Han unification
Han unification is an effort by the authors of Unicode and the Universal Character Set to map multiple character sets of the Han characters of the so-called CJK languages into a single set of unified characters. Han characters are a feature shared in common by written Chinese (hanzi), Japanese (kanji), and Korean (hanja).

Modern Chinese, Japanese and Korean typefaces typically use regional or historical variants of a given Han character. In the formulation of Unicode, an attempt was made to unify these variants by considering them different glyphs representing the same "grapheme", or orthographic unit, hence, "Han unification", with the resulting character repertoire sometimes contracted to Unihan. Nevertheless, many characters have regional variants assigned to different code points, such as Traditional 個 (U+500B) versus Simplified 个 (U+4E2A).
Unihan can also refer to the Unihan Database maintained by the Unicode Consortium, which provides information about all of the unified Han characters encoded in the Unicode Standard, including mappings to various national and industry standards, indices into standard dictionaries, encoded variants, pronunciations in various languages, and an English definition. The database is available to the public as text files[1] and via an interactive website.[2][3] The latter also includes representative glyphs and definitions for compound words drawn from the free Japanese EDICT and Chinese CEDICT dictionary projects (which are provided for convenience and are not a formal part of the Unicode Standard).
Rationale and controversy
The Unicode Standard details the principles of Han unification.[4][5] The Ideographic Rapporteur Group (IRG), made up of experts from the Chinese-speaking countries, North and South Korea, Japan, Vietnam, and other countries, is responsible for the process.
One possible rationale is the desire to limit the size of the full Unicode character set, where CJK characters as represented by discrete ideograms may approach or exceed 100,000[lower-alpha 1] characters. Version 1 of Unicode was designed to fit into 16 bits and only 20,940 characters (32%) out of the possible 65,536 were reserved for these CJK Unified Ideographs. Unicode was later extended to 21 bits allowing many more CJK characters (92,856 are assigned, with room for more).
The article The secret life of Unicode, located on IBM DeveloperWorks attempts to illustrate part of the motivation for Han unification:
The problem stems from the fact that Unicode encodes characters rather than "glyphs," which are the visual representations of the characters. There are four basic traditions for East Asian character shapes: traditional Chinese, simplified Chinese, Japanese, and Korean. While the Han root character may be the same for CJK languages, the glyphs in common use for the same characters may not be. For example, the traditional Chinese glyph for "grass" uses four strokes for the "grass" radical [⺿], whereas the simplified Chinese, Japanese, and Korean glyphs [⺾] use three. But there is only one Unicode point for the grass character (U+8349) [草] regardless of writing system. Another example is the ideograph for "one," which is different in Chinese, Japanese, and Korean. Many people think that the three versions should be encoded differently.
In fact, the three ideographs for "one" (一, 壹, or 壱) are encoded separately in Unicode, as they are not considered national variants. The first is the common form in all three countries, while the second and third are used on financial instruments to prevent tampering (they may be considered variants).
However, Han unification has also caused considerable controversy, particularly among the Japanese public, who, with the nation's literati, have a history of protesting the culling of historically and culturally significant variants.[6][7] (See Kanji § Orthographic reform and lists of kanji. Today, the list of characters officially recognized for use in proper names continues to expand at a modest pace.)
In 1993, the Japan Electronic Industries Development Association (JEIDA) published a pamphlet titled "未来の文字コード体系に私達は不安をもっています" (We are feeling anxious for the future character encoding system JPNO 20985671), summarizing major criticism against the Han Unification approach adopted by Unicode.
Graphemes versus glyphs
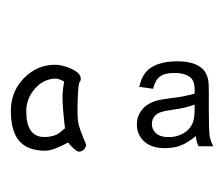
A grapheme is the smallest abstract unit of meaning in a writing system. Any grapheme has many possible glyph expressions, but all are recognized as the same grapheme by those with reading and writing knowledge of a particular writing system. Although Unicode typically assigns characters to code points to express the graphemes within a system of writing, the Unicode Standard (section 3.4 D7) does with caution:
An abstract character does not necessarily correspond to what a user thinks of as a "character" and should not be confused with a grapheme.
