Ï
Ï, lowercase ï, is a symbol used in various languages written with the Latin alphabet; it can be read as the letter I with diaeresis or I-umlaut.
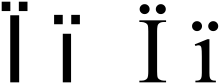
In Afrikaans, Catalan, Dutch, French, Galician, Welsh, Southern Sami, and occasionally English, ⟨ï⟩ is used when ⟨i⟩ follows another vowel and indicates hiatus (diaeresis) in the pronunciation of such a word. It indicates that the two vowels are pronounced in separate syllables, rather than together as a diphthong or digraph. For example, French maïs (IPA: [ma.is], maize); without the diaeresis, the ⟨i⟩ is part of the digraph ⟨ai⟩: mais (IPA: [mɛ], but). The letter is also in Dutch Oekraïne (pronounced [ukraːˈinə], Ukraine), and English naïve (/nɑːˈiːv/ or /naɪˈiːv/).
In German and Hungarian, ï does not belong to the alphabet.
In scholarly writing on Turkic languages, ⟨ï⟩ is sometimes used to write the close back unrounded vowel /ɯ/, which, in the standard modern Turkish alphabet, is written as the dotless i ⟨ı⟩.[1] The back neutral vowel reconstructed in Proto-Mongolic is sometimes written ⟨ï⟩.[2]
In the transcription of Amazonian languages, ï is used to represent the high central vowel [ɨ].
It is also a transliteration of the rune ᛇ.
Computing
Lowercase ï occurs in the sequence , which is the Unicode byte order mark in UTF-8 misinterpreted as ISO-8859-1 or CP1252 (both common encodings in software configured for English-language users). Thus, it tends to indicate that any following mojibake can be corrected by reinterpreting the data as UTF-8.
| Preview | Ï | ï | ||
|---|---|---|---|---|
| Unicode name | LATIN CAPITAL LETTER I WITH DIAERESIS | LATIN SMALL LETTER I WITH DIAERESIS | ||
| Encodings | decimal | hex | decimal | hex |
| Unicode | 207 | U+00CF | 239 | U+00EF |
| UTF-8 | 195 143 | C3 8F | 195 175 | C3 AF |
| Numeric character reference | Ï | Ï | ï | ï |
| Named character reference | Ï | ï | ||
| EBCDIC family | 119 | 77 | 87 | 57 |
| ISO 8859-1/2/3/4/9/10/14/15/16 | 207 | CF | 239 | EF |