Experimental uncertainty analysis
Experimental uncertainty analysis is a technique that analyses a derived quantity, based on the uncertainties in the experimentally measured quantities that are used in some form of mathematical relationship ("model") to calculate that derived quantity. The model used to convert the measurements into the derived quantity is usually based on fundamental principles of a science or engineering discipline.
The uncertainty has two components, namely, bias (related to accuracy) and the unavoidable random variation that occurs when making repeated measurements (related to precision). The measured quantities may have biases, and they certainly have random variation, so what needs to be addressed is how these are "propagated" into the uncertainty of the derived quantity. Uncertainty analysis is often called the "propagation of error."
It will be seen that this is a difficult and in fact sometimes intractable problem when handled in detail. Fortunately, approximate solutions are available that provide very useful results, and these approximations will be discussed in the context of a practical experimental example.
Introduction
Rather than providing a dry collection of equations, this article will focus on the experimental uncertainty analysis of an undergraduate physics lab experiment in which a pendulum is used to estimate the value of the local gravitational acceleration constant g. The relevant equation[1] for an idealized simple pendulum is, approximately,

where T is the period of oscillation (seconds), L is the length (meters), and θ is the initial angle. Since θ is the single time-dependent coordinate of this system, it might be better to use θ0 to denote the initial (starting) displacement angle, but it will be more convenient for notation to omit the subscript. Solving Eq(1) for the constant g,

This is the equation, or model, to be used for estimating g from observed data. There will be some slight bias introduced into the estimation of g by the fact that the term in brackets is only the first two terms of a series expansion, but in practical experiments this bias can be, and will be, ignored.
The procedure is to measure the pendulum length L and then make repeated measurements of the period T, each time starting the pendulum motion from the same initial displacement angle θ. The replicated measurements of T are averaged and then used in Eq(2) to obtain an estimate of g. Equation (2) is the means to get from the measured quantities L, T, and θ to the derived quantity g.
Note that an alternative approach would be to convert all the individual T measurements to estimates of g, using Eq(2), and then to average those g values to obtain the final result. This would not be practical without some form of mechanized computing capability (i.e., computer or calculator), since the amount of numerical calculation in evaluating Eq(2) for many T measurements would be tedious and prone to mistakes. Which of these approaches is to be preferred, in a statistical sense, will be addressed below.
Systematic error / bias / sensitivity analysis
Introduction
First, the possible sources of bias will be considered. There are three quantities that must be measured: (1) the length of the pendulum, from its suspension point to the center of mass of the “bob;” (2) the period of oscillation; (3) the initial displacement angle. The length is assumed to be fixed in this experiment, and it is to be measured once, although repeated measurements could be made, and the results averaged.
The initial displacement angle must be set for each replicate measurement of the period T, and this angle is assumed to be constant. Often the initial angle is kept small (less than about 10 degrees) so that the correction for this angle is considered to be negligible; i.e., the term in brackets in Eq(2) is taken to be unity. For the experiment studied here, however, this correction is of interest, so that a typical initial displacement value might range from 30 to 45 degrees.
Suppose that it was the case, unknown to the students, that the length measurements were too small by, say, 5 mm. This could be due to a faulty measurement device (e.g. a meter stick), or, more likely, a systematic error in the use of that device in measuring L. This could occur if the students forgot to measure to the center of mass of the bob, and instead consistently measured to the point where the string attached to it. Thus, this error is not random; it occurs each and every time the length is measured.
Next, the period of oscillation T could suffer from a systematic error if, for example, the students consistently miscounted the back-and-forth motions of the pendulum to obtain an integer number of cycles. (Often the experimental procedure calls for timing several cycles, e.g., five or ten, not just one.) Or perhaps the digital stopwatch they used had an electronic problem, and consistently read too large a value by, say, 0.02 seconds. There will of course also be random timing variations; that issue will be addressed later. Of concern here is a consistent, systematic, nonrandom error in the measurement of the period of oscillation of the pendulum.
Finally, the initial angle could be measured with a simple protractor. It is difficult to position and read the initial angle with high accuracy (or precision, for that matter; this measurement has poor reproducibility). Assume that the students consistently mis-position the protractor so that the angle reading is too small by, say, 5 degrees. Then all the initial angle measurements are biased by this amount.
Sensitivity errors
However, biases are not known while the experiment is in progress. If it was known, for example, that the length measurements were low by 5 mm, the students could either correct their measurement mistake or add the 5 mm to their data to remove the bias. Rather, what is of more value is to study the effects of nonrandom, systematic error possibilities before the experiment is conducted. This is a form of sensitivity analysis.
The idea is to estimate the difference, or fractional change, in the derived quantity, here g, given that the measured quantities are biased by some given amount. For example, if the initial angle was consistently low by 5 degrees, what effect would this have on the estimated g? If the length is consistently short by 5 mm, what is the change in the estimate of g? If the period measurements are consistently too long by 0.02 seconds, how much does the estimated g change? What happens to the estimate of g if these biases occur in various combinations?
One reason for exploring these questions is that the experimental design, in the sense of what equipment and procedure is to be used (not the statistical sense; that is addressed later), depends on the relative effect of systematic errors in the measured quantities. If a 5-degree bias in the initial angle would cause an unacceptable change in the estimate of g, then perhaps a more elaborate, and accurate, method needs to be devised for this measurement. On the other hand, if it can be shown, before the experiment is conducted, that this angle has a negligible effect on g, then using the protractor is acceptable.
Another motivation for this form of sensitivity analysis occurs after the experiment was conducted, and the data analysis shows a bias in the estimate of g. Examining the change in g that could result from biases in the several input parameters, that is, the measured quantities, can lead to insight into what caused the bias in the estimate of g. This analysis can help to isolate such problems as measurement mistakes, problems with apparatus, incorrect assumptions about the model, etc.
Direct (exact) calculation of bias
The most straightforward, not to say obvious, way to approach this would be to directly calculate the change using Eq(2) twice, once with theorized biased values and again with the true, unbiased, values for the parameters:

