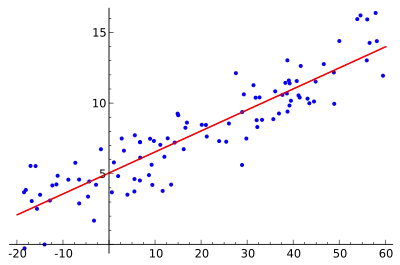
Simple linear regression
In statistics, simple linear regression is a linear regression model with a single explanatory variable.[1][2][3][4][5] That is, it concerns two-dimensional sample points with one independent variable and one dependent variable (conventionally, the x and y coordinates in a Cartesian coordinate system) and finds a linear function (a non-vertical straight line) that, as accurately as possible, predicts the dependent variable values as a function of the independent variable. The adjective simple refers to the fact that the outcome variable is related to a single predictor.
| Part of a series on |
| Regression analysis |
|---|
 |
| Models |
| Estimation |
| Background |
|
It is common to make the additional stipulation that the ordinary least squares (OLS) method should be used: the accuracy of each predicted value is measured by its squared residual (vertical distance between the point of the data set and the fitted line), and the goal is to make the sum of these squared deviations as small as possible. Other regression methods that can be used in place of ordinary least squares include least absolute deviations (minimizing the sum of absolute values of residuals) and the Theil–Sen estimator (which chooses a line whose slope is the median of the slopes determined by pairs of sample points). Deming regression (total least squares) also finds a line that fits a set of two-dimensional sample points, but (unlike ordinary least squares, least absolute deviations, and median slope regression) it is not really an instance of simple linear regression, because it does not separate the coordinates into one dependent and one independent variable and could potentially return a vertical line as its fit.
The remainder of the article assumes an ordinary least squares regression. In this case, the slope of the fitted line is equal to the correlation between y and x corrected by the ratio of standard deviations of these variables. The intercept of the fitted line is such that the line passes through the center of mass (x, y) of the data points.
Fitting the regression line
Consider the model function

which describes a line with slope β and y-intercept α. In general such a relationship may not hold exactly for the largely unobserved population of values of the independent and dependent variables; we call the unobserved deviations from the above equation the errors. Suppose we observe n data pairs and call them {(xi, yi), i = 1, ..., n}. We can describe the underlying relationship between yi and xi involving this error term εi by

This relationship between the true (but unobserved) underlying parameters α and β and the data points is called a linear regression model.
The goal is to find estimated values and for the parameters α and β which would provide the "best" fit in some sense for the data points. As mentioned in the introduction, in this article the "best" fit will be understood as in the least-squares approach: a line that minimizes the sum of squared residuals (differences between actual and predicted values of the dependent variable y), each of which is given by, for any candidate parameter values and ,






In other words, and solve the following minimization problem:

By expanding to get a quadratic expression in and we can derive values of and that minimize the objective function Q (these minimizing values are denoted and ):[6]


Here we have introduced
- and as the average of the xi and yi, respectively
- rxy as the sample correlation coefficient between x and y
- sx and sy as the uncorrected sample standard deviations of x and y
- and as the sample variance and sample covariance, respectively




Substituting the above expressions for and into

yields

This shows that rxy is the slope of the regression line of the standardized data points (and that this line passes through the origin).
Generalizing the notation, we can write a horizontal bar over an expression to indicate the average value of that expression over the set of samples. For example:

This notation allows us a concise formula for rxy:

The coefficient of determination ("R squared") is equal to when the model is linear with a single independent variable. See sample correlation coefficient for additional details.

Intuitive explanation
By multiplying all members of the summation in the numerator by : (thereby not changing it):


We can see that the slope (tangent of angle) of the regression line is the weighted average of that is the slope (tangent of angle) of the line that connects the i-th point to the average of all points, weighted by because the further the point is the more "important" it is, since small errors in its position will affect the slope connecting it to the center point less.



