Quranic Arabic Corpus
The Quranic Arabic Corpus is an annotated linguistic resource consisting of 77,430 words of Quranic Arabic. The project aims to provide morphological and syntactic annotations for researchers wanting to study the language of the Quran.[1][2][3][4][5]
| Quranic Arabic Corpus | |
|---|---|
| Research center: | University of Leeds |
| Initial release: | November 2009 |
| Language: | Quranic Arabic, English |
| Annotation: | Syntax, morphology |
| Framework: | Dependency grammar |
| License: | GNU General Public License |
| Website: | http://corpus.quran.com/ |
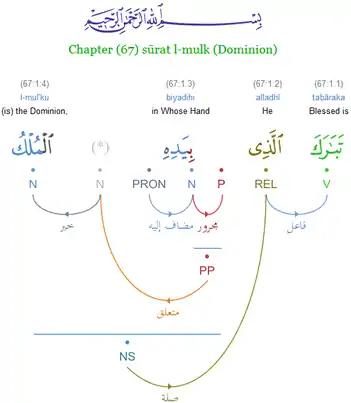
Functions
The grammatical analysis helps readers further in uncovering the detailed intended meanings of each verse and sentence. Each word of the Quran is tagged with its part-of-speech as well as multiple morphological features. Unlike other annotated Arabic corpora, the grammar framework adopted by the Quranic Corpus is the traditional Arabic grammar of i'rab (إﻋﺮﺍﺏ). The research project is led by Kais Dukes at the University of Leeds,[4] and is part of the Arabic language computing research group within the School of Computing, supervised by Eric Atwell.[6]
The annotated corpus includes:[1][7]
- A manually verified part-of-speech tagged Quranic Arabic corpus.
- An annotated treebank of Quranic Arabic.
- A novel visualization of traditional Arabic grammar through dependency graphs.
- Morphological search for the Quran.
- A machine-readable morphological lexicon of Quranic words into English.
- A part-of-speech concordance for Quranic Arabic organized by lemma.
- An online message board for community volunteer annotation.
Corpus annotation assigns a part-of-speech tag and morphological features to each word. For example, annotation involves deciding whether a word is a noun or a verb, and if it is inflected for masculine or feminine. The first stage of the project involved automatic part-of-speech tagging by applying Arabic language computing technology to the text. The annotation for each of the 77,430 words in the Quran was then reviewed in stages by two annotators, and improvements are still ongoing to further improve accuracy.
Linguistic research for the Quran that uses the annotated corpus includes training Hidden Markov model part-of-speech taggers for Arabic,[8] automatic categorization of Quranic chapters,[9] and prosodic analysis of the text.[10]
In addition, the project provides a word-by-word Quranic translation based on accepted English sources, instead of producing a new translation of the Qur'an.[4]
See also
References
- K. Dukes, E. Atwell and N. Habash (2011). Supervised Collaboration for Syntactic Annotation of Quranic Arabic. Language Resources and Evaluation Journal (LREJ). Special Issue on Collaboratively Constructed Language Resources.
- Supervised collaboration for syntactic annotation of Quranic Arabic at ResearchGate. Uploaded by Nizar Habash, Columbia University.
- K. Dukes and T. Buckwalter (2010). A Dependency Treebank of the Quran using Traditional Arabic Grammar. In Proceedings of the 7th International Conference on Informatics and Systems (INFOS). Cairo, Egypt.
- The Quranic Arabic Corpus Archived 2013-02-23 at the Wayback Machine at The Muslim Tribune. June 20, 2011.
- Eric Atwell, Claire Brierley, Kais Dukes, Majdi Sawalha and Abdul-Baquee Sharaf. An Artificial Intelligence approach to Arabic and Islamic content on the internet, pg. 2. Riyadh: King Saud University, 2011.
- Engineering. "Profile for Dr Eric Atwell - School of Computing - University of Leeds". www.comp.leeds.ac.uk.
- K. Dukes and N. Habash (2011). One-step Statistical Parsing of Hybrid Dependency-Constituency Syntactic Representations. International Conference on Parsing Technologies (IWPT). Dublin, Ireland.
- M. Albared, N. Omar and M. Ab Aziz (2011). Developing a Competitive HMM Arabic POS Tagger using Small Training Corpora. Intelligent Information and Database Systems. Springer Berlin, Heidelberg.
- A. M. Sharaf and E. Atwell (2011). Automatic Categorization of the Quranic Chapters. 7th International Computing Conference in Arabic (ICCA11). Riyadh, Saudi Arabia.
- C. Brierley, M. Sawalha and E. Atwell (2012). Boundary Annotated Qur'an Corpus for Arabic Phrase Break Prediction. Archived 2018-12-15 at the Wayback Machine IVACS Annual Symposium. Cambridge.
External links
| Overviews | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Alphabet | |||||||||
| Letters | |||||||||
| Notable varieties |
| ||||||||
| Pidgins/Creoles | |||||||||
| Academic | |||||||||
| Linguistics | |||||||||
| Technical |
| ||||||||
aSociolinguistically not Arabic
| |||||||||