onto the carrier signal as discrete amplitude changes in each of the frequency bands.
Often there is an unvoiced band or sibilance channel. This is for frequencies that are outside the analysis bands for typical speech but are still important in speech. Examples are words that start with the letters s, f, ch or any other sibilant sound. These can be mixed with the carrier output to increase clarity. The result is recognizable speech, although somewhat "mechanical" sounding. Vocoders often include a second system for generating unvoiced sounds, using a noise generator instead of the fundamental frequency.
In the channel vocoder algorithm, among the two components of an analytic signal, considering only the amplitude component and simply ignoring the phase component tends to result in an unclear voice; on methods for rectifying this, see phase vocoder.
History
._%22The_Carrier_Nature_of_Speech%22._Bell_System_Technical_Journal%252C_XIX(4)%253B495-515._--_Fig.7_Schematic_circuit_of_the_vocoder_(derived_from_Fig.8).jpg.webp)


The development of a vocoder was started in 1928 by Bell Labs engineer Homer Dudley,[5] who was granted patents for it, US application 2,151,091 on March 21, 1939,[6] and US application 2,098,956 on Nov 16, 1937.[7]
Then, to show the speech synthesis ability of its decoder part, the Voder (Voice Operating Demonstrator, US application 2,121,142[8]), was introduced to the public at the AT&T building at the 1939–1940 New York World's Fair.[9] The Voder consisted of a switchable pair of electronic oscillator and noise generator as a sound source of pitched tone and hiss, 10-band resonator filters with variable-gain amplifiers as a vocal tract, and the manual controllers including a set of pressure-sensitive keys for filter control, and a foot pedal for pitch control of tone.[10] The filters controlled by keys convert the tone and the hiss into vowels, consonants, and inflections. This was a complex machine to operate, but a skilled operator could produce recognizable speech.[9][media 1]
Dudley's vocoder was used in the SIGSALY system, which was built by Bell Labs engineers in 1943. SIGSALY was used for encrypted high-level voice communications during World War II. The KO-6 voice coder was released in 1949 in limited quantities; it was a close approximation to the SIGSALY at 1200 bit/s. In 1953, KY-9 THESEUS[11] 1650 bit/s voice coder used solid state logic to reduce the weight to 565 pounds (256 kg) from SIGSALY's 55 tons, and in 1961 the HY-2 voice coder, a 16-channel 2400 bit/s system, weighted 100 pounds (45 kg) and was the last implementation of a channel vocoder in a secure speech system.[12]
Later work in this field has since used digital speech coding. The most widely used speech coding technique is linear predictive coding (LPC),[13] which was first proposed by Fumitada Itakura of Nagoya University and Shuzo Saito of Nippon Telegraph and Telephone (NTT) in 1966.[14] Another speech coding technique, adaptive differential pulse-code modulation (ADPCM), was developed by P. Cummiskey, Nikil S. Jayant and James L. Flanagan at Bell Labs in 1973.[15]
Applications
- Terminal equipment for Digital Mobile Radio (DMR) based systems.
- Digital Trunking
- DMR TDMA
- Digital Voice Scrambling and Encryption
- Digital WLL
- Voice Storage and Playback Systems
- Messaging Systems
- VoIP Systems
- Voice Pagers
- Regenerative Digital Voice Repeaters
- Cochlear Implants: Noise and tone vocoding is used to simulate the effects of Cochlear Implants.
- Musical and other artistic effects[16]
Modern implementations
Even with the need to record several frequencies, and additional unvoiced sounds, the compression of vocoder systems is impressive. Standard speech-recording systems capture frequencies from about 500 Hz to 3,400 Hz, where most of the frequencies used in speech lie, typically using a sampling rate of 8 kHz (slightly greater than the Nyquist rate). The sampling resolution is typically 12 or more bits per sample resolution (16 is standard), for a final data rate in the range of 96–128 kbit/s, but a good vocoder can provide a reasonably good simulation of voice with as little as 2.4 kbit/s of data.
"Toll quality" voice coders, such as ITU G.729, are used in many telephone networks. G.729 in particular has a final data rate of 8 kbit/s with superb voice quality. G.723 achieves slightly worse quality at data rates of 5.3 kbit/s and 6.4 kbit/s. Many voice vocoder systems use lower data rates, but below 5 kbit/s voice quality begins to drop rapidly.