where the ΔL etc. represent the biases in the respective measured quantities. (The carat over g means the estimated value of g.) To make this more concrete, consider an idealized pendulum of length 0.5 meters, with an initial displacement angle of 30 degrees; from Eq(1) the period will then be 1.443 seconds. Suppose the biases are −5 mm, −5 degrees, and +0.02 seconds, for L, θ, and T respectively. Then, considering first only the length bias ΔL by itself,

and for this and the other measurement parameters T and θ the changes in g are recorded in Table 1.
It is common practice in sensitivity analysis to express the changes as fractions (or percentages). Then the exact fractional change in g is

The results of these calculations for the example pendulum system are summarized in Table 1.
Linearized approximation; introduction
Next, suppose that it is impractical to use the direct approach to find the dependence of the derived quantity (g) upon the input, measured parameters (L, T, θ). Is there an alternative method? From calculus, the concept of the total differential[2] is useful here:

where z is some function of several (p) variables x. The symbol ∂z / ∂x1 represents the "partial derivative" of the function z with respect to one of the several variables x that affect z. For the present purpose, finding this derivative consists of holding constant all variables other than the one with respect to which the partial is being found, and then finding the first derivative in the usual manner (which may, and often does, involve the chain rule). In functions that involve angles, as Eq(2) does, the angles must be measured in radians.
Eq(5) is a linear function that approximates, e.g., a curve in two dimensions (p=1) by a tangent line at a point on that curve, or in three dimensions (p=2) it approximates a surface by a tangent plane at a point on that surface. The idea is that the total change in z in the near vicinity of a specific point is found from Eq(5). In practice, finite differences are used, rather than the differentials, so that

and this works very well as long as the increments Δx are sufficiently small.[3] Even highly curved functions are nearly linear over a small enough region. The fractional change is then

An alternate, useful, way to write Eq(6) uses vector-matrix formalism:

In the application of these partial derivatives, note that they are functions that will be evaluated at a point, that is, all the parameters that appear in the partials will have numerical values. Thus the vector product in Eq(8), for example, will result in a single numerical value. For bias studies, the values used in the partials are the true parameter values, since we are approximating the function z in a small region near these true values.
Linearized approximation; absolute change example
Returning to the pendulum example and applying these equations, the absolute change in the estimate of g is

and now the task is to find the partial derivatives in this equation. It will considerably simplify the process to define

Rewriting Eq(2) and taking the partials,

Plugging these derivatives into Eq(9),

and then applying the same numerical values for the parameters and their biases as before, the results in Table 1 are obtained. The values are reasonably close to those found using Eq(3), but not exact, except for L. That is because the change in g is linear with L, which can be deduced from the fact that the partial with respect to (w.r.t.) L does not depend on L. Thus the linear "approximation" turns out to be exact for L. The partial w.r.t. θ is more complicated, and results from applying the chain rule to α. Also, in using Eq(10) in Eq(9) note that the angle measures, including Δθ, must be converted from degrees to radians.
Linearized approximation; fractional change example
The linearized-approximation fractional change in the estimate of g is, applying Eq(7) to the pendulum example,

which looks very complicated, but in practice this usually results in a simple relation for the fractional change. Thus,

which reduces to

This, except for the last term, is a remarkably simple result. Expanding the last term as a series in θ,

so the result for the linearized approximation for the fractional change in the estimate of g is