However, this quote refers to the fact that some graphemes are composed of several characters. So, for example, the character U+0061 a LATIN SMALL LETTER A combined with U+030A ◌̊ COMBINING RING ABOVE (i.e. the combination "å") might be understood by a user as a single grapheme while being composed of multiple Unicode abstract characters. In addition, Unicode also assigns some code points to a small number (other than for compatibility reasons) of formatting characters, whitespace characters, and other abstract characters that are not graphemes, but instead used to control the breaks between lines, words, graphemes and grapheme clusters. With the unified Han ideographs, the Unicode Standard makes a departure from prior practices in assigning abstract characters not as graphemes, but according to the underlying meaning of the grapheme: what linguists sometimes call sememes. This departure therefore is not simply explained by the oft quoted distinction between an abstract character and a glyph, but is more rooted in the difference between an abstract character assigned as a grapheme and an abstract character assigned as a sememe. In contrast, consider ASCII's unification of punctuation and diacritics, where graphemes with widely different meanings (for example, an apostrophe and a single quotation mark) are unified because the glyphs are the same. For Unihan the characters are not unified by their appearance, but by their definition or meaning.
For a grapheme to be represented by various glyphs means that the grapheme has glyph variations that are usually determined by selecting one font or another or using glyph substitution features where multiple glyphs are included in a single font. Such glyph variations are considered by Unicode a feature of rich text protocols and not properly handled by the plain text goals of Unicode. However, when the change from one glyph to another constitutes a change from one grapheme to another—where a glyph cannot possibly still, for example, mean the same grapheme understood as the small letter "a"—Unicode separates those into separate code points. For Unihan the same thing is done whenever the abstract meaning changes, however rather than speaking of the abstract meaning of a grapheme (the letter "a"), the unification of Han ideographs assigns a new code point for each different meaning—even if that meaning is expressed by distinct graphemes in different languages. Although a grapheme such as "ö" might mean something different in English (as used in the word "coördinated") than it does in German, it is still the same grapheme and can be easily unified so that English and German can share a common abstract Latin writing system (along with Latin itself). This example also points to another reason that "abstract character" and grapheme as an abstract unit in a written language do not necessarily map one-to-one. In English the combining diaeresis, "¨", and the "o" it modifies may be seen as two separate graphemes, whereas in languages such as Swedish, the letter "ö" may be seen as a single grapheme. Similarly in English the dot on an "i" is understood as a part of the "i" grapheme whereas in other languages, such as Turkish, the dot may be seen as a separate grapheme added to the dotless "ı".
To deal with the use of different graphemes for the same Unihan sememe, Unicode has relied on several mechanisms: especially as it relates to rendering text. One has been to treat it as simply a font issue so that different fonts might be used to render Chinese, Japanese or Korean. Also font formats such as OpenType allow for the mapping of alternate glyphs according to language so that a text rendering system can look to the user's environmental settings to determine which glyph to use. The problem with these approaches is that they fail to meet the goals of Unicode to define a consistent way of encoding multilingual text.[8]
So rather than treat the issue as a rich text problem of glyph alternates, Unicode added the concept of variation selectors, first introduced in version 3.2 and supplemented in version 4.0.[9] While variation selectors are treated as combining characters, they have no associated diacritic or mark. Instead, by combining with a base character, they signal the two character sequence selects a variation (typically in terms of grapheme, but also in terms of underlying meaning as in the case of a location name or other proper noun) of the base character. This then is not a selection of an alternate glyph, but the selection of a grapheme variation or a variation of the base abstract character. Such a two-character sequence however can be easily mapped to a separate single glyph in modern fonts. Since Unicode has assigned 256 separate variation selectors, it is capable of assigning 256 variations for any Han ideograph. Such variations can be specific to one language or another and enable the encoding of plain text that includes such grapheme variations.
Unihan "abstract characters"
Since the Unihan standard encodes "abstract characters", not "glyphs", the graphical artifacts produced by Unicode have been considered temporary technical hurdles, and at most, cosmetic. However, again, particularly in Japan, due in part to the way in which Chinese characters were incorporated into Japanese writing systems historically, the inability to specify a particular variant was considered a significant obstacle to the use of Unicode in scholarly work. For example, the unification of "grass" (explained above), means that a historical text cannot be encoded so as to preserve its peculiar orthography. Instead, for example, the scholar would be required to locate the desired glyph in a specific typeface in order to convey the text as written, defeating the purpose of a unified character set. Unicode has responded to these needs by assigning variation selectors so that authors can select grapheme variations of particular ideographs (or even other characters).[9]
Small differences in graphical representation are also problematic when they affect legibility or belong to the wrong cultural tradition. Besides making some Unicode fonts unusable for texts involving multiple "Unihan languages", names or other orthographically sensitive terminology might be displayed incorrectly. (Proper names tend to be especially orthographically conservative—compare this to changing the spelling of one's name to suit a language reform in the US or UK.) While this may be considered primarily a graphical representation or rendering problem to be overcome by more artful fonts, the widespread use of Unicode would make it difficult to preserve such distinctions. The problem of one character representing semantically different concepts is also present in the Latin part of Unicode. The Unicode character for an apostrophe is the same as the character for a right single quote (’). On the other hand, the capital Latin letter A is not unified with the Greek letter Α or the Cyrillic letter А. This is, of course, desirable for reasons of compatibility, and deals with a much smaller alphabetic character set.