Several vocoder systems are used in NSA encryption systems:
- LPC-10, FIPS Pub 137, 2400 bit/s, which uses linear predictive coding
- Code-excited linear prediction (CELP), 2400 and 4800 bit/s, Federal Standard 1016, used in STU-III
- Continuously variable slope delta modulation (CVSD), 16 kbit/s, used in wide band encryptors such as the KY-57.
- Mixed-excitation linear prediction (MELP), MIL STD 3005, 2400 bit/s, used in the Future Narrowband Digital Terminal FNBDT, NSA's 21st century secure telephone.
- Adaptive Differential Pulse Code Modulation (ADPCM), former ITU-T G.721, 32 kbit/s used in STE secure telephone
(ADPCM is not a proper vocoder but rather a waveform codec. ITU has gathered G.721 along with some other ADPCM codecs into G.726.)
Vocoders are also currently used in developing psychophysics, linguistics, computational neuroscience and cochlear implant research.
Modern vocoders that are used in communication equipment and in voice storage devices today are based on the following algorithms:
- Algebraic code-excited linear prediction (ACELP 4.7 kbit/s – 24 kbit/s)[17]
- Mixed-excitation linear prediction (MELPe 2400, 1200 and 600 bit/s)[18]
- Multi-band excitation (AMBE 2000 bit/s – 9600 bit/s)[19]
- Sinusoidal-Pulsed Representation (SPR 600 bit/s – 4800 bit/s)[20]
- Robust Advanced Low-complexity Waveform Interpolation (RALCWI 2050bit/s, 2400bit/s and 2750bit/s)[21]
- Tri-Wave Excited Linear Prediction (TWELP 600 bit/s – 9600 bit/s)[22]
- Noise Robust Vocoder (NRV 300 bit/s and 800 bit/s)[23]
Linear prediction-based
Since the late 1970s, most non-musical vocoders have been implemented using linear prediction, whereby the target signal's spectral envelope (formant) is estimated by an all-pole IIR filter. In linear prediction coding, the all-pole filter replaces the bandpass filter bank of its predecessor and is used at the encoder to whiten the signal (i.e., flatten the spectrum) and again at the decoder to re-apply the spectral shape of the target speech signal.
One advantage of this type of filtering is that the location of the linear predictor's spectral peaks is entirely determined by the target signal, and can be as precise as allowed by the time period to be filtered. This is in contrast with vocoders realized using fixed-width filter banks, where spectral peaks can generally only be determined to be within the scope of a given frequency band. LP filtering also has disadvantages in that signals with a large number of constituent frequencies may exceed the number of frequencies that can be represented by the linear prediction filter. This restriction is the primary reason that LP coding is almost always used in tandem with other methods in high-compression voice coders.
Waveform-interpolative
Waveform-interpolative (WI) vocoder was developed in AT&T Bell Laboratories around 1995 by W.B. Kleijn, and subsequently a low- complexity version was developed by AT&T for the DoD secure vocoder competition. Notable enhancements to the WI coder were made at the University of California, Santa Barbara. AT&T holds the core patents related to WI, and other institutes hold additional patents.[24][25][26]
Artistic effects
Uses in music
For musical applications, a source of musical sounds is used as the carrier, instead of extracting the fundamental frequency. For instance, one could use the sound of a synthesizer as the input to the filter bank, a technique that became popular in the 1970s.
History
Werner Meyer-Eppler, a German scientist with a special interest in electronic voice synthesis, published a thesis in 1948 on electronic music and speech synthesis from the viewpoint of sound synthesis.[27] Later he was instrumental in the founding of the Studio for Electronic Music of WDR in Cologne, in 1951.[28]

One of the first attempts to use a vocoder in creating music was the "Siemens Synthesizer" at the Siemens Studio for Electronic Music, developed between 1956 and 1959.[29][30][media 2]
In 1968, Robert Moog developed one of the first solid-state musical vocoders for the electronic music studio of the University at Buffalo.[31]
In 1968, Bruce Haack built a prototype vocoder, named "Farad" after Michael Faraday.[32] It was first featured on "The Electronic Record For Children" released in 1969 and then on his rock album The Electric Lucifer released in 1970.[33][media 3]
In 1970, Wendy Carlos and Robert Moog built another musical vocoder, a ten-band device inspired by the vocoder designs of Homer Dudley. It was originally called a spectrum encoder-decoder and later referred to simply as a vocoder. The carrier signal came from a Moog modular synthesizer, and the modulator from a microphone input. The output of the ten-band vocoder was fairly intelligible but relied on specially articulated speech. Some vocoders use a high-pass filter to let some sibilance through from the microphone; this ruins the device for its original speech-coding application, but it makes the talking synthesizer effect much more intelligible.