Recalling that angles are in radian measure, and that the value being used in the example is 30 degrees, this is about 0.524 radians; halved and squared as the coefficient of the fractional change in θ says, this coefficient is about 0.07. From Eq(12) it can then be readily concluded that the most-to-least influential parameters are T, L, θ. Another way of saying this is that the derived quantity g is more sensitive to, e.g., the measured quantity T than to L or θ. Substituting the example's numerical values, the results are indicated in Table 1, and agree reasonably well with those found using Eq(4).
The form of Eq(12) is usually the goal of a sensitivity analysis, since it is general, i.e., not tied to a specific set of parameter values, as was the case for the direct-calculation method of Eq(3) or (4), and it is clear basically by inspection which parameters have the most effect should they have systematic errors. For example, if the length measurement L was high by ten percent, then the estimate of g would also be high by ten percent. If the period T was underestimated by 20 percent, then the estimate of g would be overestimated by 40 percent (note the negative sign for the T term). If the initial angle θ was overestimated by ten percent, the estimate of g would be overestimated by about 0.7 percent.
This information is very valuable in post-experiment data analysis, to track down which measurements might have contributed to an observed bias in the overall result (estimate of g). The angle, for example, could quickly be eliminated as the only source of a bias in g of, say, 10 percent. The angle would need to be in error by some 140 percent, which is, one would hope, not physically plausible.
Results table
| Nominal | Bias | Ratio | Exact Δg | Linear Δg | Exact Δg/g | Linear Δg/g | |
| Length L | 0.5 m | − 0.005 m | 0.010 | − 0.098 | − 0.098 | − 0.010 | − 0.010 |
| Period T | 1.443 s | +0.02 s | 0.014 | − 0.266 | − 0.272 | − 0.027 | − 0.028 |
| Angle θ | 30 deg | − 5 deg | 0.17 | − 0.0968 | − 0.105 | − 0.01 | − 0.011 |
| All | −0.455 | − 0.475 | − 0.046 | − 0.049 | |||
| Eq(3) | Eq(11) | Eq(4) | Eq(12) |
Random error / precision
Introduction
Next, consider the fact that, as the students repeatedly measure the oscillation period of the pendulum, they will obtain different values for each measurement. These fluctuations are random- small differences in reaction time in operating the stopwatch, differences in estimating when the pendulum has reached its maximum angular travel, and so forth; all these things interact to produce variation in the measured quantity. This is not the bias that was discussed above, where there was assumed to be a 0.02 second discrepancy between the stopwatch reading and the actual period T. The bias is a fixed, constant value; random variation is just that – random, unpredictable.
Random variations are not predictable but they do tend to follow some rules, and those rules are usually summarized by a mathematical construct called a probability density function (PDF). This function, in turn, has a few parameters that are very useful in describing the variation of the observed measurements. Two such parameters are the mean and variance of the PDF. Essentially, the mean is the location of the PDF on the real number line, and the variance is a description of the scatter or dispersion or width of the PDF.
To illustrate, Figure 1 shows the so-called Normal PDF, which will be assumed to be the distribution of the observed time periods in the pendulum experiment. Ignoring all the biases in the measurements for the moment, then the mean of this PDF will be at the true value of T for the 0.5 meter idealized pendulum, which has an initial angle of 30 degrees, namely, from Eq(1), 1.443 seconds. In the figure there are 10000 simulated measurements in the histogram (which sorts the data into bins of small width, to show the distribution shape), and the Normal PDF is the solid line. The vertical line is the mean.
The interesting issue with random fluctuations is the variance. The positive square root of the variance is defined to be the standard deviation, and it is a measure of the width of the PDF; there are other measures, but the standard deviation, symbolized by the Greek letter σ "sigma," is by far the most commonly used. For this simulation, a sigma of 0.03 seconds for measurements of T was used; measurements of L and θ assumed negligible variability.
In the figure the widths of one-, two-, and three-sigma are indicated by the vertical dotted lines with the arrows. It is seen that a three-sigma width on either side of the mean contains nearly all of the data for the Normal PDF. The range of time values observed is from about 1.35 to 1.55 seconds, but most of these time measurements fall in an interval narrower than that.
Derived-quantity PDF
Figure 1 shows the measurement results for many repeated measurements of the pendulum period T. Suppose that these measurements were used, one at a time, in Eq(2) to estimate g. What would be the PDF of those g estimates? Having that PDF, what are the mean and variance of the g estimates? This is not a simple question to answer, so a simulation will be the best way to see what happens. In Figure 2 there are again 10000 measurements of T, which are then used in Eq(2) to estimate g, and those 10000 estimates are placed in the histogram. The mean (vertical black line) agrees closely[4] with the known value for g of 9.8 m/s2.
It is sometimes possible to derive the actual PDF of the transformed data. In the pendulum example the time measurements T are, in Eq(2), squared and divided into some factors that for now can be considered constants. Using rules for the transformation of random variables[5] it can be shown that if the T measurements are Normally distributed, as in Figure 1, then the estimates of g follow another (complicated) distribution that can be derived analytically. That g-PDF is plotted with the histogram (black line) and the agreement with the data is very good. Also shown in Figure 2 is a g-PDF curve (red dashed line) for the biased values of T that were used in the previous discussion of bias. Thus the mean of the biased-T g-PDF is at 9.800 − 0.266 m/s2 (see Table 1).
Consider again, as was done in the bias discussion above, a function

