Student's t-test
The t-test is any statistical hypothesis test in which the test statistic follows a Student's t-distribution under the null hypothesis.
A t-test is the most commonly applied when the test statistic would follow a normal distribution if the value of a scaling term in the test statistic were known. When the scaling term is unknown and is replaced by an estimate based on the data, the test statistics (under certain conditions) follow a Student's t distribution. The t-test can be used, for example, to determine if the means of two sets of data are significantly different from each other.
History

The term "t-statistic" is abbreviated from "hypothesis test statistic".[1] In statistics, the t-distribution was first derived as a posterior distribution in 1876 by Helmert[2][3][4] and Lüroth.[5][6][7] The t-distribution also appeared in a more general form as Pearson Type IV distribution in Karl Pearson's 1895 paper.[8] However, the T-Distribution, also known as Student's T Distribution gets its name from William Sealy Gosset who first published it in English in 1908 in the scientific journal Biometrika using his pseudonym "Student"[9][10] because his employer preferred staff to use pen names when publishing scientific papers instead of their real name, so he used the name "Student" to hide his identity.[11] Gosset worked at the Guinness Brewery in Dublin, Ireland, and was interested in the problems of small samples – for example, the chemical properties of barley with small sample sizes. Hence a second version of the etymology of the term Student is that Guinness did not want their competitors to know that they were using the t-test to determine the quality of raw material. Although it was William Gosset after whom the term "Student" is penned, it was actually through the work of Ronald Fisher that the distribution became well known as "Student's distribution"[12] and "Student's t-test".
Gosset had been hired owing to Claude Guinness's policy of recruiting the best graduates from Oxford and Cambridge to apply biochemistry and statistics to Guinness's industrial processes.[13] Gosset devised the t-test as an economical way to monitor the quality of stout. The t-test work was submitted to and accepted in the journal Biometrika and published in 1908.[14] Company policy at Guinness forbade its chemists from publishing their findings, so Gosset published his statistical work under the pseudonym "Student" (see Student's t-distribution for a detailed history of this pseudonym, which is not to be confused with the literal term student).
Guinness had a policy of allowing technical staff leave for study (so-called "study leave"), which Gosset used during the first two terms of the 1906–1907 academic year in Professor Karl Pearson's Biometric Laboratory at University College London.[15] Gosset's identity was then known to fellow statisticians and to editor-in-chief Karl Pearson.[16]
Uses
Among the most frequently used t-tests are:
- A one-sample location test of whether the mean of a population has a value specified in a null hypothesis.
- A two-sample location test of the null hypothesis such that the means of two populations are equal. All such tests are usually called Student's t-tests, though strictly speaking that name should only be used if the variances of the two populations are also assumed to be equal; the form of the test used when this assumption is dropped is sometimes called Welch's t-test. These tests are often referred to as "unpaired" or "independent samples" t-tests, as they are typically applied when the statistical units underlying the two samples being compared are non-overlapping.[17]
Assumptions
Most test statistics have the form t = Z/s, where Z and s are functions of the data.
Z may be sensitive to the alternative hypothesis (i.e., its magnitude tends to be larger when the alternative hypothesis is true), whereas s is a scaling parameter that allows the distribution of t to be determined.
As an example, in the one-sample t-test

where X is the sample mean from a sample X1, X2, …, Xn, of size n, s is the standard error of the mean, is the estimate of the standard deviation of the population, and μ is the population mean.

