Elo rating system
The Elo[lower-alpha 1] rating system is a method for calculating the relative skill levels of players in zero-sum games such as chess. It is named after its creator Arpad Elo, a Hungarian-American physics professor.

The Elo system was originally invented as an improved chess-rating system over the previously used Harkness system, but is also used as a rating system in association football, American football, basketball,[1] Major League Baseball, table tennis, board games such as Scrabble and Diplomacy, and esports, particularly Counter Strike: Global Offensive.[2]
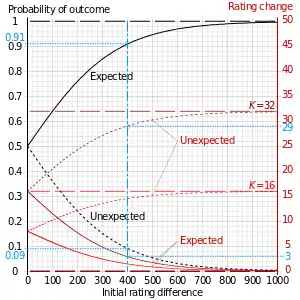
The difference in the ratings between two players serves as a predictor of the outcome of a match. Two players with equal ratings who play against each other are expected to score an equal number of wins. A player whose rating is 100 points greater than their opponent's is expected to score 64%; if the difference is 200 points, then the expected score for the stronger player is 76%.
A player's Elo rating is represented by a number which may change depending on the outcome of rated games played. After every game, the winning player takes points from the losing one. The difference between the ratings of the winner and loser determines the total number of points gained or lost after a game. If the high-rated player wins, then only a few rating points will be taken from the low-rated player. However, if the lower-rated player scores an upset win, many rating points will be transferred. The lower-rated player will also gain a few points from the higher rated player in the event of a draw. This means that this rating system is self-correcting. Players whose ratings are too low or too high should, in the long run, do better or worse correspondingly than the rating system predicts and thus gain or lose rating points until the ratings reflect their true playing strength.
An Elo rating is a comparative rating only, and is valid only within the rating pool where it was established.
History
Arpad Elo was a master-level chess player and an active participant in the United States Chess Federation (USCF) from its founding in 1939.[3] The USCF used a numerical ratings system, devised by Kenneth Harkness, to allow members to track their individual progress in terms other than tournament wins and losses. The Harkness system was reasonably fair, but in some circumstances gave rise to ratings which many observers considered inaccurate. On behalf of the USCF, Elo devised a new system with a more sound statistical basis.
Elo's system replaced earlier systems of competitive rewards with a system based on statistical estimation. Rating systems for many sports award points in accordance with subjective evaluations of the 'greatness' of certain achievements. For example, winning an important golf tournament might be worth an arbitrarily chosen five times as many points as winning a lesser tournament.
A statistical endeavor, by contrast, uses a model that relates the game results to underlying variables representing the ability of each player.
Elo's central assumption was that the chess performance of each player in each game is a normally distributed random variable. Although a player might perform significantly better or worse from one game to the next, Elo assumed that the mean value of the performances of any given player changes only slowly over time. Elo thought of a player's true skill as the mean of that player's performance random variable.
A further assumption is necessary because chess performance in the above sense is still not measurable. One cannot look at a sequence of moves and derive a number to represent that player's skill. Performance can only be inferred from wins, draws and losses. Therefore, if a player wins a game, they are assumed to have performed at a higher level than their opponent for that game. Conversely, if the player loses, they are assumed to have performed at a lower level. If the game is a draw, the two players are assumed to have performed at nearly the same level.
Elo did not specify exactly how close two performances ought to be to result in a draw as opposed to a win or loss. And while he thought it was likely that players might have different standard deviations to their performances, he made a simplifying assumption to the contrary.
To simplify computation even further, Elo proposed a straightforward method of estimating the variables in his model (i.e., the true skill of each player). One could calculate relatively easily from tables how many games players would be expected to win based on comparisons of their ratings to those of their opponents. The ratings of a player who won more games than expected would be adjusted upward, while those of a player who won fewer than expected would be adjusted downward. Moreover, that adjustment was to be in linear proportion to the number of wins by which the player had exceeded or fallen short of their expected number.
From a modern perspective, Elo's simplifying assumptions are not necessary because computing power is inexpensive and widely available. Moreover, even within the simplified model, more efficient estimation techniques are well known. Several people, most notably Mark Glickman, have proposed using more sophisticated statistical machinery to estimate the same variables. On the other hand, the computational simplicity of the Elo system has proven to be one of its greatest assets. With the aid of a pocket calculator, an informed chess competitor can calculate to within one point what their next officially published rating will be, which helps promote a perception that the ratings are fair.
Implementing Elo's scheme
The USCF implemented Elo's suggestions in 1960,[4] and the system quickly gained recognition as being both fairer and more accurate than the Harkness rating system. Elo's system was adopted by the World Chess Federation (FIDE) in 1970. Elo described his work in some detail in the book The Rating of Chessplayers, Past and Present, published in 1978.
Subsequent statistical tests have suggested that chess performance is almost certainly not distributed as a normal distribution, as weaker players have greater winning chances than Elo's model predicts. Therefore, the USCF and some chess sites use a formula based on the logistic distribution. Significant statistical anomalies have also been found when using the logistic distribution in chess.[5] FIDE continues to use the rating difference table as proposed by Elo. The table is calculated with expectation 0, and standard deviation 200.
The normal and logistic distribution points are, in a way, arbitrary points in a spectrum of distributions which would work well. In practice, both of these distributions work very well for a number of different games.
Different ratings systems
The phrase "Elo rating" is often used to mean a player's chess rating as calculated by FIDE. However, this usage is confusing and misleading because Elo's general ideas have been adopted by many organizations, including the USCF (before FIDE), many other national chess federations, the short-lived Professional Chess Association (PCA), and online chess servers including the Internet Chess Club (ICC), Free Internet Chess Server (FICS), and Yahoo! Games. Each organization has a unique implementation, and none of them follows Elo's original suggestions precisely. It would be more accurate to refer to all of the above ratings as Elo ratings and none of them as the Elo rating.
Instead one may refer to the organization granting the rating. For example: "As of August 2002, Gregory Kaidanov had a FIDE rating of 2638 and a USCF rating of 2742." The Elo ratings of these various organizations are not always directly comparable, since Elo ratings measure the results within a closed pool of players rather than absolute skill. There are also differences in the way organizations implement Elo ratings.
FIDE ratings
For top players, the most important rating is their FIDE rating. FIDE has issued the following lists:
- From 1971 to 1980, one list a year was issued.
- From 1981 to 2000, two lists a year were issued, in January and July.
- From July 2000 to July 2009, four lists a year were issued, at the start of January, April, July and October.
- From July 2009 to July 2012, six lists a year were issued, at the start of January, March, May, July, September and November.
- Since July 2012, the list has been updated monthly.
The following analysis of the July 2015 FIDE rating list gives a rough impression of what a given FIDE rating means in terms of world ranking:
- 5323 players had an active rating in the range 2200 to 2299, which is usually associated with the Candidate Master title.
- 2869 players had an active rating in the range 2300 to 2399, which is usually associated with the FIDE Master title.
- 1420 players had an active rating between 2400 and 2499, most of whom had either the International Master or the International Grandmaster title.
- 542 players had an active rating between 2500 and 2599, most of whom had the International Grandmaster title.
- 187 players had an active rating between 2600 and 2699, all of whom had the International Grandmaster title.
- 40 players had an active rating between 2700 and 2799.
- 4 players had an active rating of over 2800. (Magnus Carlsen was rated 2853, and 3 players were rated between 2814 and 2816).
The highest ever FIDE rating was 2882, which Magnus Carlsen had on the May 2014 list. A list of the highest-rated players ever is at Comparison of top chess players throughout history.
Performance rating
| 1.00 | +800 |
| 0.99 | +677 |
| 0.9 | +366 |
| 0.8 | +240 |
| 0.7 | +149 |
| 0.6 | +72 |
| 0.5 | 0 |
| 0.4 | −72 |
| 0.3 | −149 |
| 0.2 | −240 |
| 0.1 | −366 |
| 0.01 | −677 |
| 0.00 | −800 |