The 1975 song The Raven of album Tales of Mystery and Imagination by The Alan Parsons Project, features Alan Parsons performing vocals through an EMI vocoder. According to the album's liner notes, "The Raven" was the first rock song to feature a digital vocoder.
Phil Collins used a vocoder to provide a vocal effect for his 1981 international hit single "In the Air Tonight".[34]
Vocoders have appeared on pop recordings from time to time, most often simply as a special effect rather than a featured aspect of the work. However, many experimental electronic artists of the new-age music genre often utilize vocoder in a more comprehensive manner in specific works, such as Jean Michel Jarre (on Zoolook, 1984) and Mike Oldfield (on QE2, 1980 and Five Miles Out, 1982).
Vocoder module and use by M. Oldfield can be clearly seen on his "Live At Montreux 1981" DVD (Track "Sheba").
There are also some artists who have made vocoders an essential part of their music, overall or during an extended phase. Examples include the German synthpop group Kraftwerk, the Japanese new wave group Polysics, Stevie Wonder ("Send One Your Love", "A Seed's a Star") and jazz/fusion keyboardist Herbie Hancock during his late 1970s period. In 1982 Neil Young used a Sennheiser Vocoder VSM201 on six of the nine tracks on Trans.[35] Perhaps the most heard, yet often unrecognized, example of the use of a vocoder in popular music, is on Michael Jackson's 1982 album Thriller, in the song "P.Y.T. (Pretty Young Thing)". During the first few seconds of the song, the background voicings "ooh-ooh, ooh, ooh", behind his spoken words, exemplify the heavily modulated sound of his voice through a Vocoder.[36] The bridge features a vocoder as well ("Pretty young thing/You make me sing"), courtesy of session musician Michael Boddicker.
Coldplay have used a vocoder in some of their songs. For example, in "Major Minus" and "Hurts Like Heaven", both from the album Mylo Xyloto (2011), Chris Martin's vocals are mostly vocoder-processed. "Midnight", from Ghost Stories (2014), also features Martin singing through a vocoder.[37] The hidden track "X Marks The Spot" from A Head Full of Dreams has also been recorded through a vocoder.
Noisecore band Atari Teenage Riot have used vocoders in variety of their songs and live performances such as Live at the Brixton Academy (2002) alongside other digital audio technology both old and new.
Red Hot Chili Peppers song "By the Way" uses a vocoder effect on Anthony Kiedis' vocals.
Among the most consistent uses of vocoder in emulating the human voice are Daft Punk, who have used this instrument from their first album Homework (1997) to their latest work Random Access Memories (2013) and consider the convergence of technological and human voice "the identity of their musical project".[38] For instance, the lyrics of "Around the World" (1997) are integrally vocoder-processed, "Get Lucky" (2013) features a mix of natural and processed human voices, and "Instant Crush" (2013) features Julian Casablancas singing into a vocoder.
Voice effects in other arts
"Robot voices" became a recurring element in popular music during the 20th century. Apart from vocoders, several other methods of producing variations on this effect include: the Sonovox, Talk box, and Auto-Tune,[media 4] linear prediction vocoders, speech synthesis,[media 5][media 6] ring modulation and comb filter.
Vocoders are used in television production, filmmaking and games, usually for robots or talking computers. The robot voices of the Cylons in Battlestar Galactica were created with an EMS Vocoder 2000.[35] The 1980 version of the Doctor Who theme, as arranged and recorded by Peter Howell, has a section of the main melody generated by a Roland SVC-350 Vocoder. A vocoder was also used to create the voice of Soundwave, a character from the Transformers series.
In 1967 the Supermarionation series Captain Scarlet and the Mysterons it was used in the closing credits theme of the first 14 episodes to provide the repetition of the words "Captain Scarlet".
In 1972, Isao Tomita's first electronic music album Electric Samurai: Switched on Rock was an early attempt at applying speech synthesis technique through a vocoder in electronic rock and pop music. The album featured electronic renditions of contemporary rock and pop songs, while utilizing synthesized voices in place of human voices. In 1974, he utilized synthesized voices in his popular classical music album Snowflakes are Dancing, which became a worldwide success and helped to popularize electronic music. Emerson, Lake and Palmer used it for the album Brain Salad Surgery (1973).[39]
See also
References
- , "System for the artificial production of vocal or other sounds", issued 1937-04-07
- Dudley, Homer (October 1940). "The Carrier Nature of Speech". Bell System Technical Journal. XIX (4).