Given with the angle the line makes with the positive x axis, we have



Simple linear regression without the intercept term (single regressor)
Sometimes it is appropriate to force the regression line to pass through the origin, because x and y are assumed to be proportional. For the model without the intercept term, y = βx, the OLS estimator for β simplifies to

Substituting (x − h, y − k) in place of (x, y) gives the regression through (h, k):

where Cov and Var refer to the covariance and variance of the sample data (uncorrected for bias).
The last form above demonstrates how moving the line away from the center of mass of the data points affects the slope.
Numerical properties
- The regression line goes through the center of mass point, , if the model includes an intercept term (i.e., not forced through the origin).
- The sum of the residuals is zero if the model includes an intercept term:
- The residuals and x values are uncorrelated (whether or not there is an intercept term in the model), meaning:



Model-based properties
Description of the statistical properties of estimators from the simple linear regression estimates requires the use of a statistical model. The following is based on assuming the validity of a model under which the estimates are optimal. It is also possible to evaluate the properties under other assumptions, such as inhomogeneity, but this is discussed elsewhere.
Unbiasedness
The estimators and are unbiased.
To formalize this assertion we must define a framework in which these estimators are random variables. We consider the residuals εi as random variables drawn independently from some distribution with mean zero. In other words, for each value of x, the corresponding value of y is generated as a mean response α + βx plus an additional random variable ε called the error term, equal to zero on average. Under such interpretation, the least-squares estimators and will themselves be random variables whose means will equal the "true values" α and β. This is the definition of an unbiased estimator.
Confidence intervals
The formulas given in the previous section allow one to calculate the point estimates of α and β — that is, the coefficients of the regression line for the given set of data. However, those formulas don't tell us how precise the estimates are, i.e., how much the estimators and vary from sample to sample for the specified sample size. Confidence intervals were devised to give a plausible set of values to the estimates one might have if one repeated the experiment a very large number of times.
The standard method of constructing confidence intervals for linear regression coefficients relies on the normality assumption, which is justified if either:
- the errors in the regression are normally distributed (the so-called classic regression assumption), or
- the number of observations n is sufficiently large, in which case the estimator is approximately normally distributed.
The latter case is justified by the central limit theorem.
Normality assumption
Under the first assumption above, that of the normality of the error terms, the estimator of the slope coefficient will itself be normally distributed with mean β and variance where σ2 is the variance of the error terms (see Proofs involving ordinary least squares). At the same time the sum of squared residuals Q is distributed proportionally to χ2 with n − 2 degrees of freedom, and independently from . This allows us to construct a t-value


where

is the standard error of the estimator .
This t-value has a Student's t-distribution with n − 2 degrees of freedom. Using it we can construct a confidence interval for β:

at confidence level (1 − γ), where is the quantile of the tn−2 distribution. For example, if γ = 0.05 then the confidence level is 95%.


Similarly, the confidence interval for the intercept coefficient α is given by

at confidence level (1 − γ), where

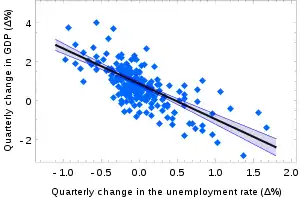
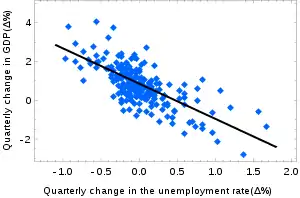
The confidence intervals for α and β give us the general idea where these regression coefficients are most likely to be. For example, in the Okun's law regression shown here the point estimates are

The 95% confidence intervals for these estimates are

In order to represent this information graphically, in the form of the confidence bands around the regression line, one has to proceed carefully and account for the joint distribution of the estimators. It can be shown[7] that at confidence level (1 − γ) the confidence band has hyperbolic form given by the equation