Performance rating is a hypothetical rating that would result from the games of a single event only. Some chess organizations use the "algorithm of 400" to calculate performance rating. According to this algorithm, performance rating for an event is calculated in the following way:
- For each win, add your opponent's rating plus 400,
- For each loss, add your opponent's rating minus 400,
- And divide this sum by the number of played games.
Example: 2 wins, 2 losses

This can be expressed by the following formula:

Example: If you beat a player with an Elo rating of 1000,

If you beat two players with Elo ratings of 1000,

If you draw,

This is a simplification, but it offers an easy way to get an estimate of PR (performance rating).
FIDE, however, calculates performance rating by means of the formula: Opponents' Rating Average + Rating Difference. Rating Difference is based on a player's tournament percentage score , which is then used as the key in a lookup table where is simply the number of points scored divided by the number of games played. Note that, in case of a perfect or no score is 800. The full table can be found in the Manual de la FIDE, B. Permanent Commissions, 02. FIDE Rating Regulations (Qualification Commission), FIDE Rating Regulations effective from 1 July 2017, 8.1a online. A simplified version of this table is on the right.
FIDE tournament categories
| Category | Average rating | |
|---|---|---|
| Minimum | Maximum | |
| 14 | 2576 | 2600 |
| 15 | 2601 | 2625 |
| 16 | 2626 | 2650 |
| 17 | 2651 | 2675 |
| 18 | 2676 | 2700 |
| 19 | 2701 | 2725 |
| 20 | 2726 | 2750 |
| 21 | 2751 | 2775 |
| 22 | 2776 | 2800 |
| 23 | 2801 | 2825 |
FIDE classifies tournaments into categories according to the average rating of the players. Each category is 25 rating points wide. Category 1 is for an average rating of 2251 to 2275, category 2 is 2276 to 2300, etc. For women's tournaments, the categories are 200 rating points lower, so a Category 1 is an average rating of 2051 to 2075, etc.[6] The highest-rated tournament has been category 23, with an average from 2801 to 2825. The top categories are in the table.
Live ratings
FIDE updates its ratings list at the beginning of each month. In contrast, the unofficial "Live ratings" calculate the change in players' ratings after every game. These Live ratings are based on the previously published FIDE ratings, so a player's Live rating is intended to correspond to what the FIDE rating would be if FIDE were to issue a new list that day.
Although Live ratings are unofficial, interest arose in Live ratings in August/September 2008 when five different players took the "Live" No. 1 ranking.[7]
The unofficial live ratings of players over 2700 were published and maintained by Hans Arild Runde at the Live Rating website until August 2011. Another website, 2700chess.com, has been maintained since May 2011 by Artiom Tsepotan, which covers the top 100 players as well as the top 50 female players.
Rating changes can be calculated manually by using the FIDE ratings change calculator.[8] All top players have a K-factor of 10, which means that the maximum ratings change from a single game is a little less than 10 points.
United States Chess Federation ratings
The United States Chess Federation (USCF) uses its own classification of players:[9]
- 2400 and above: Senior Master
- 2200–2399: National Master
- 2200–2399 plus 300 games above 2200: Original Life Master[10]
- 2000–2199: Expert or Candidate Master
- 1800–1999: Class A
- 1600–1799: Class B
- 1400–1599: Class C
- 1200–1399: Class D
- 1000–1199: Class E
- 800–999: Class F
- 600–799: Class G
- 400–599: Class H
- 200–399: Class I
- 100–199: Class J
In general, a beginner (non-scholastic) is 800, the average player is 1500, and professional level is 2200.
The K-factor used by the USCF
The K-factor, in the USCF rating system, can be estimated by dividing 800 by the effective number of games a player's rating is based on (Ne) plus the number of games the player completed in a tournament (m).[11]