- "HY-2". Cryptomuseum.com. Retrieved 2019-07-31.
- "HY-2 Vocoder". Crypto Machines.
- Mills, Mara (2012). "Media and Prosthesis: the Vocoder, the Artificial Larynx, and the History of Signal Processing". Qui Parle. 21 (1): 107–149. doi:10.5250/quiparle.21.1.0107. S2CID 143012886.
- US application 2151091, Dudley, Homer W., "Signal Transmission", published May 21, 1939, assigned to Bell Telephone Laboratories, Inc. (filed October 30, 1935)
- US application 2098956, Dudley, Homer W., "Signaling system", published November 16, 1937, assigned to Bell Telephone Laboratories, Inc. (filed December 2, 1936)
- US apprication 2121142, Dudley, Homer, "Signal Transmission", published June 21, 1938, assigned to Bell Telephone Laboratories, Inc. (filed April 7, 1937)
- "The 'Voder' & 'Vocoder' Homer Dudley, USA, 1940". 120 Years of Electronic Music (120years.net). 2013-09-21.
The Vocoder (Voice Operated reCorDER) and Voder (Voice Operation DEmonstratoR) developed by the research physicist Homer Dudley, ... The Voder was first unveiled in 1939 at the New York World Fair (where it was demonstrated at hourly intervals) and later in 1940 in San Francisco. There were twenty trained operators known as the 'girls' who handled the machine much like a musical instrument such as a piano or an organ, ... This was done by manipulating fourteen keys with the fingers, a bar with the left wrist and a foot pedal with the right foot.
-
"The Voder (1939)". Talking Heads: Simulacra. Haskins Laboratories.; based on James L. Flanagan (1965). "Speech Synthesis". Speech Analysis, Synthesis and Perception. Springer-Verlag. pp. 172–173.
See: schematic diagram of the Voder synthesizer. - "KY-9". Cryptomuseum.com. Retrieved 2019-07-31.
- "Campbell.qxd" (PDF). Retrieved 2019-07-31.
- Gupta, Shipra (May 2016). "Application of MFCC in Text Independent Speaker Recognition" (PDF). International Journal of Advanced Research in Computer Science and Software Engineering. 6 (5): 805-810 (806). ISSN 2277-128X. S2CID 212485331. Retrieved 18 October 2019.
LPC methods are the most widely used in speech coding
- Gray, Robert M. (2010). "A History of Realtime Digital Speech on Packet Networks: Part II of Linear Predictive Coding and the Internet Protocol" (PDF). Found. Trends Signal Process. 3 (4): 203–303. doi:10.1561/2000000036. ISSN 1932-8346.
- Cummiskey, P.; Jayant, Nikil S.; Flanagan, James L. (1973). "Adaptive quantization in differential PCM coding of speech". The Bell System Technical Journal. 52 (7): 1105–1118. doi:10.1002/j.1538-7305.1973.tb02007.x.
- Ernst Rothauser Dissertation and patents on vocoder technology
- "Voice Age" (licensing). VoiceAge Corporation.
- "MELPe – FAQ". Compandent Inc.
- "IMBE and AMBE". Digital Voice Systems, Inc.
- "SPR Vocoders". DSP Innovations Inc.
- "RALCWI Vocoder IC's". CML Microcircuits. CML Microsystems Plc.
- "TWELP Vocoder". DSP Innovations Inc.
- "Noise Rubust Vocoders". Raytheon BBN Technologies. Archived from the original on 2014-04-02.