The assumptions underlying a t-test in the simplest form above are that:
- X follows a normal distribution with mean μ and variance σ2/n
- s2(n − 1)/σ2 follows a χ2 distribution with n − 1 degrees of freedom. This assumption is met when the observations used for estimating s2 come from a normal distribution (and i.i.d for each group).
- Z and s are independent.
In the t-test comparing the means of two independent samples, the following assumptions should be met:
- The means of the two populations being compared should follow normal distributions. Under weak assumptions, this follows in large samples from the central limit theorem, even when the distribution of observations in each group is non-normal.[18]
- If using Student's original definition of the t-test, the two populations being compared should have the same variance (testable using F-test, Levene's test, Bartlett's test, or the Brown–Forsythe test; or assessable graphically using a Q–Q plot). If the sample sizes in the two groups being compared are equal, Student's original t-test is highly robust to the presence of unequal variances.[19] Welch's t-test is insensitive to equality of the variances regardless of whether the sample sizes are similar.
- The data used to carry out the test should either be sampled independently from the two populations being compared or be fully paired. This is in general not testable from the data, but if the data are known to be dependent (e.g. paired by test design), a dependent test has to be applied. For partially paired data, the classical independent t-tests may give invalid results as the test statistic might not follow a t distribution, while the dependent t-test is sub-optimal as it discards the unpaired data.[20]
Most two-sample t-tests are robust to all but large deviations from the assumptions.[21]
For exactness, the t-test and Z-test require normality of the sample means, and the t-test additionally requires that the sample variance follows a scaled χ2 distribution, and that the sample mean and sample variance be statistically independent. Normality of the individual data values is not required if these conditions are met. By the central limit theorem, sample means of moderately large samples are often well-approximated by a normal distribution even if the data are not normally distributed. For non-normal data, the distribution of the sample variance may deviate substantially from a χ2 distribution. However, if the sample size is large, Slutsky's theorem implies that the distribution of the sample variance has little effect on the distribution of the test statistic.
Unpaired and paired two-sample t-tests
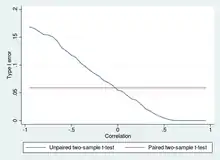
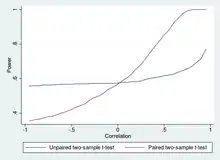
Two-sample t-tests for a difference in mean involve independent samples (unpaired samples) or paired samples. Paired t-tests are a form of blocking, and have greater power than unpaired tests when the paired units are similar with respect to "noise factors" that are independent of membership in the two groups being compared.[22] In a different context, paired t-tests can be used to reduce the effects of confounding factors in an observational study.
Independent (unpaired) samples
The independent samples t-test is used when two separate sets of independent and identically distributed samples are obtained, one from each of the two populations being compared. For example, suppose we are evaluating the effect of a medical treatment, and we enroll 100 subjects into our study, then randomly assign 50 subjects to the treatment group and 50 subjects to the control group. In this case, we have two independent samples and would use the unpaired form of the t-test.
Paired samples
Paired samples t-tests typically consist of a sample of matched pairs of similar units, or one group of units that has been tested twice (a "repeated measures" t-test).
A typical example of the repeated measures t-test would be where subjects are tested prior to a treatment, say for high blood pressure, and the same subjects are tested again after treatment with a blood-pressure-lowering medication. By comparing the same patient's numbers before and after treatment, we are effectively using each patient as their own control. That way the correct rejection of the null hypothesis (here: of no difference made by the treatment) can become much more likely, with statistical power increasing simply because the random interpatient variation has now been eliminated. However, an increase of statistical power comes at a price: more tests are required, each subject having to be tested twice. Because half of the sample now depends on the other half, the paired version of Student's t-test has only n/2 − 1 degrees of freedom (with n being the total number of observations). Pairs become individual test units, and the sample has to be doubled to achieve the same number of degrees of freedom. Normally, there are n − 1 degrees of freedom (with n being the total number of observations).[23]
A paired samples t-test based on a "matched-pairs sample" results from an unpaired sample that is subsequently used to form a paired sample, by using additional variables that were measured along with the variable of interest.[24] The matching is carried out by identifying pairs of values consisting of one observation from each of the two samples, where the pair is similar in terms of other measured variables. This approach is sometimes used in observational studies to reduce or eliminate the effects of confounding factors.
Paired samples t-tests are often referred to as "dependent samples t-tests".
Calculations
Explicit expressions that can be used to carry out various t-tests are given below. In each case, the formula for a test statistic that either exactly follows or closely approximates a t-distribution under the null hypothesis is given. Also, the appropriate degrees of freedom are given in each case. Each of these statistics can be used to carry out either a one-tailed or two-tailed test.
Once the t value and degrees of freedom are determined, a p-value can be found using a table of values from Student's t-distribution. If the calculated p-value is below the threshold chosen for statistical significance (usually the 0.10, the 0.05, or 0.01 level), then the null hypothesis is rejected in favor of the alternative hypothesis.
One-sample t-test
In testing the null hypothesis that the population mean is equal to a specified value μ0, one uses the statistic

where is the sample mean, s is the sample standard deviation and n is the sample size. The degrees of freedom used in this test are n − 1. Although the parent population does not need to be normally distributed, the distribution of the population of sample means is assumed to be normal.

By the central limit theorem, if the observations are independent and the second moment exists, then will be approximately normal N(0;1).

