Protein metabolism
Protein metabolism denotes the various biochemical processes responsible for the synthesis of proteins and amino acids (anabolism), and the breakdown of proteins by catabolism.
The steps of protein synthesis include transcription, translation, and post translational modifications. During transcription, RNA polymerase transcribes a coding region of the DNA in a cell producing a sequence of RNA, specifically messenger RNA (mRNA). This mRNA sequence contains codons: 3 nucleotide long segments that code for a specific amino acid. Ribosomes translate the codons to their respective amino acids.[1] In humans, non-essential amino acids are synthesized from intermediates in major metabolic pathways such as the Citric Acid Cycle.[2] Essential amino acids must be consumed and are made in other organisms. The amino acids are joined by peptide bonds making a polypeptide chain. This polypeptide chain then goes through post translational modifications and is sometimes joined with other polypeptide chains to form a fully functional protein.
Dietary proteins are first broken down to individual amino acids by various enzymes and hydrochloric acid present in the gastrointestinal tract. These amino acids are absorbed into the bloodstream to be transported to the liver and onward to the rest of the body. Absorbed amino acids are typically used to create functional proteins, but may also be used to create energy.[3]
Proteins can be broken down by enzymes known as peptidases or can break down as a result of denaturation. Proteins can denature in environmental conditions the protein is not made for.[4]
Protein synthesis
Protein anabolism is the process by which proteins are formed from amino acids. It relies on five processes: amino acid synthesis, transcription, translation, post translational modifications, and protein folding. Proteins are made from amino acids. In humans, some amino acids can be synthesized using already existing intermediates. These amino acids are known as non-essential amino acids. Essential amino acids require intermediates not present in the human body. These intermediates must be ingested, mostly from eating other organisms.[4]
Amino Acid Synthesis
| Amino Acid | R-group‡ | Pathway* |
| Glycine | H- | Serine + THF → Glycine (hydroxymethyltransferase) |
| Alanine | CH3- | Pyruvate → Alanine (aminotransferase) |
| Valine§ | (CH3)2-CH- | Hydroxyethyl-TPP + Pyruvate → α-acetolactate → Valine |
| Leucine§ | (CH3)2-CH-CH2- | Hydroxyethyl-TPP + Pyruvate → α-ketobutyrate → Leucine |
| Isoleucine§ | CH3-CH2-CH(CH3)- | Hydroxyethyl-TPP + Pyruvate → α-acetolactate → Isoleucine |
| Methionine§ | CH3-S-(CH2)2- | Homocysteine → Methionine (methionine synthase) |
| Proline | -(CH2)3- | Glutamic Acid → Glutamate-5-semialdehyde → Proline (γ-glutamyl kinase) |
| Phenylalanine§ | Ph-CH2- | Phosphoenolpyruvate → 2-keto-3-deoxy arabino heptulosonate-7-phosphate → Chorismate → Phenylalanine |
| Tryptophan§ | Ph-NH-CH=C-CH2- | Phosphoenolpyruvate → 2-keto-3-deoxy arabino heptulosonate-7-phosphate → Chorismate → Tryptophan |
| Tyrosine | HO-Ph-CH2- | Phenylalanine → Tyrosine (phenylalanine hydroxylase) |
| Serine | HO-CH2- | 3-phosphoglycerate → 3-phosphohydroxypyruvate (3-phosphoglycerate dehydrogenase) → 3-phosphoserine (aminotransferase) → Serine (phosphoserine phosphatase) |
| Threonine§ | CH3-CH(OH)- | Aspartate → β-aspartate-semialdehyde → Homoserine → Threonine |
| Cysteine | HS-CH2- | Serine → Cystathionine → α-ketobutyrate → Cysteine |
| Asparagine | H2N-CO-CH2- | Aspartic Acid → Asparagine (asparagine synthetase) |
| Glutamine | H2N-CO-(CH2)2- | Glutamic Acid → Glutamine (glutamine synthetase) |
| Arginine | +H2N=C(NH2)-NH-(CH2)3- | Glutamate → Glutamate-5-semialdehyde (γ-glutamyl kinase) → Arginine |
| Histidine§ | NH-CH=N-CH=C-CH2- | Glucose → Glucose-6-phosphate → Ribose-5-phosphate → Histidine |
| Lysine§ | +H3N-(CH2)4- | Aspartate → β-aspartate-semialdehyde → Homoserine + lysine |
| Aspartic Acid | −OOC-CH2- | Oxaloacetate → Aspartic Acid (aminotransferase) |
| Glutamic Acid | −OOC-(CH2)2- | α-ketoglutarate → Glutamic Acid (aminotransferase) |
| ‡Shown at physiological conditions.