where f need not be, and often is not, linear, and the x are random variables which in general need not be normally distributed, and which in general may be mutually correlated. In analyzing the results of an experiment, the mean and variance of the derived quantity z, which will be a random variable, are of interest. These are defined as the expected values

i.e., the first moment of the PDF about the origin, and the second moment of the PDF about the mean of the derived random variable z. These expected values are found using an integral, for the continuous variables being considered here. However, to evaluate these integrals a functional form is needed for the PDF of the derived quantity z. It has been noted that[6]
- The exact calculation of [variances] of nonlinear functions of variables that are subject to error is generally a problem of great mathematical complexity. In fact, a substantial portion of mathematical statistics is concerned with the general problem of deriving the complete frequency distribution [PDF] of such functions, from which the [variance] can then be derived.
To illustrate, a simple example of this process is to find the mean and variance of the derived quantity z = x2 where the measured quantity x is Normally distributed with mean μ and variance σ2. The derived quantity z will have some new PDF, that can (sometimes) be found using the rules of probability calculus.[7] In this case, it can be shown using these rules that the PDF of z will be

Integrating this from zero to positive infinity returns unity, which verifies that this is a PDF. Next, the mean and variance of this PDF are needed, to characterize the derived quantity z. The mean and variance (actually, mean squared error, a distinction that will not be pursued here) are found from the integrals

if these functions are integrable at all. As it happens in this case, analytical results are possible,[8] and it is found that

These results are exact. Note that the mean (expected value) of z is not what would logically be expected, i.e., simply the square of the mean of x. Thus, even when using arguably the simplest nonlinear function, the square of a random variable, the process of finding the mean and variance of the derived quantity is difficult, and for more complicated functions it is safe to say that this process is not practical for experimental data analysis.
As is good practice in these studies, the results above can be checked with a simulation. Figure 3 shows a histogram of 10000 samples of z, with the PDF given above also graphed; the agreement is excellent. In this simulation the x data had a mean of 10 and a standard deviation of 2. Thus the naive expected value for z would of course be 100. The "biased mean" vertical line is found using the expression above for μz, and it agrees well with the observed mean (i.e., calculated from the data; dashed vertical line), and the biased mean is above the "expected" value of 100. The dashed curve shown in this figure is a Normal PDF that will be addressed later.
Linearized approximations for derived-quantity mean and variance
If, as is usually the case, the PDF of the derived quantity has not been found, and even if the PDFs of the measured quantities are not known, it turns out that it is still possible to estimate the mean and variance (and, thus, the standard deviation) of the derived quantity. This so-called "differential method"[9] will be described next. (For a derivation of Eq(13) and (14), see this section, below.)
As is usual in applied mathematics, one approach for avoiding complexity is to approximate a function with another, simpler, function, and often this is done using a low-order Taylor series expansion. It can be shown[10] that, if the function z is replaced with a first-order expansion about a point defined by the mean values of each of the p variables x, the variance of the linearized function is approximated by

where σij represents the covariance of two variables xi and xj. The double sum is taken over all combinations of i and j, with the understanding that the covariance of a variable with itself is the variance of that variable, that is, σii = σi2. Also, the covariances are symmetric, so that σij = σji . Again, as was the case with the bias calculations, the partial derivatives are evaluated at a specific point, in this case, at the mean (average) value, or other best estimate, of each of the independent variables. Note that if f is linear then, and only then, Eq(13) is exact.
The expected value (mean) of the derived PDF can be estimated, for the case where z is a function of one or two measured variables, using[11]

where the partials are evaluated at the mean of the respective measurement variable. (For more than two input variables this equation is extended, including the various mixed partials.)
Returning to the simple example case of z = x2 the mean is estimated by

which is the same as the exact result, in this particular case. For the variance (actually MSe),

which differs only by the absence of the last term that was in the exact result; since σ should be small compared to μ, this should not be a major issue.
In Figure 3 there is shown is a Normal PDF (dashed lines) with mean and variance from these approximations. The Normal PDF does not describe this derived data particularly well, especially at the low end. Substituting the known mean (10) and variance (4) of the x values in this simulation, or in the expressions above, it is seen that the approximate (1600) and exact (1632) variances only differ slightly (2%).
Matrix format of variance approximation
A more elegant way of writing the so-called "propagation of error" variance equation is to use matrices.[12] First define a vector of partial derivatives, as was used in Eq(8) above:

where superscript T denotes the matrix transpose; then define the covariance matrix

The propagation of error approximation then can be written concisely as the quadratic form