Slope of a regression line
Suppose one is fitting the model

where x is known, α and β are unknown, ε is a normally distributed random variable with mean 0 and unknown variance σ2, and Y is the outcome of interest. We want to test the null hypothesis that the slope β is equal to some specified value β0 (often taken to be 0, in which case the null hypothesis is that x and y are uncorrelated).
Let

Then

has a t-distribution with n − 2 degrees of freedom if the null hypothesis is true. The standard error of the slope coefficient:

can be written in terms of the residuals. Let

Then tscore is given by:

Another way to determine the tscore is:

where r is the Pearson correlation coefficient.
The tscore, intercept can be determined from the tscore, slope:

where sx2 is the sample variance.
Equal sample sizes and variance
Given two groups (1, 2), this test is only applicable when:
- the two sample sizes (that is, the number n of participants of each group) are equal;
- it can be assumed that the two distributions have the same variance;
Violations of these assumptions are discussed below.
The t statistic to test whether the means are different can be calculated as follows:

where

Here sp is the pooled standard deviation for n = n1 = n2 and s 2
X1 and s 2
X2 are the unbiased estimators of the variances of the two samples. The denominator of t is the standard error of the difference between two means.
For significance testing, the degrees of freedom for this test is 2n − 2 where n is the number of participants in each group.
Equal or unequal sample sizes, similar variances (1/2 < sX1/sX2 < 2)
This test is used only when it can be assumed that the two distributions have the same variance. (When this assumption is violated, see below.) The previous formulae are a special case of the formulae below, one recovers them when both samples are equal in size: n = n1 = n2.
The t statistic to test whether the means are different can be calculated as follows:

where

is an estimator of the pooled standard deviation of the two samples: it is defined in this way so that its square is an unbiased estimator of the common variance whether or not the population means are the same. In these formulae, ni − 1 is the number of degrees of freedom for each group, and the total sample size minus two (that is, n1 + n2 − 2) is the total number of degrees of freedom, which is used in significance testing.
Equal or unequal sample sizes, unequal variances (sX1 > 2sX2 or sX2 > 2sX1)
This test, also known as Welch's t-test, is used only when the two population variances are not assumed to be equal (the two sample sizes may or may not be equal) and hence must be estimated separately. The t statistic to test whether the population means are different is calculated as:

where

Here si2 is the unbiased estimator of the variance of each of the two samples with ni = number of participants in group i (1 or 2). In this case is not a pooled variance. For use in significance testing, the distribution of the test statistic is approximated as an ordinary Student's t-distribution with the degrees of freedom calculated using


This is known as the Welch–Satterthwaite equation. The true distribution of the test statistic actually depends (slightly) on the two unknown population variances (see Behrens–Fisher problem).
Dependent t-test for paired samples
This test is used when the samples are dependent; that is, when there is only one sample that has been tested twice (repeated measures) or when there are two samples that have been matched or "paired". This is an example of a paired difference test. The t statistic is calculated as

where and are the average and standard deviation of the differences between all pairs. The pairs are e.g. either one person's pre-test and post-test scores or between-pairs of persons matched into meaningful groups (for instance drawn from the same family or age group: see table). The constant μ0 is zero if we want to test whether the average of the difference is significantly different. The degree of freedom used is n − 1, where n represents the number of pairs.


Example of repeated measures Number Name Test 1 Test 2 1 Mike 35% 67% 2 Melanie 50% 46% 3 Melissa 90% 86% 4 Mitchell 78% 91% Example of matched pairs Pair Name Age Test 1 John 35 250 1 Jane 36 340 2 Jimmy 22 460 2 Jessy 21 200
Worked examples
Let A1 denote a set obtained by drawing a random sample of six measurements:

and let A2 denote a second set obtained similarly:

These could be, for example, the weights of screws that were chosen out of a bucket.
We will carry out tests of the null hypothesis that the means of the populations from which the two samples were taken are equal.
The difference between the two sample means, each denoted by Xi, which appears in the numerator for all the two-sample testing approaches discussed above, is