Rating floors
The USCF maintains an absolute rating floor of 100 for all ratings. Thus, no member can have a rating below 100, no matter their performance at USCF-sanctioned events. However, players can have higher individual absolute rating floors, calculated using the following formula:

where is the number of rated games won, is the number of rated games drawn, and is the number of events in which the player completed three or more rated games.



Higher rating floors exist for experienced players who have achieved significant ratings. Such higher rating floors exist, starting at ratings of 1200 in 100-point increments up to 2100 (1200, 1300, 1400, ..., 2100). A rating floor is calculated by taking the player's peak established rating, subtracting 200 points, and then rounding down to the nearest rating floor. For example, a player who has reached a peak rating of 1464 would have a rating floor of 1464 − 200 = 1264, which would be rounded down to 1200. Under this scheme, only Class C players and above are capable of having a higher rating floor than their absolute player rating. All other players would have a floor of at most 150.
There are two ways to achieve higher rating floors other than under the standard scheme presented above. If a player has achieved the rating of Original Life Master, their rating floor is set at 2200. The achievement of this title is unique in that no other recognized USCF title will result in a new floor. For players with ratings below 2000, winning a cash prize of $2,000 or more raises that player's rating floor to the closest 100-point level that would have disqualified the player for participation in the tournament. For example, if a player won $4,000 in a 1750-and-under tournament, they would now have a rating floor of 1800.
Theory
Pairwise comparisons form the basis of the Elo rating methodology.[12] Elo made references to the papers of Good,[13] David,[14] Trawinski and David,[15] and Buhlman and Huber.[16]
Mathematical details
Performance is not measured absolutely; it is inferred from wins, losses, and draws against other players. Players' ratings depend on the ratings of their opponents and the results scored against them. The difference in rating between two players determines an estimate for the expected score between them. Both the average and the spread of ratings can be arbitrarily chosen. Elo suggested scaling ratings so that a difference of 200 rating points in chess would mean that the stronger player has an expected score (which basically is an expected average score) of approximately 0.75, and the USCF initially aimed for an average club player to have a rating of 1500.
A player's expected score is their probability of winning plus half their probability of drawing. Thus, an expected score of 0.75 could represent a 75% chance of winning, 25% chance of losing, and 0% chance of drawing. On the other extreme it could represent a 50% chance of winning, 0% chance of losing, and 50% chance of drawing. The probability of drawing, as opposed to having a decisive result, is not specified in the Elo system. Instead, a draw is considered half a win and half a loss. In practice, since the true strength of each player is unknown, the expected scores are calculated using the player's current ratings as follows.
If Player A has a rating of and Player B a rating of , the exact formula (using the logistic curve)[12] for the expected score of Player A is



Similarly the expected score for Player B is

This could also be expressed by

and

where and . Note that in the latter case, the same denominator applies to both expressions, and it is plain that . This means that by studying only the numerators, we find out that the expected score for player A is times greater than the expected score for player B. It then follows that for each 400 rating points of advantage over the opponent, the expected score is magnified ten times in comparison to the opponent's expected score.




When a player's actual tournament scores exceed their expected scores, the Elo system takes this as evidence that player's rating is too low, and needs to be adjusted upward. Similarly, when a player's actual tournament scores fall short of their expected scores, that player's rating is adjusted downward. Elo's original suggestion, which is still widely used, was a simple linear adjustment proportional to the amount by which a player overperformed or underperformed their expected score. The maximum possible adjustment per game, called the K-factor, was set at K = 16 for masters and K = 32 for weaker players.
Supposing Player A was expected to score points but actually scored points. The formula for updating that player's rating is