If the correlations amongst the p variables are all zero, as is frequently assumed, then the covariance matrix C becomes diagonal, with the individual variances along the main diagonal. To stress the point again, the partials in the vector γ are all evaluated at a specific point, so that Eq(15) returns a single numerical result.
It will be useful to write out in detail the expression for the variance using Eq(13) or (15) for the case p = 2. This leads to

which, since the last two terms above are the same thing, is

Linearized approximation: simple example for variance
Consider a relatively simple algebraic example, before returning to the more involved pendulum example. Let

so that

This expression could remain in this form, but it is common practice to divide through by z2 since this will cause many of the factors to cancel, and will also produce in a more useful result:

which reduces to

Since the standard deviation of z is usually of interest, its estimate is

where the use of the means (averages) of the variables is indicated by the overbars, and the carats indicate that the component (co)variances must also be estimated, unless there is some solid a priori knowledge of them. Generally this is not the case, so that the estimators

are frequently used,[13] based on n observations (measurements).
Linearized approximation: pendulum example, mean
For simplicity, consider only the measured time as a random variable, so that the derived quantity, the estimate of g, amounts to

where k collects the factors in Eq(2) that for the moment are constants. Again applying the rules for probability calculus, a PDF can be derived for the estimates of g (this PDF was graphed in Figure 2). In this case, unlike the example used previously, the mean and variance could not be found analytically. Thus there is no choice but to use the linearized approximations. For the mean, using Eq(14), with the simplified equation for the estimate of g,

Then the expected value of the estimated g will be

where, if the pendulum period times T are unbiased, the first term is 9.80 m/s2. This result says that the mean of the estimated g values is biased high. This will be checked with a simulation, below.
Linearized approximation: pendulum example, variance
Next, to find an estimate of the variance for the pendulum example, since the partial derivatives have already been found in Eq(10), all the variables will return to the problem. The partials go into the vector γ. Following the usual practice, especially if there is no evidence to the contrary, it is assumed that the covariances are all zero, so that C is diagonal.[14] Then

The same result is obtained using Eq(13). It must be stressed that these "sigmas" are the variances that describe the random variation in the measurements of L, T, and θ; they are not to be confused with the biases used previously. The variances (or standard deviations) and the biases are not the same thing.
To illustrate this calculation, consider the simulation results from Figure 2. Here, only the time measurement was presumed to have random variation, and the standard deviation used for it was 0.03 seconds. Thus, using Eq(17),

and, using the numerical values assigned before for this example,

which compares favorably to the observed variance of 0.171, as calculated by the simulation program. (Estimated variances have a considerable amount of variability and these values would not be expected to agree exactly.) For the mean value, Eq(16) yields a bias of only about 0.01 m/s2, which is not visible in Figure 2.
To make clearer what happens as the random error in a measurement variable increases, consider Figure 4, where the standard deviation of the time measurements is increased to 0.15 s, or about ten percent. The PDF for the estimated g values is also graphed, as it was in Figure 2; note that the PDF for the larger-time-variation case is skewed, and now the biased mean is clearly seen. The approximated (biased) mean and the mean observed directly from the data agree well. The dashed curve is a Normal PDF with mean and variance from the approximations; it does not represent the data particularly well.
Linearized approximation: pendulum example, relative error (precision)
Rather than the variance, often a more useful measure is the standard deviation σ, and when this is divided by the mean μ we have a quantity called the relative error, or coefficient of variation. This is a measure of precision:

For the pendulum example, this gives a precision of slightly more than 4 percent. As with the bias, it is useful to relate the relative error in the derived quantity to the relative error in the measured quantities. Divide Eq(17) by the square of g:

and use results obtained from the fractional change bias calculations to give (compare to Eq(12)):

Taking the square root then gives the RE:

In the example case this gives

which agrees with the RE obtained previously. This method, using the relative errors in the component (measured) quantities, is simpler, once the mathematics has been done to obtain a relation like Eq(17). Recall that the angles used in Eq(17) must be expressed in radians.
If, as is often the case, the standard deviation of the estimated g should be needed by itself, this is readily obtained by a simple rearrangement of Eq(18). This standard deviation is usually quoted along with the "point estimate" of the mean value: for the simulation this would be 9.81 ± 0.41 m/s2. What is to be inferred from intervals quoted in this manner needs to be considered very carefully. Discussion of this important topic is beyond the scope of this article, but the issue is addressed in some detail in the book by Natrella.[15]
Linearized approximation: pendulum example, simulation check
It is good practice to check uncertainty calculations using simulation. These calculations can be very complicated and mistakes are easily made. For example, to see if the relative error for just the angle measurement was correct, a simulation was created to sample the angles from a Normal PDF with mean 30 degrees and standard deviation 5 degrees; both are converted to radians in the simulation. The relative error in the angle is then about 17 percent. From Eq(18) the relative error in the estimated g is, holding the other measurements at negligible variation,