The sample standard deviations for the two samples are approximately 0.05 and 0.11, respectively. For such small samples, a test of equality between the two population variances would not be very powerful. Since the sample sizes are equal, the two forms of the two-sample t-test will perform similarly in this example.
Unequal variances
If the approach for unequal variances (discussed above) is followed, the results are

and the degrees of freedom

The test statistic is approximately 1.959, which gives a two-tailed test p-value of 0.09077.
Equal variances
If the approach for equal variances (discussed above) is followed, the results are

and the degrees of freedom

The test statistic is approximately equal to 1.959, which gives a two-tailed p-value of 0.07857.
Related statistical tests
Alternatives to the t-test for location problems
The t-test provides an exact test for the equality of the means of two i.i.d. normal populations with unknown, but equal, variances. (Welch's t-test is a nearly exact test for the case where the data are normal but the variances may differ.) For moderately large samples and a one tailed test, the t-test is relatively robust to moderate violations of the normality assumption.[25] In large enough samples, the t-test asymptotically approaches the z-test, and becomes robust even to large deviations from normality.[18]
If the data are substantially non-normal and the sample size is small, the t-test can give misleading results. See Location test for Gaussian scale mixture distributions for some theory related to one particular family of non-normal distributions.
When the normality assumption does not hold, a non-parametric alternative to the t-test may have better statistical power. However, when data are non-normal with differing variances between groups, a t-test may have better type-1 error control than some non-parametric alternatives.[26] Furthermore, non-parametric methods, such as the Mann-Whitney U test discussed below, typically do not test for a difference of means, so should be used carefully if a difference of means is of primary scientific interest.[18] For example, Mann-Whitney U test will keep the type 1 error at the desired level alpha if both groups have the same distribution. It will also have power in detecting an alternative by which group B has the same distribution as A but after some shift by a constant (in which case there would indeed be a difference in the means of the two groups). However, there could be cases where group A and B will have different distributions but with the same means (such as two distributions, one with positive skewness and the other with a negative one, but shifted so to have the same means). In such cases, MW could have more than alpha level power in rejecting the Null hypothesis but attributing the interpretation of difference in means to such a result would be incorrect.
In the presence of an outlier, the t-test is not robust. For example, for two independent samples when the data distributions are asymmetric (that is, the distributions are skewed) or the distributions have large tails, then the Wilcoxon rank-sum test (also known as the Mann–Whitney U test) can have three to four times higher power than the t-test.[25][27][28] The nonparametric counterpart to the paired samples t-test is the Wilcoxon signed-rank test for paired samples. For a discussion on choosing between the t-test and nonparametric alternatives, see Lumley, et al. (2002).[18]
One-way analysis of variance (ANOVA) generalizes the two-sample t-test when the data belong to more than two groups.
A design which includes both paired observations and independent observations
When both paired observations and independent observations are present in the two sample design, assuming data are missing completely at random (MCAR), the paired observations or independent observations may be discarded in order to proceed with the standard tests above. Alternatively making use of all of the available data, assuming normality and MCAR, the generalized partially overlapping samples t-test could be used.[29]
Multivariate testing
A generalization of Student's t statistic, called Hotelling's t-squared statistic, allows for the testing of hypotheses on multiple (often correlated) measures within the same sample. For instance, a researcher might submit a number of subjects to a personality test consisting of multiple personality scales (e.g. the Minnesota Multiphasic Personality Inventory). Because measures of this type are usually positively correlated, it is not advisable to conduct separate univariate t-tests to test hypotheses, as these would neglect the covariance among measures and inflate the chance of falsely rejecting at least one hypothesis (Type I error). In this case a single multivariate test is preferable for hypothesis testing. Fisher's Method for combining multiple tests with alpha reduced for positive correlation among tests is one. Another is Hotelling's T2 statistic follows a T2 distribution. However, in practice the distribution is rarely used, since tabulated values for T2 are hard to find. Usually, T2 is converted instead to an F statistic.
For a one-sample multivariate test, the hypothesis is that the mean vector (μ) is equal to a given vector (μ0). The test statistic is Hotelling's t2:

where n is the sample size, x is the vector of column means and S is an m × m sample covariance matrix.
For a two-sample multivariate test, the hypothesis is that the mean vectors (μ1, μ2) of two samples are equal. The test statistic is Hotelling's two-sample t2:

Software implementations
Many spreadsheet programs and statistics packages, such as QtiPlot, LibreOffice Calc, Microsoft Excel, SAS, SPSS, Stata, DAP, gretl, R, Python, PSPP, Matlab and Minitab, include implementations of Student's t-test.
| Language/Program | Function | Notes |
|---|---|---|
| Microsoft Excel pre 2010 | TTEST(array1, array2, tails, type) | See |
| Microsoft Excel 2010 and later | T.TEST(array1, array2, tails, type) | See |
| LibreOffice Calc | TTEST(Data1; Data2; Mode; Type) | See |
| Google Sheets | TTEST(range1, range2, tails, type) | See |
| Python | scipy.stats.ttest_ind(a, b, equal_var=True) | See |
| Matlab | ttest(data1, data2) | See |
| Mathematica | TTest[{data1,data2}] | See |
| R | t.test(data1, data2, var.equal=TRUE) | See |
| SAS | PROC TTEST | See |
| Java | tTest(sample1, sample2) | See |
| Julia | EqualVarianceTTest(sample1, sample2) | See |
| Stata | ttest data1 == data2 | See |
See also
References
Citations
- The Microbiome in Health and Disease. Academic Press. 2020-05-29. p. 397. ISBN 978-0-12-820001-8.
- Szabó, István (2003), Einführung in die Technische Mechanik, Springer Berlin Heidelberg, pp. 196–199, doi:10.1007/978-3-642-61925-0_16, ISBN 978-3-540-13293-6 Missing or empty
|title=(help);|chapter=ignored (help) - Schlyvitch, B. (October 1937). "Untersuchungen über den anastomotischen Kanal zwischen der Arteria coeliaca und mesenterica superior und damit in Zusammenhang stehende Fragen". Zeitschrift für Anatomie und Entwicklungsgeschichte. 107 (6): 709–737. doi:10.1007/bf02118337. ISSN 0340-2061. S2CID 27311567.
- Helmert (1876). "Die Genauigkeit der Formel von Peters zur Berechnung des wahrscheinlichen Beobachtungsfehlers directer Beobachtungen gleicher Genauigkeit". Astronomische Nachrichten (in German). 88 (8–9): 113–131. Bibcode:1876AN.....88..113H. doi:10.1002/asna.18760880802.
- Lüroth, J. (1876). "Vergleichung von zwei Werthen des wahrscheinlichen Fehlers". Astronomische Nachrichten (in German). 87 (14): 209–220. Bibcode:1876AN.....87..209L. doi:10.1002/asna.18760871402.
- Pfanzagl J, Sheynin O (1996). "Studies in the history of probability and statistics. XLIV. A forerunner of the t-distribution". Biometrika. 83 (4): 891–898. doi:10.1093/biomet/83.4.891. MR 1766040.
- Sheynin, Oscar (1995). "Helmert's work in the theory of errors". Archive for History of Exact Sciences. 49 (1): 73–104. doi:10.1007/BF00374700. ISSN 0003-9519. S2CID 121241599.
- Pearson, K. (1895-01-01). "Contributions to the Mathematical Theory of Evolution. II. Skew Variation in Homogeneous Material". Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences. 186: 343–414 (374). doi:10.1098/rsta.1895.0010. ISSN 1364-503X
- "Student" William Sealy Gosset (1908). "The probable error of a mean" (PDF). Biometrika. 6 (1): 1–25. doi:10.1093/biomet/6.1.1. hdl:10338.dmlcz/143545. JSTOR 2331554
- "T Table | History of T Table, Etymology, one-tail T Table, two-tail T Table and T-statistic".
- Wendl MC (2016). "Pseudonymous fame". Science. 351 (6280): 1406. doi:10.1126/science.351.6280.1406. PMID 27013722
- Walpole, Ronald E. (2006). Probability & statistics for engineers & scientists. Myers, H. Raymond. (7th ed.). New Delhi: Pearson. ISBN 81-7758-404-9. OCLC 818811849.
- O'Connor, John J.; Robertson, Edmund F., "William Sealy Gosset", MacTutor History of Mathematics archive, University of St Andrews.
- "The Probable Error of a Mean" (PDF). Biometrika. 6 (1): 1–25. 1908. doi:10.1093/biomet/6.1.1. hdl:10338.dmlcz/143545. Retrieved 24 July 2016.
- Raju, T. N. (2005). "William Sealy Gosset and William A. Silverman: Two "students" of science". Pediatrics. 116 (3): 732–5. doi:10.1542/peds.2005-1134. PMID 16140715. S2CID 32745754.
- Dodge, Yadolah (2008). The Concise Encyclopedia of Statistics. Springer Science & Business Media. pp. 234–235. ISBN 978-0-387-31742-7.
- Fadem, Barbara (2008). High-Yield Behavioral Science. High-Yield Series. Hagerstown, MD: Lippincott Williams & Wilkins. ISBN 978-0-7817-8258-6.