While the unification aspect of Unicode is controversial in some quarters for the reasons given above, Unicode itself does now encode a vast number of seldom-used characters of a more-or-less antiquarian nature.
Some of the controversy stems from the fact that the very decision of performing Han unification was made by the initial Unicode Consortium, which at the time was a consortium of North American companies and organizations (most of them in California),[10] but included no East Asian government representatives. The initial design goal was to create a 16-bit standard,[11] and Han unification was therefore a critical step for avoiding tens of thousands of character duplications. This 16-bit requirement was later abandoned, making the size of the character set less of an issue today.
The controversy later extended to the internationally representative ISO: the initial CJK Joint Research Group (CJK-JRG) favored a proposal (DIS 10646) for a non-unified character set, "which was thrown out in favor of unification with the Unicode Consortium's unified character set by the votes of American and European ISO members" (even though the Japanese position was unclear).[12] Endorsing the Unicode Han unification was a necessary step for the heated ISO 10646/Unicode merger.
Much of the controversy surrounding Han unification is based on the distinction between glyphs, as defined in Unicode, and the related but distinct idea of graphemes. Unicode assigns abstract characters (graphemes), as opposed to glyphs, which are a particular visual representations of a character in a specific typeface. One character may be represented by many distinct glyphs, for example a "g" or an "a", both of which may have one loop (ɑ, ɡ) or two (a, g). Yet for a reader of Latin script based languages the two variations of the "a" character are both recognized as the same grapheme. Graphemes present in national character code standards have been added to Unicode, as required by Unicode's Source Separation rule, even where they can be composed of characters already available. The national character code standards existing in CJK languages are considerably more involved, given the technological limitations under which they evolved, and so the official CJK participants in Han unification may well have been amenable to reform.
Unlike European versions, CJK Unicode fonts, due to Han unification, have large but irregular patterns of overlap, requiring language-specific fonts. Unfortunately, language-specific fonts also make it difficult to access a variant which, as with the "grass" example, happens to appear more typically in another language style. (That is to say, it would be difficult to access "grass" with the four-stroke radical more typical of Traditional Chinese in a Japanese environment, which fonts would typically depict the three-stroke radical.) Unihan proponents tend to favor markup languages for defining language strings, but this would not ensure the use of a specific variant in the case given, only the language-specific font more likely to depict a character as that variant. (At this point, merely stylistic differences do enter in, as a selection of Japanese and Chinese fonts are not likely to be visually compatible.)
Chinese users seem to have fewer objections to Han unification, largely because Unicode did not attempt to unify Simplified Chinese characters with Traditional Chinese characters. (Simplified Chinese characters are used among Chinese speakers in the People's Republic of China, Singapore, and Malaysia. Traditional Chinese characters are used in Hong Kong and Taiwan (Big5) and they are, with some differences, more familiar to Korean and Japanese users.) Unicode is seen as neutral with regards to this politically charged issue, and has encoded Simplified and Traditional Chinese glyphs separately (e.g. the ideograph for "discard" is 丟 U+4E1F for Traditional Chinese Big5 #A5E1 and 丢 U+4E22 for Simplified Chinese GB #2210). It is also noted that Traditional and Simplified characters should be encoded separately according to Unicode Han Unification rules, because they are distinguished in pre-existing PRC character sets. Furthermore, as with other variants, Traditional to Simplified characters is not a one-to-one relationship.
Alternatives
There are several alternative character sets that are not encoding according to the principle of Han Unification, and thus free from its restrictions:
These region-dependent character sets are also seen as not affected by Han Unification because of their region-specific nature:
- ISO/IEC 2022 (based on sequence codes to switch between Chinese, Japanese, Korean character sets – hence without unification)
- Big5 extensions
- GCCS and its successor HKSCS
However, none of these alternative standards has been as widely adopted as Unicode, which is now the base character set for many new standards and protocols, internationally adopted, and is built into the architecture of operating systems (Microsoft Windows, Apple macOS, and many Unix-like systems), programming languages (Perl, Python, C#, Java, Common Lisp, APL, C, C++), and libraries (IBM International Components for Unicode (ICU) along with the Pango, Graphite, Scribe, Uniscribe, and ATSUI rendering engines), font formats (TrueType and OpenType) and so on.