The simulation shows the observed relative error in g to be about 0.011, which demonstrates that the angle uncertainty calculations are correct. Thus, as was seen with the bias calculations, a relatively large random variation in the initial angle (17 percent) only causes about a one percent relative error in the estimate of g.
Figure 5 shows the histogram for these g estimates. Since the relative error in the angle was relatively large, the PDF of the g estimates is skewed (not Normal, not symmetric), and the mean is slightly biased. In this case the PDF is not known, but the mean can still be estimated, using Eq(14). The second partial for the angle portion of Eq(2), keeping the other variables as constants, collected in k, can be shown to be[8]

so that the expected value is

and the dotted vertical line, resulting from this equation, agrees with the observed mean.
Selection of data analysis method
Introduction
In the introduction it was mentioned that there are two ways to analyze a set of measurements of the period of oscillation T of the pendulum:
- Method 1: average the n measurements of T, use that mean in Eq(2) to obtain the final g estimate;
- Method 2: use all the n individual measurements of T in Eq(2), one at a time, to obtain n estimates of g, average those to obtain the final g estimate.
It would be reasonable to think that these would amount to the same thing, and that there is no reason to prefer one method over the other. However, Method 2 results in a bias that is not removed by increasing the sample size. Method 1 is also biased, but that bias decreases with sample size. This bias, in both cases, is not particularly large, and it should not be confused with the bias that was discussed in the first section. What might be termed "Type I bias" results from a systematic error in the measurement process; "Type II bias" results from the transformation of a measurement random variable via a nonlinear model; here, Eq(2).
Type II bias is characterized by the terms after the first in Eq(14). As was calculated for the simulation in Figure 4, the bias in the estimated g for a reasonable variability in the measured times (0.03 s) is obtained from Eq(16) and was only about 0.01 m/s2. Rearranging the bias portion (second term) of Eq(16), and using β for the bias,

using the example pendulum parameters. From this it is seen that the bias varies as the square of the relative error in the period T; for a larger relative error, about ten percent, the bias is about 0.32 m/s2, which is of more concern.
Sample size
What is missing here, and has been deliberately avoided in all the prior material, is the effect of the sample size on these calculations. The number of measurements n has not appeared in any equation so far. Implicitly, all the analysis has been for the Method 2 approach, taking one measurement (e.g., of T) at a time, and processing it through Eq(2) to obtain an estimate of g.
To use the various equations developed above, values are needed for the mean and variance of the several parameters that appear in those equations. In practical experiments, these values will be estimated from observed data, i.e., measurements. These measurements are averaged to produce the estimated mean values to use in the equations, e.g., for evaluation of the partial derivatives. Thus, the variance of interest is the variance of the mean, not of the population, and so, for example,

which reflects the fact that, as the number of measurements of T increases, the variance of the mean value of T would decrease. There is some inherent variability in the T measurements, and that is assumed to remain constant, but the variability of the average T will decrease as n increases. Assuming no covariance amongst the parameters (measurements), the expansion of Eq(13) or (15) can be re-stated as

where the subscript on n reflects the fact that different numbers of measurements might be done on the several variables (e.g., 3 for L, 10 for T, 5 for θ, etc.)
This dependence of the overall variance on the number of measurements implies that a component of statistical experimental design would be to define these sample sizes to keep the overall relative error (precision) within some reasonable bounds. Having an estimate of the variability of the individual measurements, perhaps from a pilot study, then it should be possible to estimate what sample sizes (number of replicates for measuring, e.g., T in the pendulum example) would be required.
Returning to the Type II bias in the Method 2 approach, Eq(19) can now be re-stated more accurately as

where s is the estimated standard deviation of the nT T measurements. In Method 2, each individual T measurement is used to estimate g, so that nT = 1 for this approach. On the other hand, for Method 1, the T measurements are first averaged before using Eq(2), so that nT is greater than one. This means that

which says that the Type II bias of Method 2 does not decrease with sample size; it is constant. The variance of the estimate of g, on the other hand, is in both cases

because in both methods nT measurements are used to form the average g estimate.[16] Thus the variance decreases with sample size for both methods.
These effects are illustrated in Figures 6 and 7. In Figure 6 is a series PDFs of the Method 2 estimated g for a comparatively large relative error in the T measurements, with varying sample sizes. The relative error in T is larger than might be reasonable so that the effect of the bias can be more clearly seen. In the figure the dots show the mean; the bias is evident, and it does not change with n. The variance, or width of the PDF, does become smaller with increasing n, and the PDF also becomes more symmetric. In Figure 7 are the PDFs for Method 1, and it is seen that the means converge toward the correct g value of 9.8 m/s2 as the number of measurements increases, and the variance also decreases.
From this it is concluded that Method 1 is the preferred approach to processing the pendulum or other data.
Discussion
Systematic errors in the measurement of experimental quantities leads to bias in the derived quantity, the magnitude of which is calculated using Eq(6) or Eq(7). However, there is also a more subtle form of bias that can occur even if the input, measured, quantities are unbiased; all terms after the first in Eq(14) represent this bias. It arises from the nonlinear transformations of random variables that often are applied in obtaining the derived quantity. The transformation bias is influenced by the relative size of the variance of the measured quantity compared to its mean. The larger this ratio is, the more skew the derived-quantity PDF may be, and the more bias there may be.
The Taylor-series approximations provide a very useful way to estimate both bias and variability for cases where the PDF of the derived quantity is unknown or intractable. The mean can be estimated using Eq(14) and the variance using Eq(13) or Eq(15). There are situations, however, in which this first-order Taylor series approximation approach is not appropriate – notably if any of the component variables can vanish. Then, a second-order expansion would be useful; see Meyer[17] for the relevant expressions.
The sample size is an important consideration in experimental design. To illustrate the effect of the sample size, Eq(18) can be re-written as