- Kleijn, W.B.; Haagen, J.; (AT&T Bell Labs., Murray Hill, NJ) (1995). "A speech coder based on decomposition of characteristic waveforms". 1995 International Conference on Acoustics, Speech, and Signal Processing. IEEE 1995 International Conference on Acoustics, Speech, and Signal Processing, 1995. ICASSP-95. 1. pp. 508–511. doi:10.1109/ICASSP.1995.479640. ISBN 978-0-7803-2431-2. S2CID 9105323.CS1 maint: multiple names: authors list (link)
- Kleijn, W.B.; Shoham, Y.; Sen, D.; Hagen, R.; (AT&T Bell Labs., Murray Hill, NJ) (1996). "A low-complexity waveform interpolation coder". 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings. IEEE Icassp 1996. 1. pp. 212–215. doi:10.1109/ICASSP.1996.540328. ISBN 978-0-7803-3192-1. S2CID 44346744.CS1 maint: multiple names: authors list (link)
- Gottesman, O.; Gersho, A.; (Dept. of Electr. & Comput. Eng., California Univ., Santa Barbara, CA) (2001). "Enhanced waveform interpolative coding at low bit-rate". IEEE Transactions on Speech and Audio Processing. 9 (November 2001): 786–798. doi:10.1109/89.966082. S2CID 17949435.CS1 maint: multiple names: authors list (link)
- Meyer-Eppler, Werner (1949), Elektronische Klangerzeugung: Elektronische Musik und synthetische Sprache, Bonn: Ferdinand Dümmlers
- Diesterhöft, Sonja (2003), "Meyer-Eppler und der Vocoder", Seminars Klanganalyse und -synthese (in German), Fachgebiet Kommunikationswissenschaft, Institut für Sprache und Kommunikation, Berlin Institute of Technology, archived from the original on 2008-03-05
- "Das Siemens-Studio für elektronische Musik von Alexander Schaaf und Helmut Klein" (in German). Deutsches Museum. Archived from the original on 2013-09-30.
- Holmes, Thom (2012). "Early Synthesizers and Experimenters". Electronic and Experimental Music: Technology, Music, and Culture (4th ed.). Routledge. pp. 190–192. ISBN 978-1-136-46895-7.
(See also excerpt of pp. 157–160 from the 3rd edition in 2008 (ISBN 978-0-415-95781-6)) - Bode, Harald (October 1984). "History of Electronic Sound Modification" (PDF). Journal of the Audio Engineering Society. 32 (10): 730–739.
- BRUCE HAACK – FARAD: THE ELECTRIC VOICE (Media notes). Bruce Haack. Stones Throw Records LLC. 2010.CS1 maint: others (link)
- "Bruce Haack's Biography 1965–1974". Bruce Haack Publishing.
- Flans, Robyn (5 January 2005). "Classic Tracks: Phil Collins' "In the Air Tonight"". Mix Online. Retrieved 25 February 2015.
- Tompkins, Dave (2010–2011). How to Wreck a Nice Beach: The Vocoder from World War II to Hip-Hop, The Machine Speaks. Melville House. ISBN 978-1-61219-093-8.
- "The Vocoder: From Speech-Scrambling To Robot Rock". NPR Music. May 13, 2010.
- "Midnight is amazing! But it sounds like Chris's voice has autotune in some parts. I thought Coldplay doesn't use autotune?". Coldplay "Oracle". 5 March 2014. Retrieved 25 March 2014.
- "Daft Punk: "La musique actuelle manque d'ambition"" (interview). Le Figaro. May 3, 2013.
- Jenkins, Mark (2007), Analog synthesizers: from the legacy of Moog to software synthesis, Elsevier, pp. 133–4, ISBN 978-0-240-52072-8, retrieved 2011-05-27
- Multimedia references
-
One Of The First Vocoder Machine [sic] (Motion picture). c. 1939.
A demonstration of the Voder (not the Vocoder). - Siemens Electronic Music Studio in Deutsches Museum (multi part) (Video).
Details of the Siemens Electronic Music Studio, exhibited at the Deutsches Museum. - Bruce Haack (1970). Electric to Me Turn – from "The Electric Lucifer" (Phonograph). Columbia Records.
A sample of earlier Vocoder. - T-Pain (2005). I'm Sprung (CD Single/Download). Jive Records.
A sample of Auto-Tune effect (a.k.a. T-Pain effect). - Earlier Computer Speech Synthesis (Audio). AT&T Bell Labs. c. 1961.
A sample of earlier computer based speech synthesis and song synthesis, by John Larry Kelly, Jr. and Louis Gerstman at Bell Labs, using IBM 704 computer. The demo song "Daisy Bell", musical accompanied by Max Mathews, impressed Arthur C. Clarke and later he used it in the climactic scene of the screenplay for his novel 2001: A Space Odyssey. - TI Speak & Spell (Video). Texas Instruments. c. 1980.
A sample of speech synthesis.
External links
| Wikimedia Commons has media related to Vocoders. |
- "How Vocoders Work". PAIA. Archived from the original on 2011-09-07.
- Description, photographs, and diagram for the vocoder at 120years.net
- "Mats Claesson's course in Vokator". Archived from the original on 2016-03-06. Description of a modern Vocoder.
- GPL implementation of a vocoder, as a LADSPA plugin
- O'Reilly Article on Vocoders
- Object of Interest: The Vocoder The New Yorker Magazine mini documentary

{kind=link}