In March 1989, a (B)TRON-based system was adopted by Japanese government organizations "Center for Educational Computing" as the system of choice for school education including compulsory education.[13] However, in April, a report titled "1989 National Trade Estimate Report on Foreign Trade Barriers" from Office of the United States Trade Representative have specifically listed the system as a trade barrier in Japan. The report claimed that the adoption of the TRON-based system by the Japanese government is advantageous to Japanese manufacturers, and thus excluding US operating systems from the huge new market; specifically the report lists MS-DOS, OS/2 and UNIX as examples. The Office of USTR was allegedly under Microsoft's influence as its former officer Tom Robertson was then offered a lucrative position by Microsoft.[14] While the TRON system itself was subsequently removed from the list of sanction by Section 301 of the Trade Act of 1974 after protests by the organization in May 1989, the trade dispute caused the Ministry of International Trade and Industry to accept a request from Masayoshi Son to cancel the Center of Educational Computing's selection of the TRON-based system for the use of educational computers.[15] The incident is regarded as a symbolic event for the loss of momentum and eventual demise of the BTRON system, which led to the widespread adoption of MS-DOS in Japan and the eventual adoption of Unicode with its successor Windows.
Merger of all equivalent characters
There has not been any push for full semantic unification of all semantically-linked characters, though the idea would treat the respective users of East Asian languages the same, whether they write in Korean, Simplified Chinese, Traditional Chinese, Kyūjitai Japanese, Shinjitai Japanese or Vietnamese. Instead of some variants getting distinct code points while other groups of variants have to share single code points, all variants could be reliably expressed only with metadata tags (e.g., CSS formatting in webpages). The burden would be on all those who use differing versions of 直, 別, 兩, 兔, whether that difference be due to simplification, international variance or intra-national variance. However, for some platforms (e.g., smartphones), a device may come with only one font pre-installed. The system font must make a decision for the default glyph for each code point and these glyphs can differ greatly, indicating different underlying graphemes.
Consequently, relying on language markup across the board as an approach is beset with two major issues. First, there are contexts where language markup is not available (code commits, plain text). Second, any solution would require every operating system to come pre-installed with many glyphs for semantically identical characters that have many variants. In addition to the standard character sets in Simplified Chinese, Traditional Chinese, Korean, Vietnamese, Kyūjitai Japanese and Shinjitai Japanese, there also exist "ancient" forms of characters that are of interest to historians, linguists and philologists.
Unicode's Unihan database has already drawn connections between many characters. The Unicode database catalogs the connections between variant characters with distinct code points already. However, for characters with a shared code point, the reference glyph image is usually biased toward the Traditional Chinese version. Also, the decision of whether to classify pairs as semantic variants or z-variants is not always consistent or clear, despite rationalizations in the handbook.[16]
So-called semantic variants of 丟 (U+4E1F) and 丢 (U+4E22) are examples that Unicode gives as differing in a significant way in their abstract shapes, while Unicode lists 佛 and 仏 as z-variants, differing only in font styling. Paradoxically, Unicode considers 兩 and 両 to be near identical z-variants while at the same time classifying them as significantly different semantic variants. There are also cases of some pairs of characters being simultaneously semantic variants and specialized semantic variants and simplified variants: 個 (U+500B) and 个 (U+4E2A). There are cases of non-mutual equivalence. For example, the Unihan database entry for 亀 (U+4E80) considers 龜 (U+9F9C) to be its z-variant, but the entry for 龜 does not list 亀 as a z-variant, even though 龜 was obviously already in the database at the time that the entry for 亀 was written.
Some clerical errors led to doubling of completely identical characters such as 﨣 (U+FA23) and 𧺯 (U+27EAF). If a font has glyphs encoded to both points so that one font is used for both, they should appear identical. These cases are listed as z-variants despite having no variance at all. Intentionally duplicated characters were added to facilitate bit-for-bit round-trip conversion. Because round-trip conversion was an early selling point of Unicode, this meant that if a national standard in use unnecessarily duplicated a character, Unicode had to do the same. Unicode calls these intentional duplications "compatibility variants" as with 漢 (U+FA9A) which calls 漢 (U+6F22) its compatibility variant. As long as an application uses the same font for both, they should appear identical. Sometimes, as in the case of 車 with U+8ECA and U+F902, the added compatibility character lists the already present version of 車 as both its compatibility variant and its z-variant. The compatibility variant field overrides the z-variant field, forcing normalization under all forms, including canonical equivalence. Despite the name, compatibility variants are actually canonically equivalent and are united in any Unicode normalization scheme and not only under compatibility normalization. This is similar to how U+212B Å ANGSTROM SIGN is canonically equivalent to a pre-composed U+00C5 Å LATIN CAPITAL LETTER A WITH RING ABOVE. Much software (such as the MediaWiki software that hosts Wikipedia) will replace all canonically equivalent characters that are discouraged (e.g. the angstrom symbol) with the recommended equivalent. Despite the name, CJK "compatibility variants" are canonically equivalent characters and not compatibility characters.
