Balding–Nichols model
In population genetics, the Balding–Nichols model is a statistical description of the allele frequencies in the components of a sub-divided population.[1] With background allele frequency p the allele frequencies, in sub-populations separated by Wright's FST F, are distributed according to independent draws from

|
Probability density function 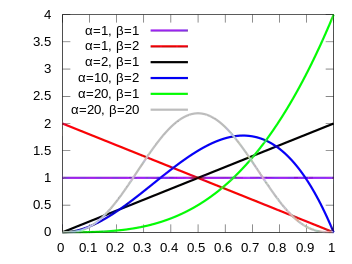 | |||
|
Cumulative distribution function 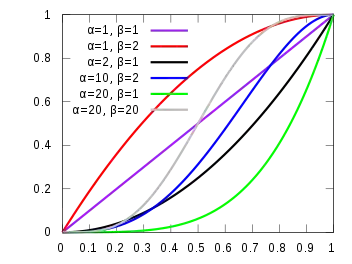 | |||
| Parameters |
(real) (real) For ease of notation, let , and | ||
|---|---|---|---|
| Support | |||
| CDF | |||
| Mean | |||
| Median | no closed form | ||
| Mode | |||
| Variance | |||
| Skewness | |||
| MGF | |||
| CF | |||














where B is the Beta distribution. This distribution has mean p and variance Fp(1 – p).[2]
The model is due to David Balding and Richard Nichols and is widely used in the forensic analysis of DNA profiles and in population models for genetic epidemiology.
References
- Balding, DJ; Nichols, RA (1995). "A method for quantifying differentiation between populations at multi-allelic loci and its implications for investigating identity and paternity". Genetica. Springer. 96 (1–2): 3–12. doi:10.1007/BF01441146. PMID 7607457.
- Alkes L. Price; Nick J. Patterson; Robert M. Plenge; Michael E. Weinblatt; Nancy A. Shadick; David Reich (2006). "Principal components analysis corrects for stratification in genome-wide association studies" (PDF). Nature Genetics. 38 (8): 904–909. doi:10.1038/ng1847. PMID 16862161. Archived from the original (PDF) on 2008-07-03. Retrieved 2009-02-19.
This article is issued from Wikipedia. The text is licensed under Creative Commons - Attribution - Sharealike. Additional terms may apply for the media files.