*Complexes that are italicized are enzymes. §Cannot be synthesized in humans. | ||
Transcription
In transcription, RNA polymerase reads a DNA strand and produces an mRNA strand that can be further translated. In order to initiate transcription, the DNA segment that is to be transcribed must be accessible (i.e. it cannot be tightly packed). Once the DNA segment is accessible, the RNA polymerase can begin to transcribe the coding DNA strand by pairing RNA nucleotides to the template DNA strand. During the initial transcription phase, the RNA polymerase searches for a promoter region on the DNA template strand. Once the RNA polymerase binds to this region, it begins to “read” the template DNA strand in the 3’ to 5’ direction.[6] RNA polymerase attaches RNA bases complementary to the template DNA strand (Uracil will be used instead of Thymine). The new nucleotide bases are bonded to each other covalently.[7] The new bases eventually dissociate from the DNA bases but stay linked to each other, forming a new mRNA strand. This mRNA strand is synthesized in the 5’ to 3’ direction.[8] Once the RNA reaches a terminator sequence, it dissociates from the DNA template strand and terminates the mRNA sequence as well.
Transcription is regulated in the cell via transcription factors. Transcription factors are proteins that bind to regulatory sequences in the DNA strand such as promoter regions or operator regions. Proteins bound to these regions can either directly halt or allow RNA polymerase to read the DNA strand or can signal other proteins to halt or allow RNA polymerase reading.[9]
Translation
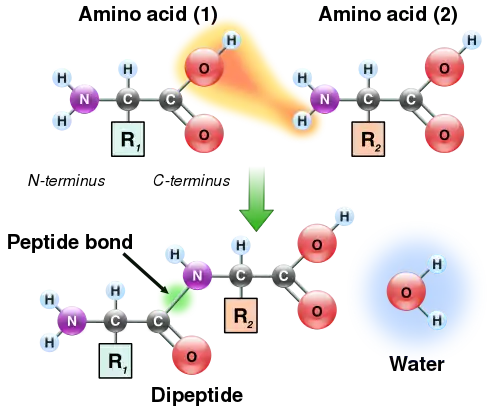
During translation, ribosomes convert a sequence of mRNA (messenger RNA) to an amino acid sequence. Each 3-base-pair-long segment of mRNA is a codon which corresponds to one amino acid or stop signal.[10] Amino acids can have multiple codons that correspond to them. Ribosomes do not directly attach amino acids to mRNA codons. They must utilize tRNAs (transfer RNAs) as well. Transfer RNAs can bind to amino acids and contain an anticodon which can hydrogen bind to an mRNA codon.[11] The process of bind an amino acid to a tRNA is known as tRNA charging. Here, the enzyme aminoacyl-tRNA-synthetase catalyzes two reactions. In the first one, it attaches an AMP molecule (cleaved from ATP) to the amino acid. The second reaction cleaves the aminoacyl-AMP producing the energy to join the amino acid to the tRNA molecule.[12]
Ribosomes have two subunits, one large and one small. These subunits surround the mRNA strand. The larger subunit contains three binding sites: A (aminoacyl), P (peptidyl), and E (exit). After translational initiation (which is different in prokaryotes and eukaryotes), the ribosome enters the elongation period which follows a repetitive cycle. First a tRNA with the correct amino acid enters the A site. The ribosome transfers the peptide from the tRNA in the P site to the new amino acid on the tRNA in the A site. The tRNA from the P site will be shifted into the E site where it will be ejected. This continually occurs until the ribosome reaches a stop codon or receives a signal to stop.[11] A peptide bond forms between the amino acid attached to the tRNA in the P site and the amino acid attached to a tRNA in the A site. The formation of a peptide bond requires an input of energy. The two reacting molecules are the alpha amino group of one amino acid and the alpha carboxyl group of the other amino acids. A by-product of this bond formation is the release of water (the amino group donates a proton while the carboxyl group donates a hydroxyl).[2]