漢 (U+FA9A) was added to the database later than 漢 (U+6F22) was and its entry informs the user of the compatibility information. On the other hand, 漢 (U+6F22) does not have this equivalence listed in this entry. Unicode demands that all entries, once admitted, cannot change compatibility or equivalence so that normalization rules for already existing characters do not change.
Some pairs of Traditional and Simplified are also considered to be semantic variants. According to Unicode's definitions, it makes sense that all simplifications (that do not result in wholly different characters being merged for their homophony) will be a form of semantic variant. Unicode classifies 丟 and 丢 as each other's respective traditional and simplified variants and also as each other's semantic variants. However, while Unicode classifies 億 (U+5104) and 亿 (U+4EBF) as each other's respective traditional and simplified variants, Unicode does not consider 億 and 亿 to be semantic variants of each other.
Unicode claims that "Ideally, there would be no pairs of z-variants in the Unicode Standard."[16] This would make it seem that the goal is to at least unify all minor variants, compatibility redundancies and accidental redundancies, leaving the differentiation to fonts and to language tags. This conflicts with the stated goal of Unicode to take away that overhead, and to allow any number of any of the world's scripts to be on the same document with one encoding system. Chapter One of the handbook states that "With Unicode, the information technology industry has replaced proliferating character sets with data stability, global interoperability and data interchange, simplified software, and reduced development costs. While taking the ASCII character set as its starting point, the Unicode Standard goes far beyond ASCII's limited ability to encode only the upper- and lowercase letters A through Z. It provides the capacity to encode all characters used for the written languages of the world – more than 1 million characters can be encoded. No escape sequence or control code is required to specify any character in any language. The Unicode character encoding treats alphabetic characters, ideographic characters, and symbols equivalently, which means they can be used in any mixture and with equal facility."[8]
That leaves us with settling on one unified reference grapheme for all z-variants, which is contentious since few outside of Japan would recognize 佛 and 仏 as equivalent. Even within Japan, the variants are on different sides of a major simplification called Shinjitai. Unicode would effectively make the PRC's simplification of 侣 (U+4FA3) and 侶 (U+4FB6) a monumental difference by comparison. Such a plan would also eliminate the very visually distinct variations for characters like 直 (U+76F4) and 雇 (U+96C7).
One would expect that all simplified characters would simultaneously also be z-variants or semantic variants with their traditional counterparts, but many are neither. It is easier to explain the strange case that semantic variants can be simultaneously both semantic variants and specialized variants when Unicode's definition is that specialized semantic variants have the same meaning only in certain contexts. Languages use them differently. A pair whose characters are 100% drop-in replacements for each other in Japanese may not be so flexible in Chinese. Thus, any comprehensive merger of recommended code points would have to maintain some variants that differ only slightly in appearance even if the meaning is 100% the same for all contexts in one language, because in another language the two characters may not be 100% drop-in replacements.
Examples of language-dependent glyphs
In each row of the following table, the same character is repeated in all six columns. However, each column is marked (by the lang attribute) as being in a different language: Chinese (simplified and two types of traditional), Japanese, Korean, or Vietnamese. The browser should select, for each character, a glyph (from a font) suitable to the specified language. (Besides actual character variation—look for differences in stroke order, number, or direction—the typefaces may also reflect different typographical styles, as with serif and non-serif alphabets.) This only works for fallback glyph selection if you have CJK fonts installed on your system and the font selected to display this article does not include glyphs for these characters.
