German tank problem
In the statistical theory of estimation, the German tank problem consists of estimating the maximum of a discrete uniform distribution from sampling without replacement. In simple terms, suppose there exists an unknown number of items which are sequentially numbered from 1 to N. A random sample of these items is taken and their sequence numbers observed; the problem is to estimate N from these observed numbers.

The problem can be approached using either frequentist inference or Bayesian inference, leading to different results. Estimating the population maximum based on a single sample yields divergent results, whereas estimation based on multiple samples is a practical estimation question whose answer is simple (especially in the frequentist setting) but not obvious (especially in the Bayesian setting).
The problem is named after its historical application by Allied forces in World War II to the estimation of the monthly rate of German tank production from very limited data. This exploited the manufacturing practice of assigning and attaching ascending sequences of serial numbers to tank components (chassis, gearbox, engine, wheels), with some of the tanks eventually being captured in battle by Allied forces.
Suppositions
The adversary is presumed to have manufactured a series of tanks marked with consecutive whole numbers, beginning with serial number 1. Additionally, regardless of a tank's date of manufacture, history of service, or the serial number it bears, the distribution over serial numbers becoming revealed to analysis is uniform, up to the point in time when the analysis is conducted.
Example
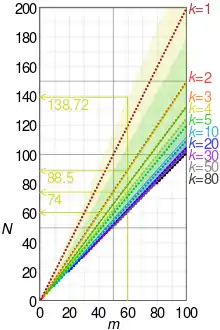
Assuming tanks are assigned sequential serial numbers starting with 1, suppose that four tanks are captured and that they have the serial numbers: 19, 40, 42 and 60.
The frequentist approach predicts the total number of tanks produced will be:

The Bayesian approach predicts that the median number of tanks produced will be very similar to the frequentist prediction:

whereas the Bayesian mean predicts that the number of tanks produced would be:

Let N equal the total number of tanks predicted to have been produced, m equal the highest serial number observed and k equal the number of tanks captured.
The frequentist prediction is calculated as:

The Bayesian median is calculated as:

The Bayesian mean is calculated as:

Both Bayesian computations are based on the following probability mass function:

This distribution has a positive skewness, related to the fact that there are at least 60 tanks. Because of this skewness, the mean may not be the most meaningful estimate. The median in this example is 74.5, in close agreement with the frequentist formula. Using Stirling's approximation, the Bayesian probability function may be approximated as

which results in the following approximation for the median:

Finally, the average estimate by Bayesians, and its deviation, are computed as:

Historical example of the problem

During the course of the Second World War, the Western Allies made sustained efforts to determine the extent of German production and approached this in two major ways: conventional intelligence gathering and statistical estimation. In many cases, statistical analysis substantially improved on conventional intelligence. In some cases, conventional intelligence was used in conjunction with statistical methods, as was the case in estimation of Panther tank production just prior to D-Day.
The allied command structure had thought the Panzer V (Panther) tanks seen in Italy, with their high velocity, long-barreled 75 mm/L70 guns, were unusual heavy tanks and would only be seen in northern France in small numbers, much the same way as the Tiger I was seen in Tunisia. The US Army was confident that the Sherman tank would continue to perform well, as it had versus the Panzer III and Panzer IV tanks in North Africa and Sicily.[lower-alpha 1] Shortly before D-Day, rumors indicated that large numbers of Panzer V tanks were being used.
To determine whether this was true, the Allies attempted to estimate the number of tanks being produced. To do this, they used the serial numbers on captured or destroyed tanks. The principal numbers used were gearbox numbers, as these fell in two unbroken sequences. Chassis and engine numbers were also used, though their use was more complicated. Various other components were used to cross-check the analysis. Similar analyses were done on wheels, which were observed to be sequentially numbered (i.e., 1, 2, 3, ..., N).[2][lower-alpha 2][3][4]
The analysis of tank wheels yielded an estimate for the number of wheel molds that were in use. A discussion with British road wheel makers then estimated the number of wheels that could be produced from this many molds, which yielded the number of tanks that were being produced each month. Analysis of wheels from two tanks (32 road wheels each, 64 road wheels total) yielded an estimate of 270 tanks produced in February 1944, substantially more than had previously been suspected.[5]
German records after the war showed production for the month of February 1944 was 276.[6][lower-alpha 3] The statistical approach proved to be far more accurate than conventional intelligence methods, and the phrase "German tank problem" became accepted as a descriptor for this type of statistical analysis.
Estimating production was not the only use of this serial-number analysis. It was also used to understand German production more generally, including number of factories, relative importance of factories, length of supply chain (based on lag between production and use), changes in production, and use of resources such as rubber.
Specific data
According to conventional Allied intelligence estimates, the Germans were producing around 1,400 tanks a month between June 1940 and September 1942. Applying the formula below to the serial numbers of captured tanks, the number was calculated to be 246 a month. After the war, captured German production figures from the ministry of Albert Speer showed the actual number to be 245.[3]
Estimates for some specific months are given as:[7]
| Month | Statistical estimate | Intelligence estimate | German records |
|---|---|---|---|
| June 1940 | 169 | 1,000 | 122 |
| June 1941 | 244 | 1,550 | 271 |
| August 1942 | 327 | 1,550 | 342 |
Similar analyses