This update can be performed after each game or each tournament, or after any suitable rating period. An example may help to clarify. Suppose Player A has a rating of 1613 and plays in a five-round tournament. They lose to a player rated 1609, draw with a player rated 1477, defeat a player rated 1388, defeat a player rated 1586, and lose to a player rated 1720. The player's actual score is (0 + 0.5 + 1 + 1 + 0) = 2.5. The expected score, calculated according to the formula above, was (0.51 + 0.69 + 0.79 + 0.54 + 0.35) = 2.88. Therefore, the player's new rating is (1613 + 32(2.5 − 2.88)) = 1601, assuming that a K-factor of 32 is used. Equivalently, each game the player can be said to have put an ante of K times their expected score for the game into a pot, the opposing player does likewise, and the winner collects the full pot of value K; in the event of a draw, the players split the pot and receive K/2 points each.
Note that while two wins, two losses, and one draw may seem like a par score, it is worse than expected for Player A because their opponents were lower rated on average. Therefore, Player A is slightly penalized. If Player A had scored two wins, one loss, and two draws, for a total score of three points, that would have been slightly better than expected, and the player's new rating would have been (1613 + 32(3 − 2.88)) = 1617.
This updating procedure is at the core of the ratings used by FIDE, USCF, Yahoo! Games, the Internet Chess Club (ICC) and the Free Internet Chess Server (FICS). However, each organization has taken a different route to deal with the uncertainty inherent in the ratings, particularly the ratings of newcomers, and to deal with the problem of ratings inflation/deflation. New players are assigned provisional ratings, which are adjusted more drastically than established ratings.
The principles used in these rating systems can be used for rating other competitions—for instance, international football matches.
Elo ratings have also been applied to games without the possibility of draws, and to games in which the result can also have a quantity (small/big margin) in addition to the quality (win/loss). See Go rating with Elo for more.
Most accurate distribution model
The first mathematical concern addressed by the USCF was the use of the normal distribution. They found that this did not accurately represent the actual results achieved, particularly by the lower rated players. Instead they switched to a logistic distribution model, which the USCF found provided a better fit for the actual results achieved. FIDE also uses an approximation to the logistic distribution.[17]
Most accurate K-factor
The second major concern is the correct "K-factor" used. The chess statistician Jeff Sonas believes that the original K=10 value (for players rated above 2400) is inaccurate in Elo's work. If the K-factor coefficient is set too large, there will be too much sensitivity to just a few, recent events, in terms of a large number of points exchanged in each game. And if the K-value is too low, the sensitivity will be minimal, and the system will not respond quickly enough to changes in a player's actual level of performance.
Elo's original K-factor estimation was made without the benefit of huge databases and statistical evidence. Sonas indicates that a K-factor of 24 (for players rated above 2400) may be more accurate both as a predictive tool of future performance, and also more sensitive to performance.[18]
Certain Internet chess sites seem to avoid a three-level K-factor staggering based on rating range. For example, the ICC seems to adopt a global K=32 except when playing against provisionally rated players.
The USCF (which makes use of a logistic distribution as opposed to a normal distribution) formerly staggered the K-factor according to three main rating ranges of:
- Players below 2100: K-factor of 32 used
- Players between 2100 and 2400: K-factor of 24 used
- Players above 2400: K-factor of 16 used.
Currently, the USCF uses a formula that calculates the K-factor based on factors including the number of games played and the player's rating. The K-factor is also reduced for high rated players if the event has shorter time controls.[19]
FIDE uses the following ranges:[20]
- K = 40, for a player new to the rating list until the completion of events with a total of 30 games and for all players until their 18th birthday, as long as their rating remains under 2300.
- K = 20, for players with a rating always under 2400.
- K = 10, for players with any published rating of at least 2400 and at least 30 games played in previous events. Thereafter it remains permanently at 10.
FIDE used the following ranges before July 2014:[21]
- K = 30 (was 25), for a player new to the rating list until the completion of events with a total of 30 games.[22]
- K = 15, for players with a rating always under 2400.
- K = 10, for players with any published rating of at least 2400 and at least 30 games played in previous events. Thereafter it remains permanently at 10.
The gradation of the K-factor reduces ratings changes at the top end of the rating spectrum, reducing the possibility for rapid ratings inflation or deflation for those with a low K-factor. This might in theory apply equally to an online chess site or over-the-board players, since it is more difficult for players to get much higher ratings when their K-factor is reduced. When playing online, it may simply be the selection of highly rated opponents that enables 2800+ players to further increase their rating,[23] since a grandmaster on the ICC playing site can play a string of different opponents who are all rated over 2700. In over-the-board events, it would only be in very high level all-play-all events that a player would be able to engage that number of 2700+ opponents, while in a normal open Swiss-paired chess tournament, frequently there would be many opponents rated less than 2500, reducing the ratings gains possible from a single contest.
Practical issues
Game activity versus protecting one's rating
In some cases the rating system can discourage game activity for players who wish to protect their rating.[24] In order to discourage players from sitting on a high rating, a 2012 proposal by British Grandmaster John Nunn for choosing qualifiers to the chess world championship included an activity bonus, to be combined with the rating.[25]