| Code point | Chinese (simplified) ( zh-Hans) |
Chinese (traditional) ( zh-Hant) |
Chinese (traditional, Hong Kong) ( zh-Hant-HK) |
Japanese ( ja) |
Korean ( ko) |
Vietnamese ( vi-Hani) |
English |
|---|---|---|---|---|---|---|---|
| U+4ECA | 今 | 今 | 今 | 今 | 今 | 今 | now |
| U+4EE4 | 令 | 令 | 令 | 令 | 令 | 令 | cause/command |
| U+514D | 免 | 免 | 免 | 免 | 免 | 免 | exempt/spare |
| U+5165 | 入 | 入 | 入 | 入 | 入 | 入 | enter |
| U+5168 | 全 | 全 | 全 | 全 | 全 | 全 | all/total |
| U+5173 | 关 | 关 | 关 | 关 | 关 | 关 | close (simplified) / laugh (traditional) |
| U+5177 | 具 | 具 | 具 | 具 | 具 | 具 | tool |
| U+5203 | 刃 | 刃 | 刃 | 刃 | 刃 | 刃 | knife edge |
| U+5316 | 化 | 化 | 化 | 化 | 化 | 化 | transform/change |
| U+5916 | 外 | 外 | 外 | 外 | 外 | 外 | outside |
| U+60C5 | 情 | 情 | 情 | 情 | 情 | 情 | feeling |
| U+624D | 才 | 才 | 才 | 才 | 才 | 才 | talent |
| U+62B5 | 抵 | 抵 | 抵 | 抵 | 抵 | 抵 | arrive/resist |
| U+6B21 | 次 | 次 | 次 | 次 | 次 | 次 | secondary/follow |
| U+6D77 | 海 | 海 | 海 | 海 | 海 | 海 | sea |
| U+76F4 | 直 | 直 | 直 | 直 | 直 | 直 | direct/straight |
| U+771F | 真 | 真 | 真 | 真 | 真 | 真 | true |
| U+793a | 示 | 示 | 示 | 示 | 示 | 示 | show |
| U+795E | 神 | 神 | 神 | 神 | 神 | 神 | god |
| U+7A7A | 空 | 空 | 空 | 空 | 空 | 空 | empty/air |
| U+8005 | 者 | 者 | 者 | 者 | 者 | 者 | one who does/-ist/-er |
| U+8349 | 草 | 草 | 草 | 草 | 草 | 草 | grass |
| U+8525 | 蔥 | 蔥 | 蔥 | 蔥 | 蔥 | 蔥 | onion |
| U+89D2 | 角 | 角 | 角 | 角 | 角 | 角 | edge/horn |
| U+9053 | 道 | 道 | 道 | 道 | 道 | 道 | way/path/road |
| U+96C7 | 雇 | 雇 | 雇 | 雇 | 雇 | 雇 | employ |
| U+9AA8 | 骨 | 骨 | 骨 | 骨 | 骨 | 骨 | bone |
No character variant that is exclusive to Korean or Vietnamese has received its own code point, whereas almost all Shinjitai Japanese variants or Simplified Chinese variants each have distinct code points and unambiguous reference glyphs in the Unicode standard.
In the twentieth century, East Asian countries made their own respective encoding standards. Within each standard, there coexisted variants with distinct code points, hence the distinct code points in Unicode for certain sets of variants. Taking Simplified Chinese as an example, the two character variants of 內 (U+5167) and 内 (U+5185) differ in exactly the same way as do the Korean and non-Korean variants of 全 (U+5168). Each respective variant of the first character has either 入 (U+5165) or 人 (U+4EBA). Each respective variant of the second character has either 入 (U+5165) or 人 (U+4EBA). Both variants of the first character got their own distinct code points. However, the two variants of the second character had to share the same code point.
The justification Unicode gives is that the national standards body in the PRC made distinct code points for the two variations of the first character 內/内, whereas Korea never made separate code points for the different variants of 全. There is a reason for this that has nothing to do with how the domestic bodies view the characters themselves. China went through a process in the twentieth century that changed (if not simplified) several characters. During this transition, there was a need to be able to encode both variants within the same document. Korean has always used the variant of 全 with the 入 (U+5165) radical on top. Therefore, it had no reason to encode both variants. Korean language documents made in the twentieth century had little reason to represent both versions in the same document.
Almost all of the variants that the PRC developed or standardized got distinct code points owing simply to the fortune of the Simplified Chinese transition carrying through into the computing age. This privilege however, seems to apply inconsistently, whereas most simplifications performed in Japan and mainland China with code points in national standards, including characters simplified differently in each country, did make it into Unicode as distinct code points.
Sixty-two Shinjitai "simplified" characters with distinct code points in Japan got merged with their Kyūjitai traditional equivalents, like 海. This can cause problems for the language tagging strategy. There is no universal tag for the traditional and "simplified" versions of Japanese as there are for Chinese. Thus, any Japanese writer wanting to display the Kyūjitai form of 海 may have to tag the character as "Traditional Chinese" or trust that the recipient's Japanese font uses only the Kyūjitai glyphs, but tags of Traditional Chinese and Simplified Chinese may be necessary to show the two forms side by side in a Japanese textbook. This would preclude one from using the same font for an entire document, however. There are two distinct code points for 海 in Unicode, but only for "compatibility reasons". Any Unicode-conformant font must display the Kyūjitai and Shinjitai versions' equivalent code points in Unicode as the same. Unofficially, a font may display 海 differently with 海 (U+6D77) as the Shinjitai version and 海 (U+FA45) as the Kyūjitai version (which is identical to the traditional version in written Chinese and Korean).