where the average values (bars) and estimated standard deviations s are shown, as are the respective sample sizes. In principle, by using very large n the RE of the estimated g could be driven down to an arbitrarily small value. However, there are often constraints or practical reasons for relatively small numbers of measurements.
Details concerning the difference between the variance and the mean-squared error (MSe) have been skipped. Essentially, the MSe estimates the variability about the true (but unknown) mean of a distribution. This variability is composed of (1) the variability about the actual, observed mean, and (2) a term that accounts for how far that observed mean is from the true mean. Thus

where β is the bias (distance). This is a statistical application of the parallel-axis theorem from mechanics.[18]
In summary, the linearized approximation for the expected value (mean) and variance of a nonlinearly-transformed random variable is very useful, and much simpler to apply than the more complicated process of finding its PDF and then its first two moments. In many cases, the latter approach is not feasible at all. The mathematics of the linearized approximation is not trivial, and it can be avoided by using results that are collected for often-encountered functions of random variables.[19]
Derivation of propagation of error equations
Outline of procedure
- Given a function z of several random variables x, the mean and variance of z are sought.
- The direct approach is to find the PDF of z and then find its mean and variance:

3. Finding the PDF is nontrivial, and may not even be possible in some cases, and is certainly not a practical method for ordinary data analysis purposes. Even if the PDF can be found, finding the moments (above) can be difficult.
4. The solution is to expand the function z in a second-order Taylor series; the expansion is done around the mean values of the several variables x. (Usually the expansion is done to first order; the second-order terms are needed to find the bias in the mean. Those second-order terms are usually dropped when finding the variance; see below).
5. With the expansion in hand, find the expected value. This will give an approximation for the mean of z, and will include terms that represent any bias. In effect the expansion “isolates” the random variables x so that their expectations can be found.
6. Having the expression for the expected value of z, which will involve partial derivatives and the means and variances of the random variables x, set up the expression for the expectation of the variance:

that is, find ( z − E[z] ) and do the necessary algebra to collect terms and simplify.
7. For most purposes, it is sufficient to keep only the first-order terms; square that quantity.
8. Find the expected value of that result. This will be the approximation for the variance of z.
Multivariate Taylor series
This is the fundamental relation for the second-order expansion used in the approximations:[20]

Example expansion: p = 2
To reduce notational clutter, the evaluation-at-the-mean symbols are not shown:

which reduces to

Approximation for the mean of z
Using the previous result, take expected values:

and similarly for x2. The partials come outside the expectations since, evaluated at the respective mean values, they will be constants. The zero result above follows since the expected value of a sum or difference is the sum or difference of the expected values, so that, for any i

Continuing,

and similarly for x2. Finally,

where σ1,2 is the covariance of x1and x2. (This is often taken to be zero, correctly or not.) Then the expression for the approximation for the mean of the derived random variable z is

where all terms after the first represent the bias in z. This equation is needed to find the variance approximation, but it is useful on its own; remarkably, it does not appear in most texts on data analysis.
Approximation for the variance of z
From the definition of variance, the next step would be to subtract the expected value, just found, from the expansion of z found previously. This leads to

Clearly, consideration of the second-order terms is going to lead to a very complicated and impractical result (although, if the first-order terms vanish, the use of all the terms above will be needed; see Meyer, p. 46). Hence, take only the linear terms (in the curly brackets), and square:

The final step is to take the expected value of this

which leads to the well-known result

and this is generalized for p variables as the usual "propagation of error" formula

with the understanding that the covariance of a variable with itself is its variance. It is essential to recognize that all of these partial derivatives are to be evaluated at the mean of the respective x variables, and that the corresponding variances are variances of those means. To reinforce this,


Table of selected uncertainty equations
Univariate case 1

NOTES: r can be integer or fractional, positive or negative (or zero). If r is negative, ensure that the range of x does not include zero. If r is fractional with an even divisor, ensure that x is not negative. "n" is the sample size. These expressions are based on "Method 1" data analysis, where the observed values of x are averaged before the transformation (i.e., in this case, raising to a power and multiplying by a constant) is applied.
Type I bias, absolute.........................................................................Eq(1.1)

Type I bias, relative (fractional).........................................................Eq(1.2)

Mean (expected value).......................................................................Eq(1.3)

Type II bias, absolute........................................................................Eq(1.4)

Type II bias, fractional.......................................................................Eq(1.5)

Variance, absolute...........................................................................Eq(1.6)

Standard deviation, fractional...........................................................Eq(1.7)

Comments:
- (1) The Type I bias equations 1.1 and 1.2 are not affected by the sample size n.
- (2) Eq(1.4) is a re-arrangement of the second term in Eq(1.3).
- (3) The Type II bias and the variance and standard deviation all decrease with increasing sample size, and they also decrease, for a given sample size, when x's standard deviation σ becomes small compared to its mean μ.
Univariate case 2