Beyond the chess world, concerns over players avoiding competitive play to protect their ratings caused Wizards of the Coast to abandon the Elo system for Magic: the Gathering tournaments in favour of a system of their own devising called "Planeswalker Points".[26][27]
Selective pairing
A more subtle issue is related to pairing. When players can choose their own opponents, they can choose opponents with minimal risk of losing, and maximum reward for winning. Particular examples of players rated 2800+ choosing opponents with minimal risk and maximum possibility of rating gain include: choosing computers that they know they can beat with a certain strategy; choosing opponents that they think are overrated; or avoiding playing strong players who are rated several hundred points below them, but may hold chess titles such as IM or GM. In the category of choosing overrated opponents, new entrants to the rating system who have played fewer than 50 games are in theory a convenient target as they may be overrated in their provisional rating. The ICC compensates for this issue by assigning a lower K-factor to the established player if they do win against a new rating entrant. The K-factor is actually a function of the number of rated games played by the new entrant.
Therefore, Elo ratings online still provide a useful mechanism for providing a rating based on the opponent's rating. Its overall credibility, however, needs to be seen in the context of at least the above two major issues described — engine abuse, and selective pairing of opponents.
The ICC has also recently introduced "auto-pairing" ratings which are based on random pairings, but with each win in a row ensuring a statistically much harder opponent who has also won x games in a row. With potentially hundreds of players involved, this creates some of the challenges of a major large Swiss event which is being fiercely contested, with round winners meeting round winners. This approach to pairing certainly maximizes the rating risk of the higher-rated participants, who may face very stiff opposition from players below 3000, for example. This is a separate rating in itself, and is under "1-minute" and "5-minute" rating categories. Maximum ratings achieved over 2500 are exceptionally rare.
Ratings inflation and deflation
An increase or decrease in the average rating over all players in the rating system is often referred to as rating inflation or rating deflation respectively. For example, if there is inflation, a modern rating of 2500 means less than a historical rating of 2500, while the reverse is true if there is deflation. Using ratings to compare players between different eras is made more difficult when inflation or deflation are present. (See also Comparison of top chess players throughout history.)
It is commonly believed that, at least at the top level, modern ratings are inflated. For instance Nigel Short said in September 2009, "The recent ChessBase article on rating inflation by Jeff Sonas would suggest that my rating in the late 1980s would be approximately equivalent to 2750 in today's much debauched currency".[28] Short's rating in 1988 was 2665, which placed him third in the world. By 2009 when he made this comment, 2665 would only have ranked him 65th, while 2750 would have ranked him equal 10th.
It has been suggested that an overall increase in ratings reflects greater skill. The advent of strong chess computers allows a somewhat objective evaluation of the absolute playing skill of past chess masters, based on their recorded games, but this is also a measure of how computerlike the players' moves are, not merely a measure of how strongly they have played.[29]
The number of people with ratings over 2700 has increased. Around 1979 there was only one active player (Anatoly Karpov) with a rating this high. In 1992 Viswanathan Anand was only the 8th player in chess history to reach the 2700 mark at that point of time.[30] This increased to 15 players by 1994. 33 players had a 2700+ rating in 2009 and 44 as of September 2012. The current benchmark for elite players lies beyond 2800.
One possible cause for this inflation was the rating floor, which for a long time was at 2200, and if a player dropped below this they were stricken from the rating list. As a consequence, players at a skill level just below the floor would only be on the rating list if they were overrated, and this would cause them to feed points into the rating pool.[29] In July 2000 the average rating of the top 100 was 2644. By July 2012 it had increased to 2703.[30]
In a pure Elo system, each game ends in an equal transaction of rating points. If the winner gains N rating points, the loser will drop by N rating points. This prevents points from entering or leaving the system when games are played and rated. However, players tend to enter the system as novices with a low rating and retire from the system as experienced players with a high rating. Therefore, in the long run a system with strictly equal transactions tends to result in rating deflation.[31]
In 1995, the USCF acknowledged that several young scholastic players were improving faster than the rating system was able to track. As a result, established players with stable ratings started to lose rating points to the young and underrated players. Several of the older established players were frustrated over what they considered an unfair rating decline, and some even quit chess over it.[32]
Combating deflation
Because of the significant difference in timing of when inflation and deflation occur, and in order to combat deflation, most implementations of Elo ratings have a mechanism for injecting points into the system in order to maintain relative ratings over time. FIDE has two inflationary mechanisms. First, performances below a "ratings floor" are not tracked, so a player with true skill below the floor can only be unrated or overrated, never correctly rated. Second, established and higher-rated players have a lower K-factor. New players have a K = 40, which drops to K = 20 after 30 played games, and to K = 10 when the player reaches 2400.[20] The current system in the United States includes a bonus point scheme which feeds rating points into the system in order to track improving players, and different K-values for different players.[32] Some methods, used in Norway for example, differentiate between juniors and seniors, and use a larger K-factor for the young players, even boosting the rating progress by 100% for when they score well above their predicted performance.[33]