Translation can be downregulated by miRNAs (microRNAs). These RNA strands can cleave mRNA strands they are complementary to and will thus stop translation.[13] Translation can also be regulated via helper proteins. For example, a protein called eukaryotic initiation factor-2 (eIF-2) can bind to the smaller subunit of the ribosome, starting translation. When elF-2 is phosphorylated, it cannot bind to the ribosome and translation is halted.[14]
Post-translational Modifications

Once the peptide chain is synthesized, it still must be modified. Post-translational modifications can occur before protein folding or after. Common biological methods of modifying peptide chains after translation include methylation, phosphorylation, and disulfide bond formation. Methylation often occurs to arginine or lysine and involves adding a methyl group to a nitrogen (replacing a hydrogen). The R groups on these amino acids can be methylated multiple times as long as the bonds to nitrogen does not exceed 4. Methylation reduces the ability of these amino acids to form hydrogen bonds so arginine and lysine that are methylated have different properties than their standard counterparts. Phosphorylation often occurs to serine, threonine, and tyrosine and involves replacing a hydrogen on the alcohol group at the terminus of the R group with a phosphate group. This adds a negative charge on the R groups and will thus change how the amino acids behave in comparison to their standard counterparts. Disulfide bond formation is the creation of disulfide bridges (covalent bonds) between two cysteine amino acids in a chain which adds stability to the folded structure.[15]
Protein folding
A polypeptide chain in the cell does not have to stay linear; it can become branched or fold in on itself. Polypeptide chains fold in a particular manner depending on the solution they are in. The fact that all amino acids contain R groups with different properties is the main reason proteins fold. In a hydrophilic environment such as cytosol, the hydrophobic amino acids will concentrate at the core of the protein, while the hydrophilic amino acids will be on the exterior. This is entropically favorable since water molecules can move much more freely around hydrophilic amino acids than hydrophobic amino acids. In a hydrophobic environment, the hydrophilic amino acids will concentrate at the core of the protein, while the hydrophobic amino acids will be on the exterior. Since the new interactions between the hydrophilic amino acids are stronger than hydrophobic-hydrophilic interactions, this is enthalpically favorable.[16] Once a polypeptide chain is fully folded, it is called a protein. Often many subunits will combine to make a fully functional protein although physiological proteins do exist that contain only one polypeptide chain. Proteins may also incorporate other molecules such as the heme group in hemoglobin, a protein responsible for carrying oxygen in the blood.[17]
Protein breakdown
Protein catabolism is the process by which proteins are broken down to their amino acids. This is also called proteolysis and can be followed by further amino acid degradation.