NOTES: b can be positive or negative. “n” is the sample size. Be aware that the effectiveness of these approximations is very strongly dependent on the relative sizes of μ, σ, and b.
Type I bias, absolute.........................................................................Eq(2.1)

Type I bias, relative (fractional).........................................................Eq(2.2)

Mean (expected value).......................................................................Eq(2.3)

Type II bias, absolute........................................................................Eq(2.4)

Type II bias, fractional.......................................................................Eq(2.5)

Variance, absolute...........................................................................Eq(2.6)

Standard deviation, fractional...........................................................Eq(2.7)

Univariate case 3

NOTES: b and x must be positive. “n” is the sample size. Be aware that the effectiveness of these approximations is very strongly dependent on the relative sizes of μ, σ, and b.
Type I bias, absolute.........................................................................Eq(3.1)

Type I bias, relative (fractional).........................................................Eq(3.2)

Mean (expected value).......................................................................Eq(3.3)

Type II bias, absolute........................................................................Eq(3.4)

Type II bias, fractional.......................................................................Eq(3.5)

Variance, absolute...........................................................................Eq(3.6)

Standard deviation, fractional...........................................................Eq(3.7)

Multivariate case 1

NOTES: BVN is bivariate Normal PDF. “n” is the sample size.
Type I bias, absolute.........................................................................Eq(4.1)

Type I bias, relative (fractional).........................................................Eq(4.2)

Mean (expected value).......................................................................Eq(4.3)

Type II bias, absolute........................................................................Eq(4.4)

Type II bias, fractional.......................................................................Eq(4.5)

Variance, absolute...........................................................................Eq(4.6)

Standard deviation, fractional...........................................................Eq(4.7)
This is complicated, no point, does not simplify to anything useful; use (4.6)
Multivariate case 2

Type I bias, absolute.........................................................................Eq(5.1)

Type I bias, relative (fractional).........................................................Eq(5.2)

Mean (expected value).......................................................................Eq(5.3)

Type II bias, absolute........................................................................Eq(5.4)

Type II bias, fractional.......................................................................Eq(5.5)

Variance, absolute...........................................................................Eq(5.6)

Standard deviation, fractional...........................................................Eq(5.7)

Figure gallery
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4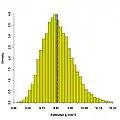 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7
See also
References
- The exact period requires an elliptic integral; see, e.g., Tenenbaum; Pollard (1985). Ordinary Differential Equations (Reprint ed.). New York: Dover. p. 333. ISBN 0486649407. This approximation also appears in many calculus-based undergraduate physics textbooks.
- E.g., Thomas and Finney, Calculus, 9th Ed., Addison-Wesley (1996), p.940; Stewart, Multivariable Calculus, 3rd Ed., Brooks/Cole (1995), p.790
- Thomas, p. 937
- In fact, there is a small bias that is negligible for reasonably small values of the standard deviation of the time measurements.
- Meyer, S. L., Data Analysis for Scientists and Engineers, Wiley (1975), p. 148
- Mandel, J., The Statistical Analysis of Experimental Data, Dover (1984), p. 73
- Meyer, pp. 147–151
- Using Mathematica.
- Deming, W. E., Some Theory of Sampling, Wiley (1950), p.130. See this reference for an interesting derivation of this material.
- Mandel, p. 74. Deming, p. 130. Meyer, p. 40. Bevington and Robinson, Data Reduction and Error Analysis for the Physical Sciences, 2nd Ed. McGraw-Hill (1992), p. 43. Bowker and Lieberman, Engineering Statistics, 2nd Ed. Prentice-Hall (1972), p. 94. Rohatgi, Statistical Inference, Dover (2003), pp. 267–270 is highly relevant, including material on finding the expected value (mean) in addition to the variance.
- Rohatgi, p.268
- Wolter, K.M., Introduction to Variance Estimation, Springer (1985), pp. 225–228.
- These estimates do have some bias, especially for small sample sizes, which can be corrected. See, e.g., Rohatgi, pp. 524–525.
- This assumption should be carefully evaluated for real-world problems. Incorrectly ignoring covariances can adversely affect conclusions.
- Natrella, M. G., Experimental Statistics, NBS Handbook 91 (1963) Ch. 23. This book has been reprinted and is currently available.
- For a more detailed discussion of this topic, and why n affects the variance and not the mean, see Rohatgi, pp. 267–270
- Meyer, pp. 45–46.
- See, e.g., Deming, p. 129–130 or Lindgren, B. W., Statistical Theory, 3rd Ed., Macmillan (1976), p. 254.
- E.g., Meyer, pp. 40–45; Bevington, pp. 43–48
- Korn and Korn,Mathematical Handbook for Scientists and Engineers, Dover (2000 reprint), p. 134.
External links
- A Java interactive graphic that illustrates the Method 1 vs. Method 2 processing biases.