The radical 糸 (U+7CF8) is used in characters like 紅/红, with two variants, the second form being simply the cursive form. The radical components of 紅 (U+7D05) and 红 (U+7EA2) are semantically identical and the glyphs differ only in the latter using a cursive version of the 糸 component. However, in mainland China, the standards bodies wanted to standardize the cursive form when used in characters like 红. Because this change happened relatively recently, there was a transition period. Both 紅 (U+7D05) and 红 (U+7EA2) got separate code points in the PRC's text encoding standards bodies so Chinese-language documents could use both version. The two variants received distinct code points in Unicode as well.
The case of the radical 艸 (U+8278) proves how arbitrary the state of affairs is. When used to compose characters like 草 (U+8349), the radical was placed at the top, but had two different forms. Traditional Chinese and Korean use a four-stroke version. At the top of 草 should be something that looks like two plus signs (⺿). Simplified Chinese, Kyūjitai Japanese and Shinjitai Japanese use a three-stroke version, like two plus signs sharing their horizontal strokes (⺾, i.e. 草). The PRC's text encoding bodies did not encode the two variants differently. The fact that almost every other change brought about by the PRC, no matter how minor, did warrant its own code point suggests that this exception may have been unintentional. Unicode copied the existing standards as is, preserving such irregularities.
The Unicode Consortium has recognized errors in other instances. The myriad Unicode blocks for CJK Han Ideographs have redundancies in original standards, redundancies brought about by flawed importation of the original standards, as well as accidental mergers that are later corrected, providing precedent for dis-unifying characters.
For native speakers, variants can be unintelligible or be unacceptable in educated contexts. English speakers may understand a handwritten note saying "4P5 kg" as "495 kg", but writing the nine backwards (so it looks like a "P") can be jarring and would be considered incorrect in any school. Likewise, to users of one CJK language reading a document with "foreign" glyphs: variants of 骨 can appear as mirror images, 者 can be missing a stroke/have an extraneous stroke, and 令 may be unreadable or be confused with 今 depending on which variant of 令 (e.g. 令) is used.
Examples of some non-unified Han ideographs
For more striking variants, Unicode has encoded variant characters, making it unnecessary to switch between fonts or lang attributes. In the following table, each row compares variants that have been assigned different code points.[2] Note that for characters such as 入 (U+5165), the only way to display the two variants is to change font (or lang attribute) as described in the previous table. However, for 內 (U+5167), there is an alternate character 内 (U+5185) as illustrated below. For some characters, like 兌/兑 (U+514C/U+5151), either method can be used to display the different glyphs.
| Simplified | Traditional | Japanese | Other variant | English |
|---|---|---|---|---|
| U+4E22 丢 |
U+4E1F 丟 |
to lose | ||
| U+4E24 两 |
U+5169 兩 |
U+4E21 両 |
U+34B3 㒳 |
two, both |
| U+4E58 乘 |
U+4E57 乗 |
U+6909 椉 |
to ride | |
| U+4EA7 产 |
U+7522 產 |
U+7523 産 |
give birth | |
| U+4FA3 侣 |
U+4FB6 侶 |
companion | ||
| U+5151 兑 |
U+514C 兌 |
to cash | ||
| U+5185 内 |
U+5167 內 |
inside | ||
| U+522B 别 |
U+5225 別 |
to leave | ||
| U+7985 禅 |
U+79AA 禪 |
U+7985 禅 |
meditation (Zen) | |
| U+7A0E 税 |
U+7A05 稅 |
taxes | ||
| U+7EA2 红 |
U+7D05 紅 |
red | ||
| U+7EAA 纪 |
U+7D00 紀 |
discipline | ||
| U+997F 饿 |
U+9913 餓 |
hungry | ||
| U+9AD8 高 |
U+9AD9 髙 |
high | ||
| U+9F9F 龟 |
U+9F9C 龜 |
U+4E80 亀 |
tortoise | |
| Sources: MDBG Chinese-English Dictionary | ||||
Ideographic Variation Database (IVD)
In order to resolve issues brought by Han unification, a Unicode Technical Standard known as the Unicode Ideographic Variation Database have been created to resolve the problem of specifying specific glyph in plain text environment.[17] By registering glyph collections into the Ideographic Variation Database (IVD), it is possible to use Ideographic Variation Selectors to form Ideographic Variation Sequence (IVS) to specify or restrict the appropriate glyph in text processing in a Unicode environment.