Proteases
Originally thought to only disrupt enzymatic reactions, proteases (also known as peptidases) actually help with catabolizing proteins through cleavage and creating new proteins that were not present before. Proteases also help to regulate metabolic pathways. One way they do this is to cleave enzymes in pathways that do not need to be running (i.e. gluconeogenesis when blood glucose concentrations are high). This helps to conserve as much energy as possible and to avoid futile cycles. Futile cycles occur when the catabolic and anabolic pathways are both in effect at the same time and rate for the same reaction. Since the intermediates being created are consumed, the body makes no net gain gains. Energy is lost through futile cycles. Proteases prevent this cycle from occurring by altering the rate of one of the pathways, or by cleaving a key enzyme, they can stop one of the pathways. Proteases are also nonspecific when binding to substrate, allowing for great amounts of diversity inside the cells and other proteins, as they can be cleaved much easier in an energy efficient manner.[18]
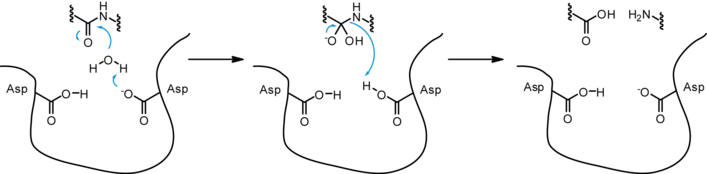
Because many proteases are nonspecific, they are highly regulated in the cell. Without regulation, proteases will destroy many essential proteins for physiological processes. One way the body regulates proteases is through protease inhibitors. Protease inhibitors can be other proteins, small peptides, or molecules. There are two types of protease inhibitors: reversible and irreversible. Reversible protease inhibitors form non-covalent interactions with the protease limiting its functionality. They can be competitive inhibitors, uncompetitive inhibitors, and noncompetitive inhibitors. Competitive inhibitors compete with the peptide to bind to the protease active site. Uncompetitive inhibitors bind to the protease while the peptide is bound but do not let the protease cleave the peptide bond. Noncompetitive inhibitors can do both. Irreversible protease inhibitors covalently modify the active site of the protease so it cannot cleave peptides.[19]
Exopeptidases
Exopeptidases are enzymes that can cleave the end of an amino acid side chain mostly through the addition of water.[4] Exopeptidase enzymes exist in the small intestine. These enzymes have two classes: aminopeptidases are a brush border enzyme and carboxypeptidases which is from the pancreas. Aminopeptidases are enzymes that remove amino acids from the amino terminus of protein. They are present in all lifeforms and are crucial for survival since they do many cellular tasks in order to maintain stability. This form of peptidase is a zinc metalloenzyme and it is inhibited by the transition state analog. This analog is similar to the actual transition state, so it can make the enzyme bind to it instead of the actual transition state, thus preventing substrate binding and decreasing reaction rates.[20] Carboxypeptidases cleave at the carboxyl end of the protein. While they can catabolize proteins, they are more often used in post-transcriptional modifications.[21]
Endopeptidases
Endopeptidases are enzymes that add water to an internal peptide bond in a peptide chain and break that bond.[4] Three common endopeptidases that come from the pancreas are pepsin, trypsin, and chymotrypsin. Chymotrypsin performs a hydrolysis reaction that cleaves after aromatic residues. The main amino acids involved are serine, histidine, and aspartic acid. They all play a role in cleaving the peptide bond. These three amino acids are known as the catalytic triad which means that these three must all be present in order to properly function.[4] Trypsin cleaves after long positively charged residues and has a negatively charged binding pocket at the active site. Both are produced as zymogens, meaning they are initially found in their inactive state and after cleavage though a hydrolysis reaction, they becomes activated.[2] Non-covalent interactions such as hydrogen bonding between the peptide backbone and the catalytic triad help increase reaction rates, allowing these peptidases to cleave many peptides efficiently.[4]
pH
Cellular proteins are held in a relatively constant pH in order to prevent changes in the protonation state of amino acids.[22] If the pH drops, some amino acids in the polypeptide chain can become protonated if the pka of their R groups is higher than the new pH. Protonation can change the charge these R groups have. If the pH raises, some amino acids in the chain can become deprotonated (if the pka of the R group is lower than the new pH). This also changes the R group charge. Since many amino acids interact with other amino acids based on electrostatic attraction, changing the charge can break these interactions. The loss of these interactions alters the proteins structure, but most importantly it alters the proteins function, which can be beneficial or detrimental. A significant change in pH may even disrupt many interactions the amino acids make and denature (unfold) the protein.[22]
Temperature
As the temperature in the environment increases, molecules move faster. Hydrogen bonds and hydrophobic interactions are important stabilizing forces in proteins. If the temperature rises and molecules containing these interactions are moving too fast, the interactions become compromised or even break. At high temperatures, these interactions cannot form, and a functional protein is denatured.[23] However, it relies on two factors; the type of protein used and the amount of heat applied. The amount of heat applied determines whether this change in protein is permanent or if it can be transformed back to its original form.[24]
References
- "Transcription, Translation and Replication". www.atdbio.com. Retrieved 2019-02-12.