Similar serial-number analysis was used for other military equipment during World War II, most successfully for the V-2 rocket.[8]
Factory markings on Soviet military equipment were analyzed during the Korean War, and by German intelligence during World War II.[9]
In the 1980s, some Americans were given access to the production line of Israel's Merkava tanks. The production numbers were classified, but the tanks had serial numbers, allowing estimation of production.[10]
The formula has been used in non-military contexts, for example to estimate the number of Commodore 64 computers built, where the result (12.5 million) matches the low-end estimates.[11]
Countermeasures
To confound serial-number analysis, serial numbers can be excluded, or usable auxiliary information reduced. Alternatively, serial numbers that resist cryptanalysis can be used, most effectively by randomly choosing numbers without replacement from a list that is much larger than the number of objects produced (compare the one-time pad), or produce random numbers and check them against the list of already assigned numbers; collisions are likely to occur unless the number of digits possible is more than twice the number of digits in the number of objects produced (where the serial number can be in any base); see birthday problem.[lower-alpha 4] For this, a cryptographically secure pseudorandom number generator may be used. All these methods require a lookup table (or breaking the cypher) to back out from serial number to production order, which complicates use of serial numbers: a range of serial numbers cannot be recalled, for instance, but each must be looked up individually, or a list generated.
Alternatively, sequential serial numbers can be encrypted with a simple substitution cipher, which allows easy decoding, but is also easily broken by a known-plaintext attack: even if starting from an arbitrary point, the plaintext has a pattern (namely, numbers are in sequence). One example is given in Ken Follett's novel Code to Zero, where the encryption of the Jupiter-C rocket serial numbers is given by:
| H | U | N | T | S | V | I | L | E | X |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 |
The code word here is Huntsville (with repeated letters omitted) to get a 10-letter key.[12] The rocket number 13 was therefore "HN", and the rocket number 24 was "UT".
Strong encryption of serial numbers without expanding them can be achieved with format-preserving encryption. Instead of storing a truly random permutation on the set of all possible serial numbers in a large table, such algorithms will derive a pseudo-random permutation from a secret key. Security can then be defined as the pseudo-random permutation being indistinguishable from a truly random permutation to an attacker who doesn't know the key.
Frequentist analysis
Minimum-variance unbiased estimator
For point estimation (estimating a single value for the total, ), the minimum-variance unbiased estimator (MVUE, or UMVU estimator) is given by:[lower-alpha 5]


where m is the largest serial number observed (sample maximum) and k is the number of tanks observed (sample size).[10][13] Note that once a serial number has been observed, it is no longer in the pool and will not be observed again.
This has a variance[10]

so the standard deviation is approximately N/k, the expected size of the gap between sorted observations in the sample.
The formula may be understood intuitively as the sample maximum plus the average gap between observations in the sample, the sample maximum being chosen as the initial estimator, due to being the maximum likelihood estimator,[lower-alpha 6] with the gap being added to compensate for the negative bias of the sample maximum as an estimator for the population maximum,[lower-alpha 7] and written as

This can be visualized by imagining that the observations in the sample are evenly spaced throughout the range, with additional observations just outside the range at 0 and N + 1. If starting with an initial gap between 0 and the lowest observation in the sample (the sample minimum), the average gap between consecutive observations in the sample is ; the being because the observations themselves are not counted in computing the gap between observations.[lower-alpha 8]. A derivation of the expected value and the variance of the sample maximum are shown in the page of the discrete uniform distribution.