Unicode ranges
Ideographic characters assigned by Unicode appear in the following blocks:
- CJK Unified Ideographs (4E00–9FFF) (Otherwise known as URO, abbreviation of Unified Repertoire and Ordering)[18]
- CJK Unified Ideographs Extension A (3400–4DBF)
- CJK Unified Ideographs Extension B (20000–2A6DF)
- CJK Unified Ideographs Extension C (2A700–2B73F)
- CJK Unified Ideographs Extension D (2B740–2B81F)
- CJK Unified Ideographs Extension E (2B820–2CEAF)
- CJK Unified Ideographs Extension F (2CEB0–2EBEF)
- CJK Unified Ideographs Extension G (30000–3134F)
- CJK Compatibility Ideographs (F900–FAFF) (the twelve characters at FA0E, FA0F, FA11, FA13, FA14, FA1F, FA21, FA23, FA24, FA27, FA28 and FA29 are actually "unified ideographs" not "compatibility ideographs")
Unicode includes support of CJKV radicals, strokes, punctuation, marks and symbols in the following blocks:
- CJK Radicals Supplement (2E80–2EFF)
- CJK Strokes (31C0–31EF)
- CJK Symbols and Punctuation (3000–303F)
- Ideographic Description Characters (2FF0–2FFF)
Additional compatibility (discouraged use) characters appear in these blocks:
- CJK Compatibility (3300–33FF)
- CJK Compatibility Forms (FE30–FE4F)
- CJK Compatibility Ideographs (F900–FAFF)
- CJK Compatibility Ideographs Supplement (2F800–2FA1F)
- Enclosed CJK Letters and Months (3200–32FF)
- Enclosed Ideographic Supplement (1F200–1F2FF)
- Kangxi Radicals (2F00–2FDF)
These compatibility characters (excluding the twelve unified ideographs in the CJK Compatibility Ideographs block) are included for compatibility with legacy text handling systems and other legacy character sets. They include forms of characters for vertical text layout and rich text characters that Unicode recommends handling through other means.
International Ideographs Core
The International Ideographs Core (IICore) is a subset of 9810 ideographs derived from the CJK Unified Ideographs tables, designed to be implemented in devices with limited memory, input/output capability, and/or applications where the use of the complete ISO 10646 ideograph repertoire is not feasible. There are 9810 characters in the current standard.[19]
Unihan database files
The Unihan project has always made an effort to make available their build database.[1]
The libUnihan project provides a normalized SQLite Unihan database and corresponding C library.[20] All tables in this database are in fifth normal form. libUnihan is released under the LGPL, while its database, UnihanDb, is released under the MIT License.
See also
Notes
- Most of these are legacy and obsolete characters, however, as per Unicode's objective to encode every writing system that is or has ever been used; only 2000 to 3000 characters are necessary to be considered literate.
References
- "Unihan.zip". The Unicode Standard. Unicode Consortium.
- "Unihan Database Lookup". The Unicode Standard. Unicode Consortium.
- "Unihan Database Lookup: Sample lookup for 中". The Unicode Standard. Unicode Consortium.
- "Chapter 18: East Asia, Principles of Han Unification" (PDF). The Unicode Standard. Unicode Consortium.
- Whistler, Ken (2010-10-25). "Unicode Technical Note 26: On the Encoding of Latin, Greek, Cyrillic, and Han".
- Unicode Revisited Steven J. Searle; Web Master, TRON Web
- "IVD/IVSとは - 文字情報基盤整備事業". mojikiban.ipa.go.jp.
- "Chapter 1: Introduction" (PDF). The Unicode Standard. Unicode Consortium.
- "Ideographic Variation Database". Unicode Consortium.
- "Early Years of Unicode". Unicode Consortium.
- Becker, Joseph D. (1998-08-29). "Unicode 88" (PDF).
- "Unicode in Japan: Guide to a technical and psychological struggle". Archived from the original on 2009-06-27.CS1 maint: bot: original URL status unknown (link)
- 小林紀興『松下電器の果し状』1章
- Krikke, Jan. "The Most Popular Operating System in the World". LinuxInsider.com.
- 大下英治 『孫正義 起業の若き獅子』(ISBN 4-06-208718-9)pp. 285-294
- "UAX #38: Unicode Han Database (Unihan)". www.unicode.org.
- "UTS #37: Unicode Ideographic Variation Database". www.unicode.org.
- "URO". blogs.adobe.com.
- "OGCIO : Download Area : International Ideographs Core (IICORE) Comparison Utility". www.ogcio.gov.hk.
- (陳定彞), Ding-Yi Chen. "libUnihan - A library for Unihan character database in fifth normal form". libunihan.sourceforge.net.
| Early telecommunications |
|
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards |
|
| ISO/IEC 2022 | |
| Mac OS code pages ("scripts") |
|
| DOS code pages |
|
| IBM AIX code pages | |
| IBM code pages for other vendors' encodings | |
| Windows code pages |
|
| Microsoft code pages for other vendors' encodings | |
| EBCDIC code pages |
|
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control and nonprinting character sets |
|
| Related topics | |