Rating floors in the United States work by guaranteeing that a player will never drop below a certain limit. This also combats deflation, but the chairman of the USCF Ratings Committee has been critical of this method because it does not feed the extra points to the improving players. A possible motive for these rating floors is to combat sandbagging, i.e., deliberate lowering of ratings to be eligible for lower rating class sections and prizes.[32]
Ratings of computers
Human–computer chess matches between 1997 (Deep Blue versus Garry Kasparov) and 2006 demonstrated that chess computers are capable of defeating even the strongest human players. However, chess engine ratings are difficult to quantify, due to variable factors such as the time control and the hardware the program runs on. Published engine rating lists such as CCRL are based on engine-only games on standard hardware configurations and are not directly comparable to FIDE ratings.
For some ratings estimates, see Chess engine § Ratings.
Use outside of chess
Athletic sports
The Elo rating system is used in the chess portion of chess boxing. In order to be eligible for professional chess boxing, one must have an Elo rating of at least 1600, as well as competing in 50 or more matches of amateur boxing or martial arts.
American college football used the Elo method as a portion of its Bowl Championship Series rating systems from 1998 to 2013 after which the BCS was replaced by the College Football Playoff. Jeff Sagarin of USA Today publishes team rankings for most American sports, which includes Elo system ratings for college football. The use of rating systems was effectively scrapped with the creation of the College Football Playoff in 2014; participants in the CFP and its associated bowl games are chosen by a selection committee.
In other sports, individuals maintain rankings based on the Elo algorithm. These are usually unofficial, not endorsed by the sport's governing body. The World Football Elo Ratings is an example of the method applied to men's football.[34] In 2006, Elo ratings were adapted for Major League Baseball teams by Nate Silver, then of Baseball Prospectus.[35] Based on this adaptation, both also made Elo-based Monte Carlo simulations of the odds of whether teams will make the playoffs.[36] In 2014, Beyond the Box Score, an SB Nation site, introduced an Elo ranking system for international baseball.[37]
In tennis, the Elo-based Universal Tennis Rating (UTR) rates players on a global scale, regardless of age, gender, or nationality. It is the official rating system of major organizations such as the Intercollegiate Tennis Association and World TeamTennis and is frequently used in segments on the Tennis Channel. The algorithm analyzes more than 8 million match results from over 800,000 tennis players worldwide. On May 8, 2018, Rafael Nadal – having won 46 consecutive sets in clay court matches – had a near-perfect clay UTR of 16.42.[38]
One of the few Elo-based rankings endorsed by a sport's governing body is the FIFA Women's World Rankings, based on a simplified version of the Elo algorithm, which FIFA uses as its official ranking system for national teams in women's football.
From the first ranking list after the 2018 FIFA World Cup, FIFA has used Elo for their FIFA World Rankings.[39]
In 2015, Nate Silver, editor-in-chief of the statistical commentary website FiveThirtyEight, and Reuben Fischer-Baum produced Elo ratings for every National Basketball Association team and season through the 2014 season.[40] In 2014 FiveThirtyEight created Elo-based ratings and win-projections for the American professional National Football League.[41]
The English Korfball Association rated teams based on Elo ratings, to determine handicaps for their cup competition for the 2011/12 season.
An Elo-based ranking of National Hockey League players has been developed.[42] The hockey-Elo metric evaluates a player's overall two-way play: scoring AND defense in both even strength and power-play/penalty-kill situations.
Rugbyleagueratings.com uses the Elo rating system to rank international and club rugby league teams.
Other board and card games
National Scrabble organizations compute normally distributed Elo ratings except in the United Kingdom, where a different system is used. The North American Scrabble Players Association has the largest rated population of active members, numbering about 2,000 as of early 2011. Lexulous also uses the Elo system.
The popular First Internet Backgammon Server (FIBS) calculates ratings based on a modified Elo system. New players are assigned a rating of 1500, with the best humans and bots rating over 2000. The same formula has been adopted by several other backgammon sites, such as Play65, DailyGammon, GoldToken and VogClub. VogClub sets a new player's rating at 1600. The UK Backgammon Federation uses the FIBS formula for its UK national ratings.[43]
The European Go Federation adopted an Elo-based rating system initially pioneered by the Czech Go Federation.
Despite questions of the appropriateness of using the Elo system to rate games in which luck is a factor, trading-card game manufacturers often use Elo ratings for their organized play efforts. The DCI (formerly Duelists' Convocation International) used Elo ratings for tournaments of Magic: The Gathering and other Wizards of the Coast games. However, the DCI abandoned this system in 2012 in favour of a new cumulative system of "Planeswalker Points", chiefly because of the above-noted concern that Elo encourages highly rated players to avoid playing to "protect their rating".[26][27] Pokémon USA uses the Elo system to rank its TCG organized play competitors.[44] Prizes for the top players in various regions included holidays and world championships invites until the 2011–2012 season, where awards were based on a system of Championship Points, their rationale being the same as the DCI's for Magic: The Gathering. Similarly, Decipher, Inc. used the Elo system for its ranked games such as Star Trek Customizable Card Game and Star Wars Customizable Card Game.
Video games and online games