- Lumley, Thomas; Diehr, Paula; Emerson, Scott; Chen, Lu (May 2002). "The Importance of the Normality Assumption in Large Public Health Data Sets". Annual Review of Public Health. 23 (1): 151–169. doi:10.1146/annurev.publhealth.23.100901.140546. ISSN 0163-7525. PMID 11910059.
- Markowski, Carol A.; Markowski, Edward P. (1990). "Conditions for the Effectiveness of a Preliminary Test of Variance". The American Statistician. 44 (4): 322–326. doi:10.2307/2684360. JSTOR 2684360.
- Guo, Beibei; Yuan, Ying (2017). "A comparative review of methods for comparing means using partially paired data". Statistical Methods in Medical Research. 26 (3): 1323–1340. doi:10.1177/0962280215577111. PMID 25834090. S2CID 46598415.
- Bland, Martin (1995). An Introduction to Medical Statistics. Oxford University Press. p. 168. ISBN 978-0-19-262428-4.
- Rice, John A. (2006). Mathematical Statistics and Data Analysis (3rd ed.). Duxbury Advanced.
- Weisstein, Eric. "Student's t-Distribution". mathworld.wolfram.com.
- David, H. A.; Gunnink, Jason L. (1997). "The Paired t Test Under Artificial Pairing". The American Statistician. 51 (1): 9–12. doi:10.2307/2684684. JSTOR 2684684.
- Sawilowsky, Shlomo S.; Blair, R. Clifford (1992). "A More Realistic Look at the Robustness and Type II Error Properties of the t Test to Departures From Population Normality". Psychological Bulletin. 111 (2): 352–360. doi:10.1037/0033-2909.111.2.352.
- Zimmerman, Donald W. (January 1998). "Invalidation of Parametric and Nonparametric Statistical Tests by Concurrent Violation of Two Assumptions". The Journal of Experimental Education. 67 (1): 55–68. doi:10.1080/00220979809598344. ISSN 0022-0973.
- Blair, R. Clifford; Higgins, James J. (1980). "A Comparison of the Power of Wilcoxon's Rank-Sum Statistic to That of Student's t Statistic Under Various Nonnormal Distributions". Journal of Educational Statistics. 5 (4): 309–335. doi:10.2307/1164905. JSTOR 1164905.
- Fay, Michael P.; Proschan, Michael A. (2010). "Wilcoxon–Mann–Whitney or t-test? On assumptions for hypothesis tests and multiple interpretations of decision rules". Statistics Surveys. 4: 1–39. doi:10.1214/09-SS051. PMC 2857732. PMID 20414472.
- Derrick, B; Toher, D; White, P (2017). "How to compare the means of two samples that include paired observations and independent observations: A companion to Derrick, Russ, Toher and White (2017)" (PDF). The Quantitative Methods for Psychology. 13 (2): 120–126. doi:10.20982/tqmp.13.2.p120.
Sources
- O'Mahony, Michael (1986). Sensory Evaluation of Food: Statistical Methods and Procedures. CRC Press. p. 487. ISBN 0-82477337-3.
- Press, William H.; Teukolsky, Saul A.; Vetterling, William T.; Flannery, Brian P. (1992). http://www.nrbook.com/a/bookcpdf/c14–2.pdf
|chapter-url=missing title (help) (PDF). Numerical Recipes in C: The Art of Scientific Computing. Cambridge University Press. p. 616. ISBN 0-521-43108-5.
Further reading
- Boneau, C. Alan (1960). "The effects of violations of assumptions underlying the t test". Psychological Bulletin. 57 (1): 49–64. doi:10.1037/h0041412. PMID 13802482.
- Edgell, Stephen E.; Noon, Sheila M. (1984). "Effect of violation of normality on the t test of the correlation coefficient". Psychological Bulletin. 95 (3): 576–583. doi:10.1037/0033-2909.95.3.576.
External links
| Wikiversity has learning resources about t-test |
- "Student test", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- A conceptual article on the Student's t-test
- Econometrics lecture (topic: hypothesis testing) on YouTube by Mark Thoma
| General |
| ||||||
|---|---|---|---|---|---|---|---|
| Preventive healthcare | |||||||
| Population health | |||||||
| Biological and epidemiological statistics | |||||||
| Infectious and epidemic disease prevention | |||||||
| Food hygiene and safety management | |||||||
| Health behavioral sciences | |||||||
| Organizations, education and history |
| ||||||
| |||||||