This philosophy is formalized and generalized in the method of maximum spacing estimation; a similar heuristic is used for plotting position in a Q–Q plot, plotting sample points at k / (n + 1), which is evenly on the uniform distribution, with a gap at the end.
Confidence intervals
Instead of, or in addition to, point estimation, interval estimation can be carried out, such as confidence intervals. These are easily computed, based on the observation that the probability that k observations in the sample will fall in an interval covering p of the range (0 ≤ p ≤ 1) is pk (assuming in this section that draws are with replacement, to simplify computations; if draws are without replacement, this overstates the likelihood, and intervals will be overly conservative).
Thus the sampling distribution of the quantile of the sample maximum is the graph x1/k from 0 to 1: the p-th to q-th quantile of the sample maximum m are the interval [p1/kN, q1/kN]. Inverting this yields the corresponding confidence interval for the population maximum of [m/q1/k, m/p1/k].
For example, taking the symmetric 95% interval p = 2.5% and q = 97.5% for k = 5 yields 0.0251/5 ≈ 0.48, 0.9751/5 ≈ 0.995, so the confidence interval is approximately [1.005m, 2.08m]. The lower bound is very close to m, thus more informative is the asymmetric confidence interval from p = 5% to 100%; for k = 5 this yields 0.051/5 ≈ 0.55 and the interval [m, 1.82m].
More generally, the (downward biased) 95% confidence interval is [m, m/0.051/k] = [m, m·201/k]. For a range of k values, with the UMVU point estimator (plus 1 for legibility) for reference, this yields:
| k | Point estimate | Confidence interval |
|---|---|---|
| 1 | 2m | [m, 20m] |
| 2 | 1.5m | [m, 4.5m] |
| 5 | 1.2m | [m, 1.82m] |
| 10 | 1.1m | [m, 1.35m] |
| 20 | 1.05m | [m, 1.16m] |
Immediate observations are:
- For small sample sizes, the confidence interval is very wide, reflecting great uncertainty in the estimate.
- The range shrinks rapidly, reflecting the exponentially decaying probability that all observations in the sample will be significantly below the maximum.
- The confidence interval exhibits positive skew, as N can never be below the sample maximum, but can potentially be arbitrarily high above it.
Note that m/k cannot be used naively (or rather (m + m/k − 1)/k) as an estimate of the standard error SE, as the standard error of an estimator is based on the population maximum (a parameter), and using an estimate to estimate the error in that very estimate is circular reasoning.
Bayesian analysis
The Bayesian approach to the German tank problem is to consider the credibility that the number of enemy tanks is equal to the number , when the number of observed tanks, is equal to the number , and the maximum observed serial number is equal to the number . The answer to this problem depends on the choice of prior for . One can proceed using a proper prior, e.g., the Poisson or Negative Binomial distribution, where closed formula for the posterior mean and posterior variance can be obtained.[14] An alternative is to proceed using direct calculations as shown below.







For brevity, in what follows, is written


Probability of M knowing N and K
The expression

is the conditional probability that the maximum serial number observed, M, is equal to m, when the number of enemy tanks, N, is known to be equal to n, and the number of enemy tanks observed, K, is known to be equal to k.
It is

where is a binomial coefficient and is an Iverson bracket.


The expression can be derived as follows: answers the question: "What is the probability of a specific serial number being the highest number observed in a sample of tanks, given there are tanks in total?"




One can think of the sample of size to be the result of individual draws. Assume is observed on draw number . The probability of this occurring is:


As can be seen from the right-hand side, this expression is independent of and therefore the same for each . As can be drawn on different draws, the probability of any specific being the largest one observed is times the above probability:


Probability of M knowing only K
The expression is the probability that the maximum serial number is equal to m once k tanks have been observed but before the serial numbers have actually been observed.

The expression can be re-written in terms of the other quantities by marginalizing over all possible .


Credibility of N knowing only K
The expression

is the credibility that the total number of tanks, N, is equal to n when the number K tanks observed is known to be k, but before the serial numbers have been observed. Assume that it is some discrete uniform distribution

The upper limit must be finite, because the function


is not a mass distribution function.
Credibility of N knowing M and K

If k ≥ 2, then , and the unwelcome variable disappears from the expression.



For k ≥ 1 the mode of the distribution of the number of enemy tanks is m.
For k ≥ 2, the credibility that the number of enemy tanks is equal to , is

The credibility that the number of enemy tanks, N, is greater than n, is

Mean value and standard deviation
For k ≥ 3, N has the finite mean value:

For k ≥ 4, N has the finite standard deviation:

These formulas are derived below.
Summation formula
The following binomial coefficient identity is used below for simplifying series relating to the German Tank Problem.

This sum formula is somewhat analogous to the integral formula

These formulas apply for k > 1.
One tank
Observing one tank randomly out of a population of n tanks gives the serial number m with probability 1/n for m ≤ n, and zero probability for m > n. Using Iverson bracket notation this is written

This is the conditional probability mass distribution function of .
When considered a function of n for fixed m this is a likelihood function.

The maximum likelihood estimate for the total number of tanks is N0 = m.
The marginal likelihood (i.e. marginalized over all models) is infinite, being a tail of the harmonic series.

but

where is the harmonic number.