The Esports game Overwatch, the basis of the unique Overwatch League professional sports organization, uses a derivative of the Elo system to rank competitive players with various adjustments made between competitive seasons.[45]
Leagues and match-makers for the skill-based game Counter-Strike: Global Offensive use Elo ratings such as ESEA League and Faceit; however, the game's own matchmaking system uses Glicko-2. Nevertheless, it is common for players of ranked video games to refer to all ratings as an Elo.
According to Lichess, the Elo system is outdated even by chess standards, with Glicko-2 now being used by many chess organisations.[46]
Various online games use Elo ratings for player-versus-player rankings. Since 2005, Golden Tee Live has rated players based on the Elo system. New players start at 2100, with top players rating over 3000.[47] In Guild Wars, Elo ratings are used to record guild rating gained and lost through guild versus guild battles, which are two-team fights. The initial K-value was 30, but was changed to 5 in January 2007, then changed to 15 in July 2009.[48] World of Warcraft formerly used the Elo rating system when teaming up and comparing Arena players, but now uses a system similar to Microsoft's TrueSkill.[49] The MOBA game League of Legends used an Elo rating system prior to the second season of competitive play.[50] The game Puzzle Pirates uses the Elo rating system to determine the standings in the various puzzles. Roblox introduced the Elo rating in 2010. The browser game Quidditch Manager uses the Elo rating to measure a team's performance.[51] Another recent game to start using the Elo rating system is AirMech, using Elo[52] ratings for 1v1, 2v2, and 3v3 random/team matchmaking. RuneScape 3 was to use the Elo system for the rerelease of bounty hunter in 2016.[53] Mechwarrior Online instituted an Elo system for its new "Comp Queue" mode, effective with the Jun 20, 2017 patch.[54]
In 1998[55] an online gaming ladder called Clanbase[56] was launched, who used the Elo scoring system to rank teams. The site later went offline in 2013.[57] A similar alternative site was launched in 2016 under the name Scrimbase[58] and they are also using the Elo scoring system for ranking teams.
If you are a PlayerUnknown’s Battlegrounds fanatic, you will be surprised to know it is one of the few video games that utilize the very first Elo system. The original Elo rating system works under a very basic concept; winning will increase your rating, while losing will decrease it. With that said, the fluctuations in the ratings aren’t overly abrupt, meaning losing a single game doesn’t necessarily spell doom.
Overwatch is also another video game that uses a derivative Elo-like rating system to rank competitive players, although various adjustments are made in between the competitive seasons.
When it comes to Guild Wars, which is an MMORPG, Elo ratings come in handy when recording the guild ratings gained and lost in the guild versus guild battles. In Counter-Strike: Global Offensive, leagues and match-makers also use an Elo-style rating system called Glicko-2, with World of Warcraft having previously used it to team up and compare Arena players.
Likewise, League of Legends initially used the classic Elo rating system. After season three, however, the game owners decided to deploy their own customized system. Other notable mentions using modified Elo rating versions include Puzzle Pirates, Roblox, Mechwarrior Online, and Quidditch Manager AirMech.[59]
Other usage
The Elo rating system has been used in soft biometrics,[60] which concerns the identification of individuals using human descriptions. Comparative descriptions were utilized alongside the Elo rating system to provide robust and discriminative 'relative measurements', permitting accurate identification.
The Elo rating system has also been used in biology for assessing male dominance hierarchies,[61] and in automation and computer vision for fabric inspection.[62]
Moreover, online judge sites are also using Elo rating system or its derivatives. For example, Topcoder is using a modified version based on normal distribution,[63] while Codeforces is using another version based on logistic distribution.[64][65][66]
Elo rating system has also been noted in dating apps, such as in the matchmaking app Tinder, which uses a variant of the Elo rating system.[67]
References in the media
The Elo rating system was featured prominently in The Social Network during the algorithm scene where Mark Zuckerberg released Facemash. In the scene Eduardo Saverin writes mathematical formulas for the Elo rating system on Zuckerberg's dormitory room window. Behind the scenes, the movie claims, the Elo system is employed to rank girls by their attractiveness. The equations driving the algorithm are shown briefly, written on the window;[68] however, they are slightly incorrect.
See also
- Chess rating system, discusses other chess rating systems
- Glicko rating system, the rating methods developed by Mark Glickman
- Elo hell
- Bradley–Terry model
Notes
- In English, this is variously pronounced as /ˈiːloʊ/, /ˈɛloʊ/, or even /ˌiːɛlˈoʊ/ as if it were the initialism E-L-O. The original name Élő is pronounced [ˈeːløː] (
 listen) in Hungarian.
listen) in Hungarian.
References
- Nate Silver and Reuben Fischer-Baum, "How We Calculate NBA Elo Ratings," FiveThirtyEight.com, May 21, 2015.
- Wood, Ben. "Enemydown uses Elo in its Counterstrike:Source Multilplayer Ladders". TNWA Group. Archived from the original on 2009-06-12.
- Redman, Tim (July 2002). "Remembering Richard, Part II" (PDF). Illinois Chess Bulletin. Archived (PDF) from the original on 2020-06-30. Retrieved 2020-06-30.
- "About the USCF". United States Chess Federation. Retrieved 2008-11-10.
- "Deloitte Chess Rating Competition".
- FIDE Handbook, Section B.0.0, FIDE web site
- Anand lost No. 1 to Morozevich (Chessbase, August 24 2008), then regained it, then Carlsen took No. 1 (Chessbase, September 5 2008), then Ivanchuk (Chessbase, September 11 2008), and finally Topalov (Chessbase, September 13 2008)
- Administrator. "FIDE Chess Rating calculators: Chess Rating change calculator". ratings.fide.com.
- US Chess Federation Archived 2012-06-18 at the Wayback Machine
- USCF Glossary Quote:"a player who competes in over 300 games with a rating over 2200" from The United States Chess Federation