- Berg JM, Tymoczko JL, Stryer L (2002). Biochemistry (5th ed.). New York: W.H. Freeman. ISBN 978-0716730514. OCLC 48055706.
- "Protein Metabolism". Encyclopedia.com. 7 October 2020.
- Voet D, Pratt CW, Voet JG (2013) [2012]. Fundamentals of biochemistry : life at the molecular level (4th ed.). Hoboken, NJ: John Wiley & Sons. pp. 712–765. ISBN 9780470547847. OCLC 782934336.
- "Amino Acid Synthesis". homepages.rpi.edu. Retrieved 2019-02-20.
- Brown TA (2002). Genomes (2nd ed.). Oxford: Bios. ISBN 978-1859962282. OCLC 50331286.
- "Chemistry for Biologists: Nucleic acids". www.rsc.org. Retrieved 2019-02-20.
- Griffiths AJ (2000). An introduction to genetic analysis (7th ed.). New York: W.H. Freeman. ISBN 978-0716735205. OCLC 42049331.
- Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P. Molecular biology of the cell (4th ed.). New York. ISBN 978-0815332183. OCLC 48122761.
- "National Human Genome Research Institute (NHGRI)". National Human Genome Research Institute (NHGRI). Retrieved 2019-02-20.
- Cooper GM (2000). The Cell: A Molecular Approach (2nd ed.). Washington, D.C.: ASM Press. ISBN 978-0878931194. OCLC 43708665.
- "MolGenT - tRNA Charging". halo.umbc.edu. Retrieved 2019-03-22.
- "miRNA (microRNA) Introduction". Sigma-Aldrich. Retrieved 2019-03-22.
- Kimball SR (January 1999). "Eukaryotic initiation factor eIF2". The International Journal of Biochemistry & Cell Biology. 31 (1): 25–9. doi:10.1016/S1357-2725(98)00128-9. PMID 10216940.
- Green KD, Garneau-Tsodikova S (2010). "Posttranslational Modification of Proteins". Comprehensive Natural Products II. Reference Module in Chemistry, Molecular Sciences and Chemical Engineering. 5. Elsevier. pp. 433–468. doi:10.1016/b978-008045382-8.00662-6. ISBN 9780080453828.
- Lodish HF (2000). Molecular cell biology (4th ed.). New York: W.H. Freeman. ISBN 978-0716731368. OCLC 41266312.
- "Heme". PubChem. Retrieved 2019-02-20.
- López-Otín C, Bond JS (November 2008). "Proteases: multifunctional enzymes in life and disease". The Journal of Biological Chemistry. 283 (45): 30433–7. doi:10.1074/jbc.R800035200. PMC 2576539. PMID 18650443.
- Geretti AM (2006). Antiretroviral resistance in clinical practice. London, England: Mediscript Ltd. ISBN 978-0955166907. OCLC 77517389.
- Taylor A (February 1993). "Aminopeptidases: structure and function". FASEB Journal. 7 (2): 290–8. doi:10.1096/fasebj.7.2.8440407. PMID 8440407.
- "Carboxypeptidase". www.chemistry.wustl.edu. Retrieved 2019-03-23.
- Nelson DL, Cox MM, Lehninger AL (2013). Lehninger principles of biochemistry (6th ed.). New York: W.H. Freeman and Company. OCLC 824794893.
- "Denaturation Protein". chemistry.elmhurst.edu. Retrieved 2019-02-20.
- Djikaev, Y. S.; Ruckenstein, Eli (2008). "Temperature effects on the nucleation mechanism of protein folding and on the barrierless thermal denaturation of a native protein". Physical Chemistry Chemical Physics. 10 (41): 6281–300. doi:10.1039/b807399f. ISSN 1463-9076. PMID 18936853.
Metabolism map | ||
|---|---|---|
Single lines: pathways common to most lifeforms. Double lines: pathways not in humans (occurs in e.g. plants, fungi, prokaryotes). | ||
.svg.png.webp)