Asymptotic assumption
The alternative second assumption states that when the number of points in the dataset is "large enough", the law of large numbers and the central limit theorem become applicable, and then the distribution of the estimators is approximately normal. Under this assumption all formulas derived in the previous section remain valid, with the only exception that the quantile t*n−2 of Student's t distribution is replaced with the quantile q* of the standard normal distribution. Occasionally the fraction 1/n−2 is replaced with 1/n. When n is large such a change does not alter the results appreciably.
Numerical example
This data set gives average masses for women as a function of their height in a sample of American women of age 30–39. Although the OLS article argues that it would be more appropriate to run a quadratic regression for this data, the simple linear regression model is applied here instead.
Height (m), xi 1.47 1.50 1.52 1.55 1.57 1.60 1.63 1.65 1.68 1.70 1.73 1.75 1.78 1.80 1.83 Mass (kg), yi 52.21 53.12 54.48 55.84 57.20 58.57 59.93 61.29 63.11 64.47 66.28 68.10 69.92 72.19 74.46
| 1 | 1.47 | 52.21 | 2.1609 | 76.7487 | 2725.8841 |
| 2 | 1.50 | 53.12 | 2.2500 | 79.6800 | 2821.7344 |
| 3 | 1.52 | 54.48 | 2.3104 | 82.8096 | 2968.0704 |
| 4 | 1.55 | 55.84 | 2.4025 | 86.5520 | 3118.1056 |
| 5 | 1.57 | 57.20 | 2.4649 | 89.8040 | 3271.8400 |
| 6 | 1.60 | 58.57 | 2.5600 | 93.7120 | 3430.4449 |
| 7 | 1.63 | 59.93 | 2.6569 | 97.6859 | 3591.6049 |
| 8 | 1.65 | 61.29 | 2.7225 | 101.1285 | 3756.4641 |
| 9 | 1.68 | 63.11 | 2.8224 | 106.0248 | 3982.8721 |
| 10 | 1.70 | 64.47 | 2.8900 | 109.5990 | 4156.3809 |
| 11 | 1.73 | 66.28 | 2.9929 | 114.6644 | 4393.0384 |
| 12 | 1.75 | 68.10 | 3.0625 | 119.1750 | 4637.6100 |
| 13 | 1.78 | 69.92 | 3.1684 | 124.4576 | 4888.8064 |
| 14 | 1.80 | 72.19 | 3.2400 | 129.9420 | 5211.3961 |
| 15 | 1.83 | 74.46 | 3.3489 | 136.2618 | 5544.2916 |
| 24.76 | 931.17 | 41.0532 | 1548.2453 | 58498.5439 |







There are n = 15 points in this data set. Hand calculations would be started by finding the following five sums:

These quantities would be used to calculate the estimates of the regression coefficients, and their standard errors.

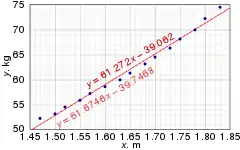
The 0.975 quantile of Student's t-distribution with 13 degrees of freedom is t*13 = 2.1604, and thus the 95% confidence intervals for α and β are

The product-moment correlation coefficient might also be calculated:

This example also demonstrates that sophisticated calculations will not overcome the use of badly prepared data. The heights were originally given in inches, and have been converted to the nearest centimetre. Since the conversion has introduced rounding error, this is not an exact conversion. The original inches can be recovered by Round(x/0.0254) and then re-converted to metric without rounding: if this is done, the results become

Thus a seemingly small variation in the data has a real effect.
See also
- Design matrix#Simple linear regression
- Line fitting
- Linear trend estimation
- Linear segmented regression
- Proofs involving ordinary least squares—derivation of all formulas used in this article in general multidimensional case
References
- Seltman, Howard J. (2008-09-08). Experimental Design and Analysis (PDF). p. 227.
- "Statistical Sampling and Regression: Simple Linear Regression". Columbia University. Retrieved 2016-10-17.
When one independent variable is used in a regression, it is called a simple regression;(...)
- Lane, David M. Introduction to Statistics (PDF). p. 462.
- Zou KH; Tuncali K; Silverman SG (2003). "Correlation and simple linear regression". Radiology. 227 (3): 617–22. doi:10.1148/radiol.2273011499. ISSN 0033-8419. OCLC 110941167. PMID 12773666.
- Altman, Naomi; Krzywinski, Martin (2015). "Simple linear regression". Nature Methods. 12 (11): 999–1000. doi:10.1038/nmeth.3627. ISSN 1548-7091. OCLC 5912005539. PMID 26824102.
- Kenney, J. F. and Keeping, E. S. (1962) "Linear Regression and Correlation." Ch. 15 in Mathematics of Statistics, Pt. 1, 3rd ed. Princeton, NJ: Van Nostrand, pp. 252–285
- Casella, G. and Berger, R. L. (2002), "Statistical Inference" (2nd Edition), Cengage, ISBN 978-0-534-24312-8, pp. 558–559.
External links
- Wolfram MathWorld's explanation of Least Squares Fitting, and how to calculate it
- Mathematics of simple regression (Robert Nau, Duke University)