- "Approximating Formulas for the US Chess Rating System" Archived 2019-11-04 at the Wayback Machine, United States Chess Federation, Mark Glickman, April 2017
- Elo, Arpad E (2008). "8.4 Logistic Probability as a Rating Basis". The Rating of Chessplayers, Past&Present. Bronx NY 10453: ISHI Press International. ISBN 978-0-923891-27-5.CS1 maint: location (link)
- Good, I.J. (1955). "On the Marking of Chessplayers". The Mathematical Gazette. 39 (330): 292–296. doi:10.2307/3608567. JSTOR 3608567.
- David, H. A. (1959). "Tournaments and Paired Comparisons". Biometrika. 46 (1/2): 139–149. doi:10.2307/2332816.
- Trawinski, B.J.; David, H.A. (1963). "Selection of the Best Treatment in a Paired-Comparison Experiment". Annals of Mathematical Statistics. 34 (1): 75–91. doi:10.1214/aoms/1177704243.
- Buhlmann, Hans; Huber, Peter J. (1963). "Pairwise Comparison and Ranking in Tournaments". The Annals of Mathematical Statistics. 34 (2): 501–510. doi:10.1214/aoms/1177704161.
- "FIDE Rating Regulations effective from 1 July 2017". FIDE. Retrieved 2017-09-09.
- A key Sonas article is Jeff Sonas: The Sonas Rating Formula — Better than Elo?
- "The US Chess Rating system" (PDF). April 24, 2017. Retrieved 16 February 2020.
- "FIDE Online. FIDE Rating Regulations effective from 1 July 2014". Fide.com. 2014-07-01. Retrieved 2014-07-01.
- "FIDE Online. FIDE Rating Regulations valid from 1 July 2013 till 1 July 2014". Fide.com. 2013-07-01. Retrieved 2014-07-01.
- "FIDE Online. Changes to Rating Regulations news release". Fide.com. 2011-07-21. Retrieved 2012-02-19.
- "ICC Help: k-factor". Chessclub.com. 2002-10-18. Archived from the original on 2012-03-13. Retrieved 2012-02-19.
- A Parent's Guide to Chess Skittles, Don Heisman, Chesscafe.com, August 4, 2002
- "Chess News – The Nunn Plan for the World Chess Championship". ChessBase.com. Retrieved 2012-02-19.
- "Introducing Planeswalker Points". September 6, 2011. Retrieved September 9, 2011.
- "Getting to the Points". September 9, 2011. Retrieved September 9, 2011.
- Nigel Short on being number one in Britain again, Chessbase, 4 September 2009
- Sonas, Jeff (July 27, 2009). "Rating Inflation – Its Causes and Possible Cures". ChessBase. Retrieved 2009-08-23.
- "Viswanathan Anand". Chessgames.com.
- Bergersen, Per A. "ELO-SYSTEMET" (in Norwegian). Norwegian Chess Federation. Archived from the original on 8 March 2013. Retrieved 21 October 2013.
- A conversation with Mark Glickman , Published in Chess Life October 2006 issue
- "Archived copy". Archived from the original on March 8, 2013. Retrieved 2009-08-23.CS1 maint: archived copy as title (link)
- Lyons, Keith. "What are the World Football Elo Ratings?". The Conversation. Retrieved 3 July 2019.
- Nate Silver, "We Are Elo?" June 28, 2006. Archived 2006-08-22 at the Wayback Machine
- "Postseason Odds, ELO version". Baseballprospectus.com. Retrieved 2012-02-19.
- Cole, Bryan (August 15, 2014). "Elo rankings for international baseball". Beyond the Box Score. SB Nation. Retrieved 4 November 2015.
- "Is Rafa the GOAT of Clay?". 8 May 2018.
- "Revision of the FIFA/Coca-Cola World Ranking" (PDF). FIFA. June 2018. Archived from the original (PDF) on 2018-06-12. Retrieved 2020-06-30.
- "How We Calculate NBA Elo Ratings," FiveThirtyEight, May 21, 2015.. Also see Reuben Fischer-Baum and Nate Silver, "The Complete History of the NBA," FiveThirtyEight, May 21, 2015.
- Nate Silver, "Introducing NFL Elo Ratings," September 4, 2014, and Neil Paine, "NFL Elo Ratings Are Back," FiveThirtyEight, September 10, 2015.
- "Hockey Stats Revolution – How do teams pick players?". Hockey Stats Revolution. Retrieved 2016-09-29.
- "Backgammon Ratings Explained". results.ukbgf.com. Archived from the original on 2019-11-14. Retrieved 2020-06-01.
- "Play! Pokémon Glossary: Elo". Retrieved January 15, 2015.
- "Welcome to Season 8 of competitive play". PlayOverwatch.com. Blizzard Entertainment. Retrieved 11 March 2018.
- "Frequently Asked Questions: ratings". lichess.org.
- "Golden Tee Fan Player Rating Page". Retrieved 2013-12-31.
- "Guild ladder". Wiki.guildwars.com. Archived from the original on 2012-03-01. Retrieved 2012-02-19.
- "World of Warcraft Europe -> The Arena". Wow-europe.com. 2011-12-14. Archived from the original on 2010-09-23. Retrieved 2012-02-19.
- "Matchmaking | LoL – League of Legends". Na.leagueoflegends.com. 2010-07-06. Retrieved 2012-02-19.
- "Quidditch Manager – Help and Rules". Quidditch-Manager.com. 2012-08-25. Archived from the original on 2013-10-21. Retrieved 2013-10-20.
- "AirMech developer explains why they use Elo". Retrieved January 15, 2015.
- http://services.runescape.com/m=news/design-doc--bounty-hunter--deathmatch-pvp?acq_id=3001
- "MWO: News". mwomercs.com.
- "Earliest known launch date of Clanbase.com". Retrieved 2017-10-29.
- "Weyback Machine record of Clanbase.com". Archived from the original on 2017-11-05. Retrieved 2017-10-29.
- "Clanbase farewell message". Retrieved 2017-10-29.
- "Scrimbase Gaming Ladder". Retrieved 2017-10-29.
- "Wondering How Elo Rating System is Used? Brief info". Askboosters. 2019-09-04. Retrieved 2021-02-01.
- "Using Comparative Human Descriptions for Soft Biometrics" Archived 2013-03-08 at the Wayback Machine, D.A. Reid and M.S. Nixon, International Joint Conference on Biometrics (IJCB), 2011
- Pörschmann; et al. (2010). "Male reproductive success and its behavioural correlates in a polygynous mammal, the Galápagos sea lion (Zalophus wollebaeki)". Molecular Ecology. 19 (12): 2574–86. doi:10.1111/j.1365-294X.2010.04665.x. PMID 20497325.
- Tsang; et al. (2016). "Fabric inspection based on the Elo rating method". Pattern Recognition. 51: 378–394. doi:10.1016/j.patcog.2015.09.022.
- "Algorithm Competition Rating System". December 23, 2009. Archived from the original on September 2, 2011. Retrieved September 16, 2011.
- "FAQ: What are the rating and the divisions?". Retrieved September 16, 2011.
- "Rating Distribution". Retrieved September 16, 2011.
- "Regarding rating: Part 2". Retrieved September 16, 2011.
- "Tinder matchmaking is more like Warcraft than you might think – Kill Screen". Kill Screen. 2016-01-14. Archived from the original on 2017-08-19. Retrieved 2017-08-19.
- Screenplay for The Social Network, Sony Pictures Archived 2012-09-04 at the Wayback Machine, p. 16
Further reading
- Elo, Arpad (1978). The Rating of Chessplayers, Past and Present. Arco. ISBN 978-0-668-04721-0.
- Harkness, Kenneth (1967). Official Chess Handbook. McKay.