The credibility mass distribution function depends on the prior limit :

The mean value of is

Two tanks
If two tanks rather than one are observed, then the probability that the larger of the observed two serial numbers is equal to m, is

When considered a function of n for fixed m this is a likelihood function

The total likelihood is

and the credibility mass distribution function is

The median satisfies


so

and so the median is

but the mean value of N is infinite

Many tanks
Credibility mass distribution function
The conditional probability that the largest of k observations taken from the serial numbers {1,...,n}, is equal to m, is

The likelihood function of n is the same expression

The total likelihood is finite for k ≥ 2:

The credibility mass distribution function is

The complementary cumulative distribution function is the credibility that N > x

The cumulative distribution function is the credibility that N ≤ x

Order of magnitude
The order of magnitude of the number of enemy tanks is

Statistical uncertainty
The statistical uncertainty is the standard deviation σ, satisfying the equation

So

and

The variance-to-mean ratio is simply

{kind=link}
See also
- Mark and recapture, other method of estimating population size
- Maximum spacing estimation, which generalizes the intuition of "assume uniformly distributed"
- Copernican principle and Lindy effect, analogous predictions of lifetime assuming just one observation in the sample (current age).
- The Doomsday argument, application to estimate expected survival time of the human race.
- Generalized extreme value distribution, possible limit distributions of sample maximum (opposite question).
- Maximum likelihood
- Bias of an estimator
- Likelihood function
Further reading
- Goodman, L. A. (1954). "Some Practical Techniques in Serial Number Analysis". Journal of the American Statistical Association. American Statistical Association. 49 (265): 97–112. doi:10.2307/2281038. JSTOR 2281038.
Notes
- An Armored Ground Forces policy statement of November 1943 concluded: "The recommendation of a limited proportion of tanks carrying a 90 mm gun is not concurred in for the following reasons: The M4 tank has been hailed widely as the best tank of the battlefield today. ... There appears to be no fear on the part of our forces of the German Mark VI (Tiger) tank. There can be no basis for the T26 tank other than the conception of a tank-vs.-tank duel – which is believed to be unsound and unnecessary."[1]
- The lower bound was unknown, but to simplify the discussion, this detail is generally omitted, taking the lower bound as known to be 1.
- Ruggles & Brodie is largely a practical analysis and summary, not a mathematical one – the estimation problem is only mentioned in footnote 3 on page 82, where they estimate the maximum as "sample maximum + average gap".
- As discussed in birthday attack, one can expect a collision after 1.25√H numbers, if choosing from H possible outputs. This square root corresponds to half the digits. For example, in any base, the square root of a number with 100 digits is approximately a number with 50 digits.
- In a continuous distribution, there is no −1 term.
- Given a particular set of observations, this set is most likely to occur if the population maximum is the sample maximum, not a higher value (it cannot be lower).
- The sample maximum is never more than the population maximum, but can be less, hence it is a biased estimator: it will tend to underestimate the population maximum.
- For example, the gap between 2 and 7 is (7 − 2) − 1 = 4, consisting of 3, 4, 5, and 6.
References
- AGF policy statement. Chief of staff AGF. November 1943. MHI
- Ruggles & Brodie 1947, p. ?.
- "Gavyn Davies does the maths – How a statistical formula won the war". The Guardian. 20 July 2006. Retrieved 6 July 2014.
- Matthews, Robert (23 May 1998), "Data sleuths go to war, sidebar in feature "Hidden truths"", New Scientist, archived from the original on 18 April 2001
- Bob Carruthers (1 March 2012). Panther V in Combat. Coda Books. pp. 94–. ISBN 978-1-908538-15-4.
- Ruggles & Brodie 1947, pp. 82–83.
- Ruggles & Brodie 1947, p. 89.
- Ruggles & Brodie 1947, pp. 90–91.
- Volz 2008.
- Johnson 1994.
- "How many Commodore 64 computers were really sold?". pagetable.com. 1 February 2011. Archived from the original on 6 March 2016. Retrieved 6 July 2014.
- "Rockets and Missiles". www.spaceline.org.
- Joyce, Smart. "German Tank Problem". Logan High School. Archived from the original on 24 April 2012. Retrieved 8 July 2014.
- Höhle, M.; Held, L. (2006). "Bayesian Estimation of the Size of a Population" (PDF). Technical Report SFB 386, No. 399, Department of Statistics, University of Munich. Retrieved 17 April 2016.
Works cited
- Johnson, R. W. (Summer 1994). "Estimating the Size of a Population" (PDF). Teaching Statistics. 16 (2): 50–52. doi:10.1111/j.1467-9639.1994.tb00688.x. Archived from the original (PDF) on 23 February 2014.
- Ruggles, R.; Brodie, H. (1947). "An Empirical Approach to Economic Intelligence in World War II". Journal of the American Statistical Association. 42 (237): 72. doi:10.1080/01621459.1947.10501915. JSTOR 2280189.
- Volz, A. G. (July 2008). "A Soviet Estimate of German Tank Production". The Journal of Slavic Military Studies. 21 (3): 588–590. doi:10.1080/13518040802313902. S2CID 144483708.